三、指标体系与数据可视化(python可视化图表、描述性统计分析与绘图、搭建指标体系)
2024-11
浏览量:393
本文字数:14551
读完约 49 分钟
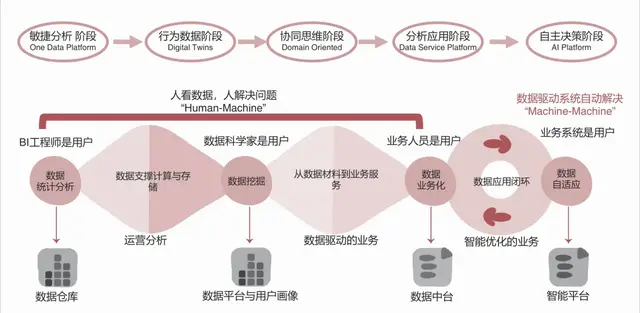
对于不同层级的决策而言,有一个统一的指标体系是支持决策的关键。
第一,统一规范,如在机构范围内形成对指标的一致认识,避免出现“同名不同义”“同义不同名”等容易产生混淆和歧义的情况;
第二,用数服务,如未来为公司不同业务用户自主灵活地用数和查询统计提供良好的指标基础,为用户提供用数服务,引导用户自主用数,提升数据使用能力;
第三,决策支持,如从企业业务战略的高度梳理并展现业务经营、财务、风险、绩效等方面的关键指标,有效支持管理层的决策。
数据的可视化展示也是数据分析过程中必不可少的内容。
一、Python可视化
1、Matplotlib绘图库
Matplotlib 是 Python 的绘图库,它能让使用者很轻松地将数据图形化,并且提供多样化的输出格式。可以用来绘制各种静态,动态,交互式的图表。Matplotlib 是一个非常强大的 Python 画图工具,我们可以使用该工具将很多数据通过图表的形式更直观的呈现出来。
Matplotlib 通常与 NumPy 和 SciPy(Scientific Python)一起使用, 这种组合广泛用于替代 MatLab,是一个强大的科学计算环境,有助于我们通过 Python 学习数据科学或者机器学习。
1)线图
Pyplot 是 Matplotlib 的子库,提供了和 MATLAB 类似的绘图 API。Pyplot 包含一系列绘图函数的相关函数,每个函数会对当前的图像进行一些修改,例如:给图像加上标记,生新的图像,在图像中产生新的绘图区域等等。
以下是一些常用的 pyplot 函数:
plot():用于绘制线图和散点图
scatter():用于绘制散点图
bar():用于绘制垂直条形图和水平条形图
hist():用于绘制直方图
pie():用于绘制饼图
imshow():用于绘制图像
subplots():用于创建子图
plot() 用于画图它可以绘制点和线,语法格式如下:
# 画单条线 plot([x], y, [fmt], *, data=None, **kwargs) # 画多条线 plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs)
x, y:点或线的节点,x 为 x 轴数据,y 为 y 轴数据,数据可以列表或数组。 fmt:可选,定义基本格式(如颜色、标记和线条样式)。 **kwargs:可选,用在二维平面图上,设置指定属性,如标签,线的宽度等。
颜色字符:'b' 蓝色,'m' 洋红色,'g' 绿色,'y' 黄色,'r' 红色,'k' 黑色,'w' 白色,'c' 青绿色,'#008000' RGB 颜色符串。多条曲线不指定颜色时,会自动选择不同颜色。
线型参数:'‐' 实线,'‐‐' 破折线,'‐.' 点划线,':' 虚线。
标记字符:'.' 点标记,',' 像素标记(极小点),'o' 实心圈标记,'v' 倒三角标记,'^' 上三角标记,'>' 右三角标记,'<' 左三角标记...等等。
>>> plot(x, y) # 创建 y 中数据与 x 中对应值的二维线图,使用默认样式 >>> plot(x, y, 'bo') # 创建 y 中数据与 x 中对应值的二维线图,使用蓝色实心圈绘制 >>> plot(y) # x 的值为 0..N-1 >>> plot(y, 'r+') # 使用红色 + 号
示例代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
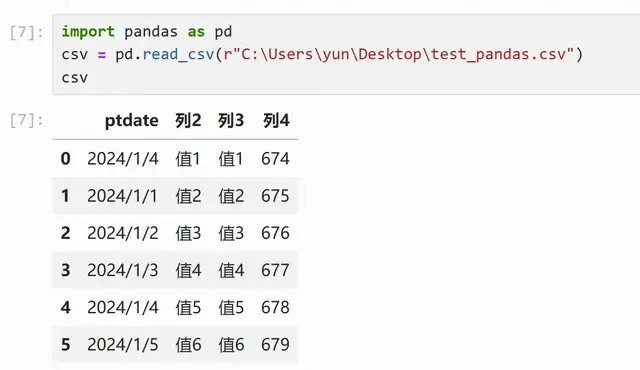
df = pd.read_csv(r"C:\Users\yun\Desktop\test_matplotlib.csv")
plt.figure(figsize=(10, 4)) # 生成画布,设置尺寸
x = df['ptdate'] # 设置x轴
y1 = df['cost'] # y1轴
y2 = df['click'] # y2轴
plt.plot(x, y1, '-o', x, y2, '-o')
plt.title('消耗趋势') # 图表标题
plt.xlabel('日期') # x轴标签
plt.ylabel('消耗点击') # y轴标签
plt.legend(['消耗', '点击']) # 图例
plt.rcParams['font.family'] = 'STZhongsong' # 解决中文字体显示问题
plt.show() # 展示图形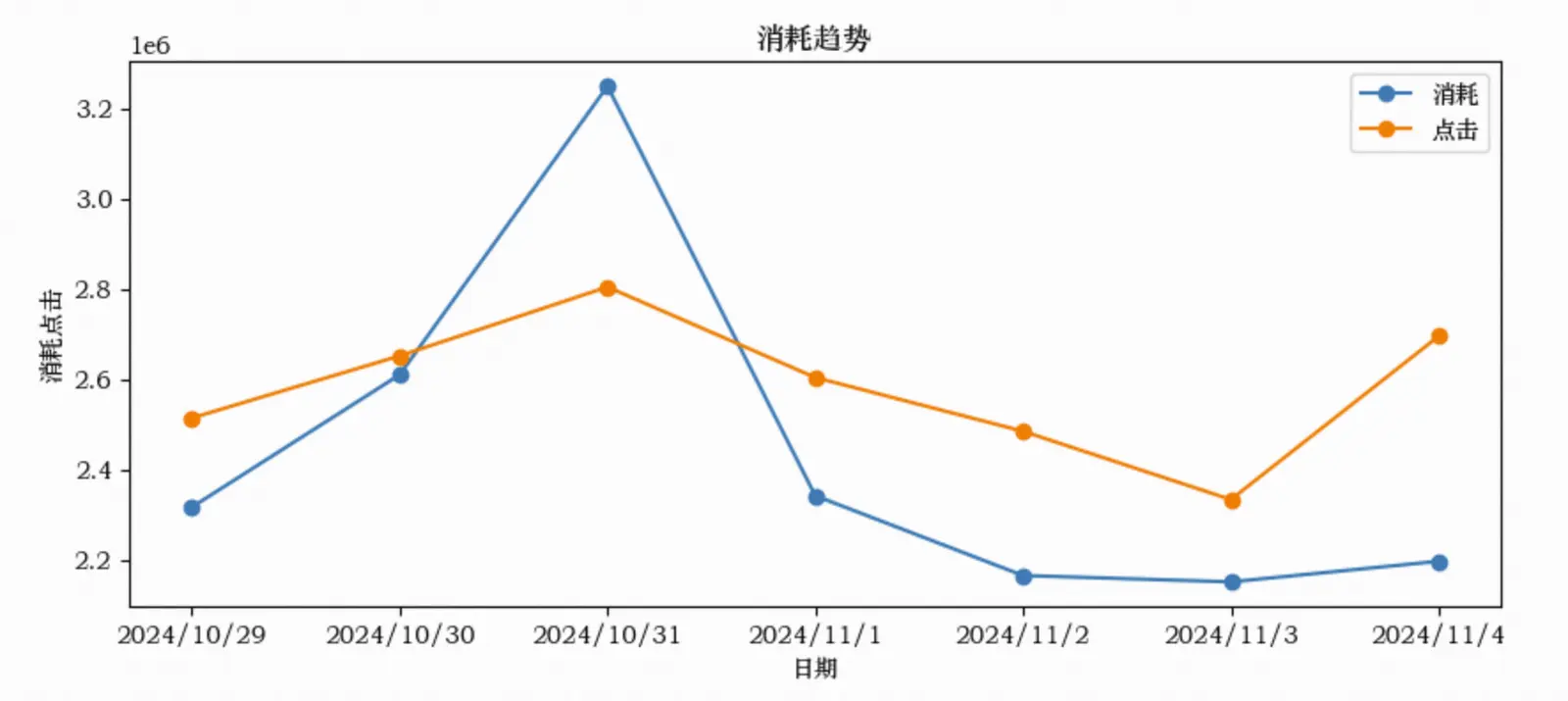
2)饼图
饼图(Pie Chart)是一种常用的数据可视化图形,用来展示各类别在总体中所占的比例。使用 pyplot 中的 pie() 方法来绘制饼图
pie() 方法语法如下:
