阿里云人工智能ACA认证(3)—数据处理基础
2025-04
浏览量:502
本文字数:2578
读完约 9 分钟
一、数据采集
字段类型分类:
文本类
时间类
数值类
数据结构类型分析:
结构化数据:数据库中的数据
非结构化数据:TXT、WORD
半结构化数据:XML、JSON
从系统外部采集数据并输入到系统内部;对数据进行抽取、转换、加载

常用的数据采集方法:
网络数据采集:网页数据;API、爬虫采集
端侧数据采集:传感器转换的物理量;摄像头、麦克风
系统日志采集:行为日志、系统日志
数据库采集:SQL
二、数据预处理
在数据集用于模型训练前,使用一定方法对数据进行处理,以便把数据变换成适用于机器学习模型训练的格式或形式
预处理类型
数据错误:
数据值错误
数据类型粗偶
数据编码错误
数据异常错误
依赖冲突
多值错误
删除错误、视为缺失值、平均值修修正
# 删除字段 import pandas as pd df = pd.read_csv(filepath) to_drop_features = ['state', 'account'] df_after_drop = df.drop(to_drop_features, axis=1)
数据重复
duplicated(),返回 True 表示数据是重复的
数据缺失
isbull() 判断各个单元格是否为空,返回 True 表示包含空值

缺失值插补:
均值插补
中位数插补
众数插补

数据集不均衡
不同类别的数据样本数量相差悬殊
工业零件质检:合格的多,有瑕疵的少
金融欺诈识别:合法的交易多,欺诈交易少
处理办法:
扩充数据集
数据重采样
数据标准化
消除量纲影响
通过一定的变换方法,将样本的属性值缩放到某个指定的范围
常用的标准化类型:
min-max(极差标准化):统一到 [0, 1] 范围内
不要求特征属性值符合某种分布
x-min(x) / max(x)-min(x)
from sklearn.preprocessing import MinMaxScaler import pandas as pd mms = MinMaxScaler() df = pd.read_csv(filepath) df_mm = mms.fit_transform(df)

z-score(中心标准化):统一为均值 0 ,方差为 1
要求特征属性值符合正态分布
x-x均值 / x标准差
from sklearn.preprocessing import StandardScaler import pandas as pd ss = StandardScaler() df = pd.read_csv(filepath) df_ss = ss.fit_transform(df)

数据编码
应用场景:
数据集特征属性没有量化:
特征属性使用字符串表示
无法用于模型训练
数据集标签没有量化:
分类标签用字符串表示
无法用于模型训练
数据编码技术:
把数据从字符串类型转换成数值类型
Label 编码
方法:
对于样本记录的取值,按照大小关系分别给每个值赋予一个数值ID
转换后依旧保留了大小关系
场景:
适用于定序型的特征属性
样本记录之间有距离和大小区分的需求
不足:
数据编码后有大小和距离的差异
编码后的结果和实际数据语义并没有直接关联
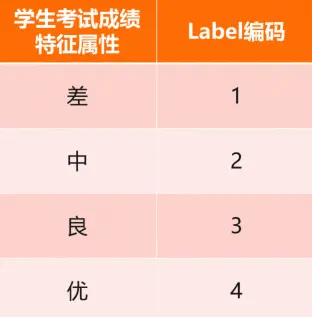
from sklearn.preprocessing import LabelEncoder df = [[2, 30, 9, 38, 60]] le = LabelEncoder() le.fit(df) le.transform(df4) array([0, 2, 1, 3, 4])
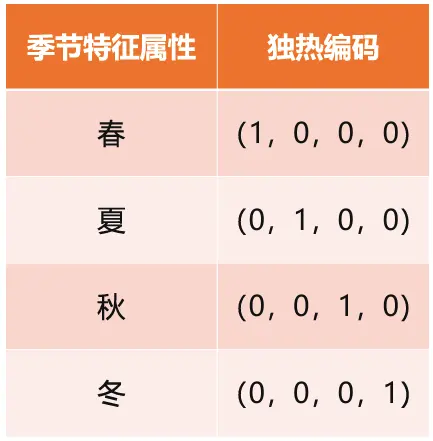
独热编码
对于一个有N个取值结果的特征属性,使用 N 个 bit 位来进行编码,适用于特定类型的特征属性
from sklearn.preprocessing import OneHotEncoder enc = OneHotEncoder() a = [[0, 0 ,3], [1, 1, 0], [0, 2, 1], [1, 0, 2]] enc.fit(a) enc.n_values_ enc.transform([[0, 1, 3]])
三、数据可视化
借助图形化手段对数据加以解释
详见:python数据可视化
QuickBI
一款全场景数据消费式的BI平台
可用以制作仪表板、电子必爱歌以及有分析思路的数据门户
可以将报表集成在业务流程中并分享给协作伙伴
DataV
数据可视化工具
可满足会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求
四、数据标注
数据标注基本介绍
概念:
通过分类、画框、标注等对语音、图片、文本数据进行处理,提高训练的准确度
标注分类:
包括语音标注、图片标注、语音标注等
具体方法:
通过画框,描点等方法对数据打标签,给后续处理提供训练信息
应用场景:
可以用于语音识别、无人驾驶、证件识别等场景
在进行人工智能算法训练时,所训练数据的质量越高最后得到的模型预测效果越好
图像标注:
图像的标注方法:
2D和3D边框
图像分类
直线二哈曲线
多边形
语义分割

图像的标注类别:


常用的图像标注工具:
LabelIMG
一种图形图像注释工具
主要用于图像分类和目标检测
Labelme
图形界面的图像标注软件
主要用于语义分割
示例:
使用Labelme多边形标注车辆,标注完成后会在当前图片路径处生成json格式文件;内含目标物体的标注信息,包括标签、颜色等信息

图像的标注质量标准
矩形框标注:需要让框刚好包围物体的边界

多边形标注:多边形的边框与物体的边缘紧密的贴合

文本标注:
文本的标注类别:
分类标注:对文本进行分类
实体标注:对文本信息中的通用实体进行标注
词性标注:对词的性质进行标注,如名词(n)、动词(v)
实体关系标注:对文本实体之间的关系进行标注

文本标注质量标准:
文本标注要情感符合真是的句子情感
语义标注要标注正确的语义
多音字要符合字典中的读音
对文本中的不感兴趣的内容进行删除
将文本分成词语
对词语进行词性的标注,比如形容词、名词、动词等
去掉文本的含义无用的词语,比如标点符号
语音标注:
语音的标注类别:
对语音对应的文本信息进行关联,常用语语音识别,实时翻译等领域
语音标注工具主要用于对数字化的语音信号进行分析、标注、处理及合成

语音的标注质量标准:
音频中的语音是否有效
说话人的方言,标记是否有口音
说话人的数量,标注语音内容的人数
说话人的性别,标注第一个说话人的性别
音频是否有明显的噪音,标注是否有噪音
标注需要与发音内容完全一致,保证文字的正确性
数据标注的常用文件格式
XML
JSON
CSV
PAI平台的智能标注介绍
支持图像、文本、视频、音频等多种数据的标注以及多模态的混合标注
提供了丰富的标注内容组间和题目组件
图像:图片OCR、目标检测、图像分类
文本:实体识别、文本分类、实体关系
语音:音频分割、音频分类、音频识别
视频:视频分类
支持自定义模板