《这就是ChatGPT》
2025-02
浏览量:440
本文字数:14268
读完约 48 分钟
前言:
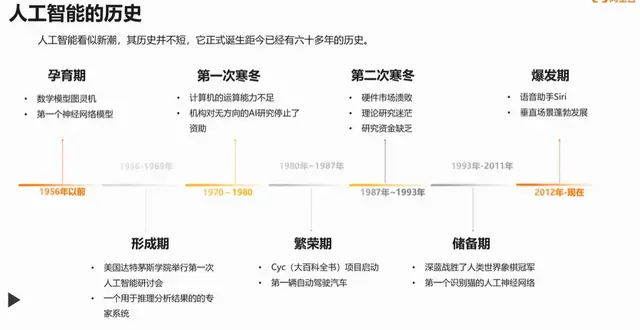
以ChatGPT为代表的人工神经网络的逆袭之旅,在整个科技史上也算得上跌宕起伏。它曾经在流派众多的人工智能界内部屡受歧视和打击。不止一位天才先驱以悲剧结束一生:1943年,沃尔特·皮茨(Walter Pitts)在与沃伦·麦卡洛克(Warren McCulloch)共同提出神经网络的数学表示时才20岁,后来因为与导师维纳失和而脱离学术界,最终因饮酒过度于46岁辞世;1958年,30岁的弗兰克·罗森布拉特(Frank Rosenblatt)通过感知机实际实现了神经网络,而1971年,他在43岁生日那天溺水身亡;反向传播的主要提出者大卫·鲁梅尔哈特(DavidRumelhart)则正值盛年(50多岁)就罹患了罕见的不治之症,1998年开始逐渐失智,最终在与病魔斗争十多年后离世……
一些顶级会议以及明斯基这样的学术巨人都曾毫不客气地反对甚至排斥神经网络,逼得辛顿等人不得不先后采用“关联记忆”“并行分布式处理”“卷积网络”“深度学习”等中性或者晦涩的术语为自己赢得一隅生存空间。
辛顿自己从20世纪70年代开始,坚守冷门方向几十年。从英国到美国,最后立足曾经的学术边陲加拿大,他在资金支持匮乏 的情况下努力建立起一个人数不多但精英辈出的学派。直到2012年,他的博士生伊尔亚·苏茨克维等在ImageNet比赛中用新方法一飞冲天,深度学习才开始成为AI的显学,并广泛应用于各个产业。2020年,他又在OpenAI带队,通过千亿参数的GPT-3开启了大模型时代。
2022年6月,论文“Emergent Abilities of Large LanguageModels”发布,第一作者是仅从达特茅斯学院本科毕业两年的谷歌研究员Jason Wei(今年2月,他在谷歌的“精英跳槽潮”中去了OpenAI)。他在论文中研究了大模型的涌现能力,这类能力在小模型中不存在,只有模型规模扩大到一定量级才会 出现——也就是我们熟悉的“量变会导致质变”。
一、ChatGPT在做什么?它为何能做到这些?
1、一次添加一个词
ChatGPT从根本上始终要做的是,针对它得到 的任何文本产生“合理的延续”。这里所说的“合理”是指,“人们在看到诸如数十亿个网页上的内容后,可能期待别人会这样写”。最终的结果是,它会列出随后可能出现的词及其出现的“概率”(按“概率”从高到低排列)。“根据目前的文本,下一个词应该是什么”,并且每次都添加一个词。