matplotlib.pyplot.pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=0, 0, frame=False, rotatelabels=False, *, normalize=None, data=None)[source]
参数说明:
x:浮点型数组或列表,用于绘制饼图的数据,表示每个扇形的面积。
explode:数组,表示各个扇形之间的间隔,默认值为0。
labels:列表,各个扇形的标签,默认值为 None。
colors:数组,表示各个扇形的颜色,默认值为 None。
autopct:设置饼图内各个扇形百分比显示格式,%d%% 整数百分比,%0.1f 一位小数, %0.1f%% 一位小数百分比, %0.2f%% 两位小数百分比。
labeldistance:标签标记的绘制位置,相对于半径的比例,默认值为 1.1,如 <1则绘制在饼图内侧。
pctdistance::类似于 labeldistance,指定 autopct 的位置刻度,默认值为 0.6。
shadow::布尔值 True 或 False,设置饼图的阴影,默认为 False,不设置阴影。
radius::设置饼图的半径,默认为 1。
startangle::用于指定饼图的起始角度,默认为从 x 轴正方向逆时针画起,如设定 =90 则从 y 轴正方向画起。
counterclock:布尔值,用于指定是否逆时针绘制扇形,默认为 True,即逆时针绘制,False 为顺时针。
wedgeprops :字典类型,默认值 None。用于指定扇形的属性,比如边框线颜色、边框线宽度等。例如:wedgeprops={'linewidth':5} 设置 wedge 线宽为5。
textprops :字典类型,用于指定文本标签的属性,比如字体大小、字体颜色等,默认值为 None。
center :浮点类型的列表,用于指定饼图的中心位置,默认值:(0,0)。
frame :布尔类型,用于指定是否绘制饼图的边框,默认值:False。如果是 True,绘制带有表的轴框架。
rotatelabels :布尔类型,用于指定是否旋转文本标签,默认为 False。如果为 True,旋转每个 label 到指定的角度。
data:用于指定数据。如果设置了 data 参数,则可以直接使用数据框中的列作为 x、labels 等参数的值,无需再次传递。
除此之外,pie() 函数还可以返回三个参数:
edges:一个包含扇形对象的列表。
texts:一个包含文本标签对象的列表。
autotexts:一个包含自动生成的文本标签对象的列表。
代码示例:
# 饼图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.DataFrame({'group': list('ABCD'), 'data': [10, 20, 30, 40]}) # 构造数据
plt.rcParams['font.family'] = 'STZhongsong' # 解决中文字体显示问题
plt.figure(figsize=(6, 6))
x = df['group'] # 标签
y = df['data'] # 数据
explode = (0,0,0,0.04) # 间隔
plt.pie(y, labels=x, explode=explode, autopct='%.1f%%')
plt.show()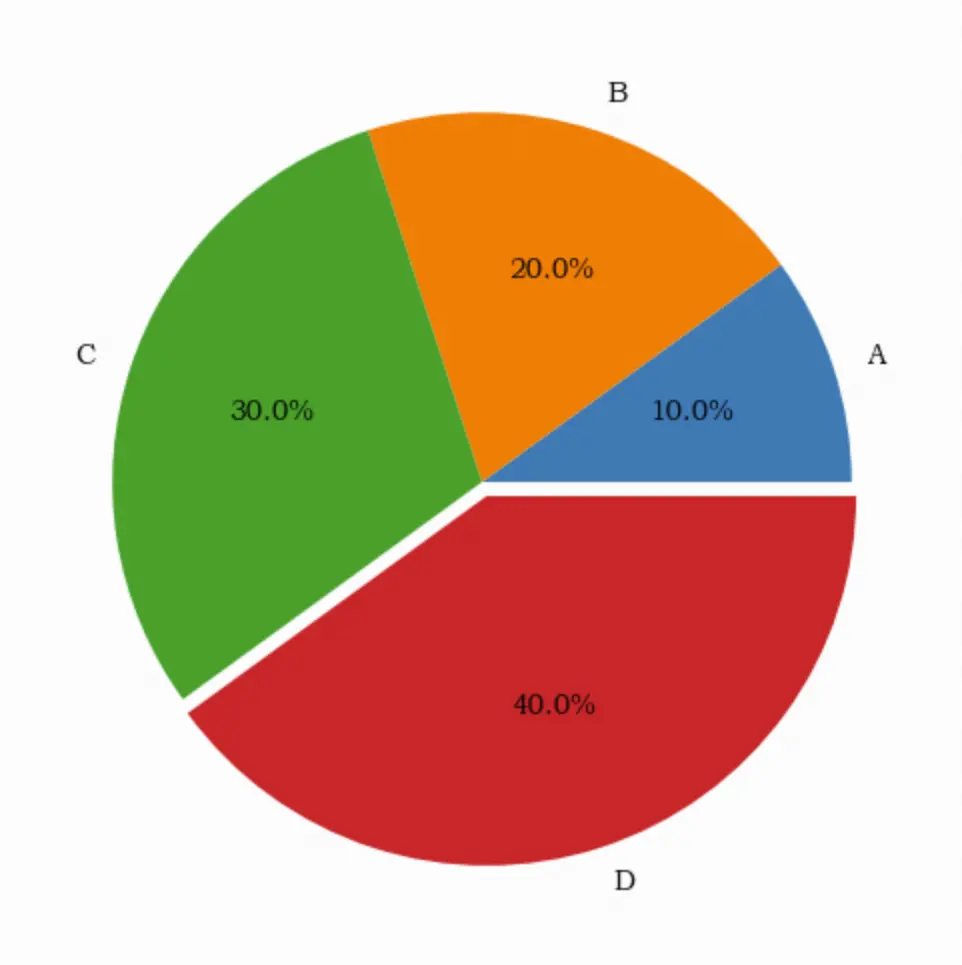
3)条形图
条形图是展示分类型变量数据分布的常用图形。使用 pyplot 中的 bar() 方法来绘制柱形图
bar() 方法语法如下:
matplotlib.pyplot.bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwargs)
参数说明:
x:浮点型数组,柱形图的 x 轴数据。
height:浮点型数组,柱形图的高度。
width:浮点型数组,柱形图的宽度。
bottom:浮点型数组,底座的 y 坐标,默认 0。
align:柱形图与 x 坐标的对齐方式,'center' 以 x 位置为中心,这是默认值。 'edge':将柱形图的左边缘与 x 位置对齐。要对齐右边缘的条形,可以传递负数的宽度值及 align='edge'。
**kwargs::其他参数。
示例代码:
# 条形图/柱状图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.DataFrame({'group': list('ABCD'), 'data': [60, 20, 30, 40]})
plt.rcParams['font.family'] = 'STZhongsong' # 解决中文字体显示问题
plt.figure(figsize=(6, 6))
# 画图之前处理一下数据排列顺序
x = df.sort_values('data')['group'] # 按照 data 数据排序
y = df.sort_values('data')['data'] # 按照 data 数据排序
# 竖条
plt.bar(x, y, width=0.4)
# 横条
# plt.barh(x, y, height=0.4)
plt.show()

4)直方图
直方图(Histogram),又称质量分布图,是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据类型,纵轴表示分布情况。
直方图是数值数据分布的精确图形表示。 这是一个连续变量(定量变量)的概率分布的估计,并且被卡尔·皮尔逊(Karl Pearson)首先引入。它是一种条形图。 为了构建直方图,第一步是将值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。 这些值通常被指定为连续的,不重叠的变量间隔。 间隔必须相邻,并且通常是(但不是必须的)相等的大小。
直方图是展示连续变量数据分布的一种图形,用条形的宽度和高度(面积)表示频数分布。直方图用面积表示各组频数的多少,条形的高度表示每组数据的频数或频率,条形的宽度表示各组数据的组距,因此高度和宽度都有意义。
用于可视化数据的分布情况,例如观察数据的中心趋势、偏态和异常值等。使用 pyplot 中的 hist() 方法来绘制直方图
hist() 方法语法如下:
matplotlib.pyplot.hist(x, bins=None, range=None, density=False, weights=None, cumulative=False, bottom=None, histtype='bar', align='mid', orientation='vertical', rwidth=None, log=False, color=None, label=None, stacked=False, **kwargs)
参数说明:
x:表示要绘制直方图的数据,可以是一个一维数组或列表。
bins:可选参数,表示直方图的箱数。默认为10。
range:可选参数,表示直方图的值域范围,可以是一个二元组或列表。默认为None,即使用数据中的最小值和最大值。
density:可选参数,表示是否将直方图归一化。默认为False,即直方图的高度为每个箱子内的样本数,而不是频率或概率密度。
weights:可选参数,表示每个数据点的权重。默认为None。
cumulative:可选参数,表示是否绘制累积分布图。默认为False。
bottom:可选参数,表示直方图的起始高度。默认为None。
histtype:可选参数,表示直方图的类型,可以是'bar'、'barstacked'、'step'、'stepfilled'等。默认为'bar'。
align:可选参数,表示直方图箱子的对齐方式,可以是'left'、'mid'、'right'。默认为'mid'。
orientation:可选参数,表示直方图的方向,可以是'vertical'、'horizontal'。默认为'vertical'。
rwidth:可选参数,表示每个箱子的宽度。默认为None。
log:可选参数,表示是否在y轴上使用对数刻度。默认为False。
color:可选参数,表示直方图的颜色。
label:可选参数,表示直方图的标签。
stacked:可选参数,表示是否堆叠不同的直方图。默认为False。
alpha:可选参数,颜色透明度
**kwargs:可选参数,表示其他绘图参数。
示例代码:
# 直方图
import matplotlib.pyplot as plt
import numpy as np
# 生成一组随机数据
data = np.random.randn(1000)
# 绘制直方图
# bins 参数为 10,这意味着将数据范围分成 10 个等宽的区间,然后统计每个区间内数据的频数。
plt.hist(data, bins=10, color='skyblue', alpha=0.8)
# 设置图表属性
plt.title('直方图测试')
plt.xlabel('X标签')
plt.ylabel('Y标签')
# 显示图表
plt.show()
5)散点图
散点图是使用二维坐标展示两个变量的关系的一种图形。使用 pyplot 中的 scatter() 方法来绘制散点图
scatter() 方法语法如下:
matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None, linewidths=None, *, edgecolors=None, plotnonfinite=False, data=None, **kwargs)
参数说明:
x,y:长度相同的数组,也就是我们即将绘制散点图的数据点,输入数据。
s:点的大小,默认 20,也可以是个数组,数组每个参数为对应点的大小。
c:点的颜色,默认蓝色 'b',也可以是个 RGB 或 RGBA 二维行数组。
marker:点的样式,默认小圆圈 'o'。
cmap:Colormap,默认 None,标量或者是一个 colormap 的名字,只有 c 是一个浮点数数组的时才使用。如果没有申明就是 image.cmap。
norm:Normalize,默认 None,数据亮度在 0-1 之间,只有 c 是一个浮点数的数组的时才使用。
vmin,vmax::亮度设置,在 norm 参数存在时会忽略。
alpha::透明度设置,0-1 之间,默认 None,即不透明。
linewidths::标记点的长度。
edgecolors::颜色或颜色序列,默认为 'face',可选值有 'face', 'none', None。
plotnonfinite::布尔值,设置是否使用非限定的 c ( inf, -inf 或 nan) 绘制点。
**kwargs::其他参数。
示例代码:
# 散点图
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.family'] = 'STZhongsong' # 解决中文字体显示问题
plt.figure(figsize=(6, 6))
df = pd.DataFrame({'A':[1,2,3,4,5,6], 'B':[1,2,9,16,25,36]})
df2 = pd.DataFrame({'A':[2,4,6,8,10,12], 'B':[10,2,9,16,25,36]})
x = df['A']
y = df['B']
plt.scatter(x, y)
x = df2['A']
y = df2['B']
plt.scatter(x, y, color='hotpink', s=100)
# 显示图表
plt.show()
6)箱线图
箱线图是由一组数据的中位数、上四分位数、下四分位数、距离上四分位数1.5倍四分位距(IQR)内的最大值、距离下四分位数1.5倍四分位距(IQR)内的最小值这5个特征值绘制而成的,主要反映数据分布的特征,还可以进行多组数据分布特征的比较。
使用 pyplot 中的 boxplot() 方法来绘制箱线图
boxplot() 方法语法如下:
matplotlib.pyplot.boxplot(x, notch=None, sym=None, vert=None, whis=None, positions=None, widths=None, patch_artist=None, bootstrap=None, usermedians=None, conf_intervals=None, meanline=None, showmeans=None, showcaps=None, showbox=None, showfliers=None, boxprops=None, labels=None, flierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None, manage_ticks=True, autorange=False, zorder=None, capwidths=None, *, data=None)
常规参数:
x:指定要绘制箱形图的数据
notch:是否绘制带缺口的箱形图
patch_artist:是否填充箱体的颜色
vert:是否将箱线图垂直摆放
widths:指定箱线图的宽度
sym:指定异常点的形状
whis:指定上下边界与上下四分位数的距离
labels:为箱线图添加标签
capwidths:设置须线帽长度
position:指定箱线图的位置
显示控制参数:
showmeans:是否显示均值点
meanline:是否显示均值线
showbox:是否显示箱形图的箱体
showcaps:是否显示须线帽
showfliers:是否显示异常值
细节控制参数:(对于细节属性参数需要输入字典格式的数据)
medianprops:设置中位线属性
meanprops:设置均值点属性
boxprops:设置箱体属性
capprops:设置须帽属性
whiskerprops:设置须线属性
flierprops:设置异常点属性
示例代码:
# 箱线图
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams['font.family'] = 'STZhongsong' # 解决中文字体显示问题
plt.figure(figsize=(6, 6))
df = pd.DataFrame({'A':np.random.randint(60,150,10), 'B':np.random.randint(40,150,10), 'C':np.random.randint(20,150,10)})
x = df['A']
y = df['B']
z = df['C']
plt.boxplot([x, y, z], tick_labels=['A', 'B', 'C'])
# 显示图表
plt.show()
2、Seaborn绘图库
Seaborn是一个基于Matplotlib的Python数据可视化库,提供了一个用于绘制有吸引力和信息丰富的统计图形的高级界面。Seaborn 提供了一些简单的高级接口,可以轻松地绘制各种统计图形,包括散点图、折线图、柱状图、热图等,而且具有良好的美学效果。Seaborn 在设计时注重美观性,其默认主题和颜色调色板经过精心选择,使得绘图更加吸引人。
Seaborn是一个用Python制作统计图形的库。它建立在matplotlib之上,并与panda数据结构紧密集成
以下是seaborn提供的一些功能:
一个面向数据集的API,用于检查多个变量之间的关系
专门支持使用分类变量来显示观察结果或汇总统计数据
用于可视化单变量或双变量分布以及在数据子集之间进行比较的选项
各类因变量线性回归模型的自动估计与作图
方便查看复杂数据集的整体结构
用于构建多图块网格的高级抽象,使您可以轻松地构建复杂的可视化
对matplotlib图形样式与几个内置主题的简洁控制
选择调色板的工具,忠实地揭示您的数据模式
Seaborn的目标是使可视化成为探索和理解数据的核心部分。它的面向数据集的绘图功能对包含整个数据集的数据流和数组进行操作,并在内部执行必要的语义映射和统计聚合以生成信息图。
pip install seaborn
通过设置不同的主题和模板,可以调整 Seaborn 图形的大小、线条的粗细、颜色等属性,以适应不同的绘图场景。这些内置的主题和模板使得用户能够更轻松地创建美观且具有一致性的图形。
设置 sns.set_theme() 函数,可以选择不同的主题和模板,以下是 Seaborn 内置的一些主题和模板:
主题(Theme):
darkgrid(默认):深色网格主题。
whitegrid:浅色网格主题。
dark:深色主题,没有网格。
white:浅色主题,没有网格。
ticks:深色主题,带有刻度标记。
模板(Context):
paper:适用于小图,具有较小的标签和线条。
notebook(默认):适用于笔记本电脑和类似环境,具有中等大小的标签和线条。
talk:适用于演讲幻灯片,具有大尺寸的标签和线条。
poster:适用于海报,具有非常大的标签和线条。
seaborn常用绘图函数:
sns.scatterplot():散点图,用于绘制两个变量之间的散点图,可选择添加趋势线。
sns.lineplot():折线图,用于绘制变量随着另一个变量变化的趋势线图。
sns.barplot():柱状图/条形图,用于绘制变量的均值或其他聚合函数的柱状图。
sns.boxplot():箱线图,用于绘制变量的分布情况,包括中位数、四分位数等。
sns.heatmap():热图,用于绘制矩阵数据的热图,通常用于展示相关性矩阵。
sns.violinplot():小提琴图,用于显示分布的形状和密度估计,结合了箱线图和核密度估计。
代码示例:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# rc 解决seaborn中的中文字体显示问题
'''
虽然已经处理了matplotlib中SimHei中文字体缺失,但是为了在seaborn中显示中文,还需要利用set()的rc参数传递设置,修改rcParams中的字体为中文字体。
主要修改两个参数:
font.sans-serif: 设置图像中的非衬线字体,必须是操作系统或matplotlib内置的字体,下文用黑体(SimHei)做示例;
axes.unicode_minus: 设置为False,解决中文字体下显示不出负号。
'''
rc = {'font.sans-serif': 'SimHei',
'axes.unicode_minus': False}
sns.set(style='darkgrid', context='notebook', rc=rc)
df = pd.DataFrame({'group': list('ABCD'), 'data': [60, 20, 30, 40]})
x = df['group']
y = df['data']
sns.barplot(x=x, y=y)
plt.title('柱状图')
plt.xlabel('X标签')
plt.ylabel('Y标签')
plt.show()
1)带核密度估计的直方图
直方图旨在通过分箱和计数观察近似生成数据的潜在概率密度函数。Seaborn中的核密度估计为同一个问题提供了不同的解决方案。核密度估计图不使用离散箱,而使用高斯核平滑观察,产生连续的密度估计.
# 带核密度估计的直方图
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# rc 解决seaborn中的中文字体显示问题
rc = {'font.sans-serif': 'SimHei',
'axes.unicode_minus': False}
sns.set(style='darkgrid', context='notebook', rc=rc)
data = np.random.randn(10000)
# kde=True 显示核密度估计曲线
sns.displot(data, bins=100, kde=True)
plt.show()
2)二元分布图
绘制联合分布和边际分布,使用两个变量的边际分布扩充二元关系图或二元分布图。
代码示例:
# 二元分布图
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# rc 解决seaborn中的中文字体显示问题
rc = {'font.sans-serif': 'SimHei',
'axes.unicode_minus': False}
sns.set(style='white', context='notebook', rc=rc)
np.random.seed(0)
mean, cov = [0,1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=['x', 'y'])
df.head()
sns.jointplot(x='x', y='y', data=df)
plt.show()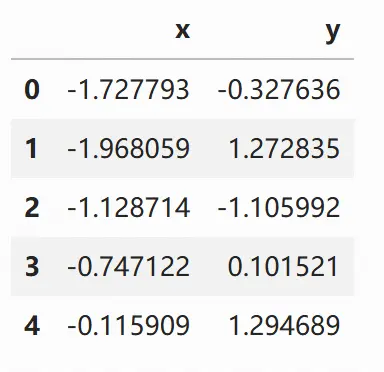

如果只需要绘制中间的散点图,不需要绘制单个变量的分布图,则绘制代码如下:
sns.relplot(x='x', y='y', data=df) plt.show()

绘制带核密度估计的二元分布图,代码如下:
sns.jointplot(x='x', y='y', data=df, kind='kde') plt.show()

如果只需要绘制中间的密度曲线图,不需要绘制单个变量的密度曲线图,则绘制代码如下:
sns.displot(x='x', y='y', data=df, kind='kde') plt.show()

3)热力图
在查看变量间的关系强弱时,通常会用到热力图。用于绘制矩阵数据的热图,通常用于展示相关性矩阵。
数据如下:

从数据表中很难观测变量间相关关系的强弱,通过热力图可以很好地解决这个问题,绘制热力图的代码如下:
# 热力图
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# rc 解决seaborn中的中文字体显示问题
rc = {'font.sans-serif': 'SimHei',
'axes.unicode_minus': False}
sns.set(style='white', context='notebook', rc=rc)
np.random.seed(0)
df = pd.DataFrame(np.random.uniform(-1,1,(7,7)), index=list('abcdefg'), columns=list('ABCDEFG'))
# df.head()
plt.figure(figsize=(8,6))
sns.heatmap(df)
plt.show()
在热力图中,颜色越深,两者的负相关关系越强;颜色越浅,两者的正相关关系越强。
二、描述性统计分析与绘图
数据描述强调方法,即从现有的数据中获得主要的信息,如人们的平均收入等。数据探索强调过程,即通过数据描述的方法,对研究的客体有更深入的认识,如人们的平均收入是多少、每年变化情况如何、受什么因素的影响。
在一个数据科学模型开发的过程中,探索数据贯穿始终,占用整个模型开发工作量的40%。
1、描述性统计进行数据探索
1)变量度量类型与分布类型
在进行数据分析之前,要明确变量的度量类型。
(1)名义变量(无序分类型变量):包含类别信息的变量,并且类别间没有大小、高低、次序之分,如人口统计学中的“性别”“民族”“居住城市”等指标。
(2)等级变量(有序分类型变量):是一种分类型变量,类别间有大小、高低、次序之分,如问卷调查中的“消费者满意度”、人口统计学中的“年龄段”等指标。
(3)连续型变量:在规定的范围内可以取任意值,如人口统计学中的“收入”指标,只要不低于0,其他的数字都可能出现,类似的变量还有互联网领域的“网站流量”指标、宏观经济数据中的GDP指标等。
名义变量和等级变量被统称为分类型变量,分类型变量是相对于连续型变量而言的。过多水平的等级变量可以选择进行“概化”或当作连续型变量进行分析。
变量的分布类型是对实际变量分布的概括和抽象。探察变量分布的意义在于,只要知道某个变量服从(根据人为判断)某个分布,就可以很快地了解变量在相应取值时的概率(分布是从无数个变量频率得到的,对其统计特性有深入的分析),并且结合相应的业务场景做出解释。
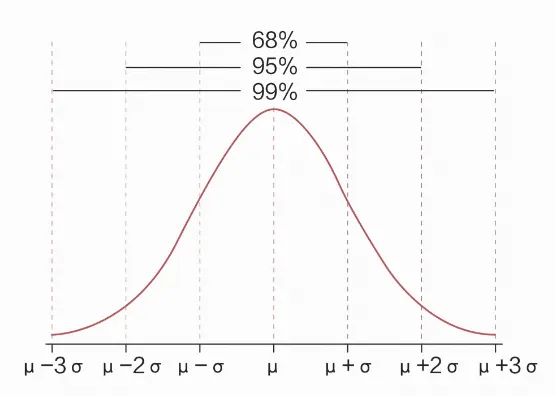
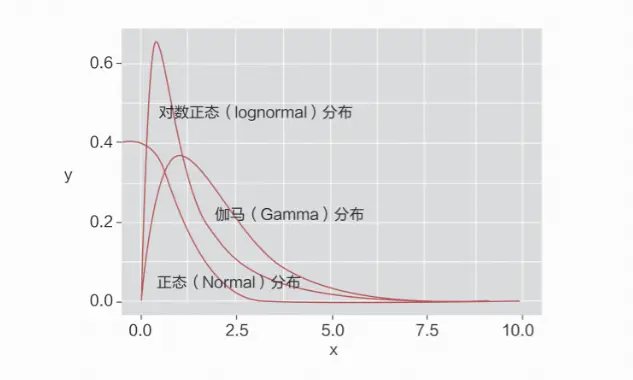
一个变量的分布有有限个参数,只要明确这些参数的取值,该变量分布的具体形态和性质就可以确定了。比如,二项分布的参数为任意一个类别的概率;正态分布的参数有两个,分别是均值和方差。
2)分类型变量的统计量
名义变量有两类统计量,分别是频次、百分比。等级变量有4类统计量,分别是频次、百分比、累计频次、累计百分比。
3)连续型变量的分布与集中趋势
数据的集中水平:使用某个指标表示数据的集中趋势,常见的指标有平均数、中位数与众数。
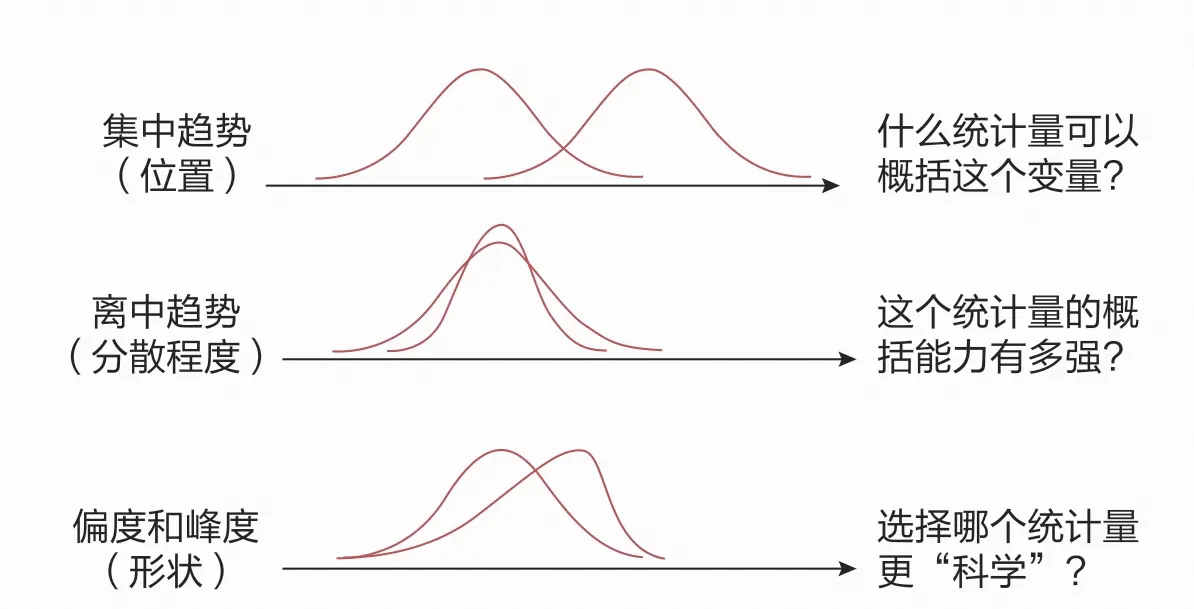
(1)平均数:用加总变量的取值除以变量的个数,反映数据的集中水平。例如,使用人均GDP体现某个国家或地区的人民生活水平。
(2)中位数/四分位数/百分位数:首先将数据从小到大排列,再选取中间位置的数字作为数据的集中水平,这个数字就是中位数。当选取其他位置的数据时,如四分之一水平与四分之三水平的位置时,就变成了四分位数。中位数使用数据的次序信息而非取值,这是其与均值的不同之处,而某些时候中位数比均值更能反映数据的集中水平。
(3)众数:数据中出现次数最多的值,在分类型变量中是出现次数最多的一类数据,当然对连续型变量也能够计算众数,只是不常用。
例如,收入是一个典型的右偏分布的变量,高收入的人数极少,但收入极高,这样就会影响数据的分布,平均值会被极高收入的人拉高,此时中位数更能反映数据的集中趋势。实际上,很多国家在描述收入的集中趋势时使用的就是收入的中位数,而非平均数。
4)连续型变量的离散程度
只描述数据的集中水平是不够的,因为这样会忽视数据的差异情况。这里需要引入另一个指标或统计量用来描述数据的离散程度。描述数据离散程度的常见指标有极差、方差、标准差和平均绝对偏差。
(1)极差:变量的最大值与最小值之差
(2)方差(Variance)
(3)标准差(Standard Deviation)
(4)平均绝对偏差(Mean Absolute Deviation)
以上4个指标都能够反映数据的离散程度,方差和标准差以其良好的数学特性(可求导)得到广泛应用。
5)数据分布的对称与高低
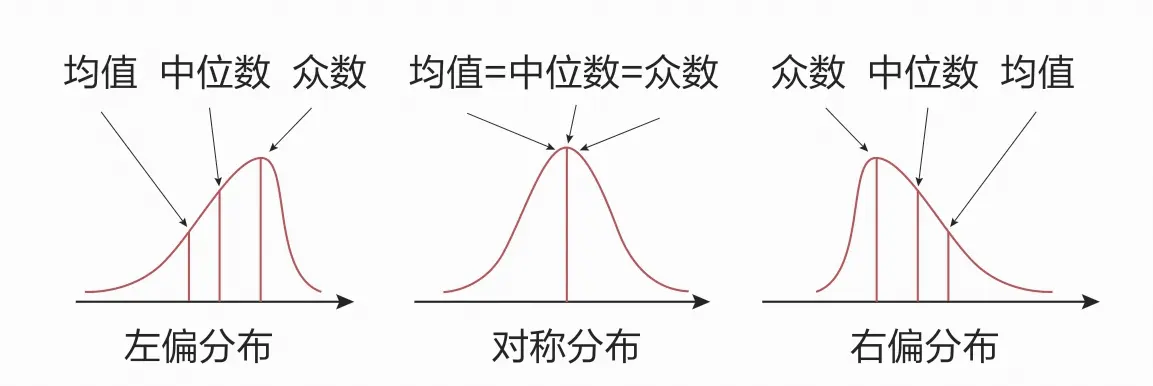
数据分布是否对称会影响平均数是否能够表示数据的集中水平。那么在描述数据分布的对称与高低时,应使用什么指标呢?这里需要引入偏度和峰度的概念。
偏度即数据分布的偏斜程度,峰度即数据分布的高低程度。对于标准正态分布(均值为0,标准差为1)的变量,其偏度与峰度都为0。
当左偏分布时,偏度小于0;当对称分布时,偏度为0;当右偏分布时,偏度大于0。
峰度大于0,变量的分布相较标准正态分布更加集中。峰度小于0,变量的分布相较标准正态分布更为分散。


pandas提供了skew和kurtosis方法实现偏度与峰度的计算。例如,模拟100个标准正态分布的随机数,代码如下:
import pandas as pd import numpy as np data = pd.Series(np.random.randn(1000), name='data') data.skew() # 结果:np.float64(-0.07050106101633022) data.kurtosis() # 结果:np.float64(0.06453363507160281)
2、制作报表与统计制图
报表是展现数据的主要信息载体,分为维度(分类型变量)和度量(连续型变量)。制作报表就是根据数据类型,选取适合的统计量并进行展示的过程。


箱线图的基本元素如下。
(1)IQR:变量上、下四分位数之间的数据,这个范围表示中间50%的数据。
(2)中位数:中位数的位置表示变量中位数在总体分布中的位置。
(3)1.5倍IQR:上、下1.5倍IQR表示上、下1.5倍IQR范围的数据。超出这个围的数据是异常值。

直方图与箱线图的对比,可以看出两者具有一致性。
3、制图的步骤
在进行描述性图表展示时,制图步骤大致分为以下4步:
(1)整理原始数据:对原始数据进行预处理和清洗,以达到制图的要求。
(2)明确表达的信息:根据初始可用数据,明确分析所要表达的信息。
(3)确定比较的类型:明确所要表达的信息中要比较的目标类型。
(4)选择图表类型:选择合适的图表类型进行绘制并展示。

三、指标体系
1、建立指标标准
1)指标标准
指标标准是数据管控体系的核心,是连接基础数据和数据应用的桥梁。
有了统一规范、统一指标之后,才可以提供更好的数据服务。而且标准是统一的,也便于决策的支持。这也是建立指标体系的一个诉求。简单来说,指标标准就是组织内的成员都用同一个词汇、同一套标准。车同轨,路同辙。
2)统一规范
在组织内形成对指标的一致认识,避免出现“同名不同义”“同义不同名”等容易产生混淆和歧义指标的情况,保证组织内统一、有效的指标统计应用。
3)用数服务
为组织内不同业务用户自主灵活地用数和查询统计提供良好的指标基础,提升组织的数据使用能力。
4)决策支持
从企业业务战略的高度梳理并展示业务经营、财务、风险、绩效等方面的关键指标,有效支持管理层的决策。
2、什么是指标体系
指标体系是指系统地反映评价对象整体的多个具体指标的集合。
指标体系是由什么构件组成的呢?指标和维度。
指标是反映企业经营管理在一定时间和条件下的规模、程度、比例、结构等的概念和数值。
维度(也被称为统计维度、筛选条件)是对企业在业务经营过程中涉及的对象的属性进行划分的方式。

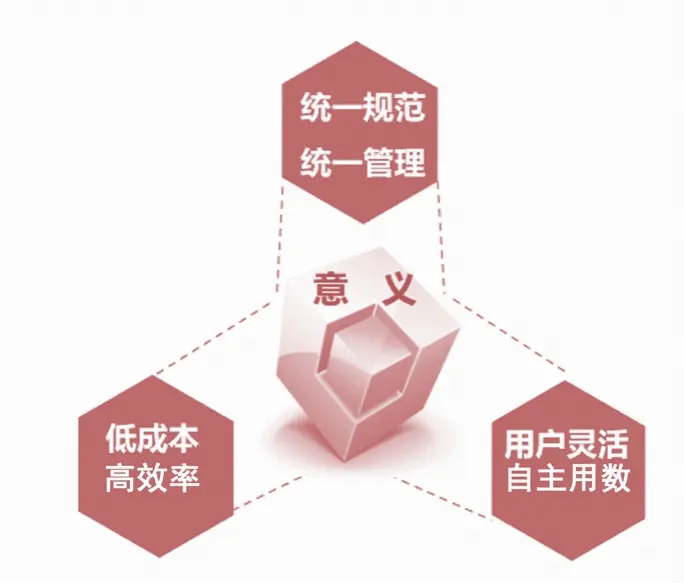
3、构建指标体系的意义
(1)指标口径清晰、统一规范;
(2)支持用户的自主、灵活用数;
(3)有效控制报表开发成本。
怎样分析一个报表体系的需求呢?
一般情况下,需要归纳各个业务部门的需求,即归纳如下三个层面的需求。
第一个层面,决策层。决策层就是高级管理层。
第二个层面,管理层。管理层一般就是部门负责人。
第三个层面,执行层。执行层即部门内部员工,收集他们各方面的指标需求,通过指标需求把数据按照维度进行归纳。
归纳以上需求,可以满足固定报表、指标、多维分析的要求,还可以根据主题进行查询,满足企业管理的各种要求。
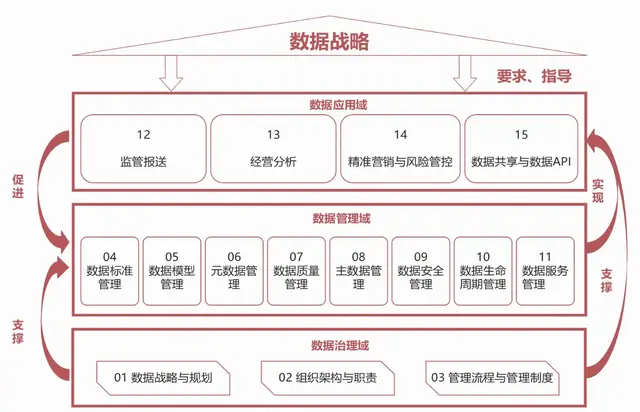
4、构建指标库
1)指标体系的构建
指标体系包括根指标、组合指标和派生指标。

2)指标库
常见指标库的情况,通过根指标一步步推演。因此,一般情况下先推导根指标,归纳有哪些根指标,以及根指标与维度某个取值结合得到组合指标,再根据实际业务需求得到派生指标,最终生成指标体系。
3)维度库
所谓维度,类似参考数据。什么是参考数据?一般情况下参考数据是供业务系统参照使用的数据,如国别、性别、产品码,这些都是参考数据。
维度有什么作用?维度可以实现灵活取数。灵活取数的平台基本上是由一个度量指标库(如贷款余额指标库)和维度库组成的。比如,银行一般分几十种维度,如地域维度、产品维度、客群维度、科学维度等。

4)指标体系案例
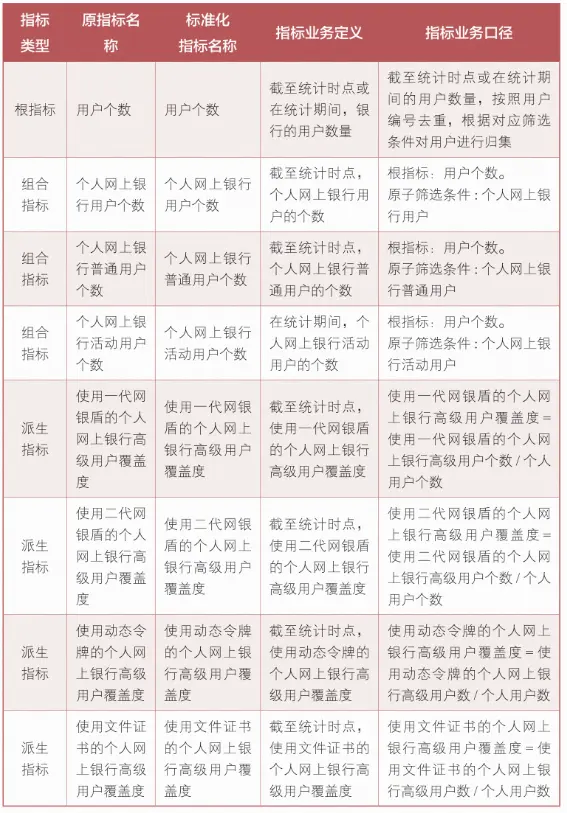
银行的常用指标库


5、搭建管理分析视图和指标应用模式
1)搭建管理分析视图
有了指标体系后,可以根据不同用户的需求,搭建管理分析视图
比如,集团管理层需要了解企业整体运营状况,公司管理层需要了解企业重点项目、重点用户的整体概要,用户经理需要了解运营方面的情况。

2)搭建指标应用模式
指标应用可以有各种不同的展现方式。结合不同的用户需求,搭建不同的指标应用模式,如固定报表、灵活查询、应急预测和可视化的、便捷的工具。