它在每一步都会得到一个带概率的词列表。但它应该选择将哪一个词添加到正在写作的文章中呢?有人可能认为应该选择“排名最高”的词,即分配了最高“概率”的词。然而,这里出现了一点儿玄学的意味。
如果我们总是选择排名最高的词,通常会得到一篇非常“平淡”的文章,完全显示不出任何“创造力”(有时甚至会一字不差地重复前文。但是,如果有时(随机)选择排名较低的词,就会得到一篇“更有趣”的文章。
这里存在随机性意味着,如果我们多次使用相同的提示(prompt),每次都有可能得到不同的文章。而且,符合玄学思想的是,有一个所谓的“温度”参数来确定低排名词的使用频率。对于文章生成来说,“温度”为0.8似乎最好。(值得强调的是,这里没有使用任何“理论”,“温度”参数只是在实践中被发现有效的一种方法。例如,之所以采用“温度”的概念,是因为碰巧使用了在统计物理学中很常见的某种指数分布[插图],但它与物理学之间并没有任何实际联系,至少就我们目前所知是这样的。)
2、概率从何而来
考虑逐字母(而非逐词)地生成英文文本。怎样才能计算出每个字母应当出现的概率呢?
拿一段英文文本样本,然后计算其中不同字母的出现次数;如果我们采集足够大的英文文本样本,最终就可以得到相当一致的结果。
我们可以通过添加空格将其分解成“词”,就像这些“词”也是具有一定概率的字母一样。
还可以通过强制要求“词长”的分布与英文中相符来更好地造“词”。
典型英文文本中字母对[二元(2-gram或bigram)字母]的概率。可能出现的第一个字母横向显示,第二个字母纵向显示。

现在不再一次一个字母地生成“词”,而是使用这些二元字母的概率,一次关注两个字母。下面是可以得到的一个结果,其中恰巧包括几个“实际的词”。
![]()
有了足够多的英文文本,我们不仅可以对单个字母或字母对(二元字母)得到相当好的估计,而且可以对更长的字母串得到不错的估计。如果使用逐渐变长的 n 元(n-gram)字母的概率生成“随机的词”,就能发现它们会显得越来越“真实”。

英语中有大约50000个常用词。通过查看大型的英文语料库(比如几百万本书,总共包含几百亿个词),我们可以估计每个词的常用程度。使用这些信息,就可以开始生成“句子”了,其中的每个词都是独立随机选择的,概率与它们在语料库中出现的概率相同。以下是我们得到的一个结果。
![]()
毫不意外,这没有什么意义。那么应该如何做得更好呢?就像处理字母一样,我们可以不仅考虑单个词的概率,而且考虑词对或更长的 n 元词的概率。以下是考虑词对后得到的5个结果,它们都是从单词cat开始的。

结果看起来稍微变得更加“合理”了。可以想象,如果能够使用足够长的 n 元词,我们基本上会“得到一个ChatGPT”,也就是说,我们得到的东西能够生成符合“正确的整体文章概率”且像文章一样长的词序列。
但问题在于:我们根本没有足够的英文文本来推断出这些概率。
在网络爬取结果中可能有几千亿个词,在电子书中可能还有另外几百亿个词。但是,即使只有4万个常用词,可能的二元词的数量也已经达到了16亿,而可能的三元词的数量则达到了60万亿。因此,我们无法根据已有的文本估计所有这些三元词的概率。当涉及包含20个词的“文章片段”时,可能的20元词的数量会大于宇宙中的粒子数量,所以从某种意义上说,永远无法把它们全部写下来。
最佳思路是建立一个模型,让我们能够估计序列出现的概率—即使我们从未在已有的文本语料库中明确看到过这些序列。ChatGPT的核心正是所谓的“大语言模型”,后者已经被构建得能够很好地估计这些概率了。
3、什么是模型
假设你想(像16世纪末的伽利略一样)知道从比萨斜塔各层掉落的炮弹分别需要多长时间才能落地。当然,你可以在每种情况下进行测量并将结果制作成表格。不过,你还可以运用理论科学的本质:建立一个模型,用它提供某种计算答案的程序,而不仅仅是在每种情况下测量和记录。
假设我们只有数据,而不知道支配它的基本定律。那么我们可能会做出数学上的猜测,比如也许应该使用一条直线作为模型。

虽然我们可以选择不同的直线,但是上图中的这条直线平均而言最接近我们拥有的数据。根据这条直线,可以估计炮弹从任意一层落地的时间。我们怎么知道要在这里尝试使用直线呢?在某种程度上说,我们并不知道。它只是在数学上很简单,而且我们已经习惯了许多测量数据可以用简单的数学模型很好地拟合。还可以尝试更复杂的数学模型,比如 a+bx+cx^2,能看到它在这种情况下做得更好。

不过,这也可能会出大问题。例如,下面是我们使用a+b/x+c sinx 能得到的最好结果。

必须理解,从来没有“无模型的模型”。你使用的任何模型都有某种特定的基本结构,以及用于拟合数据的一定数量的“旋钮”(也就是可以设置的参数)。ChatGPT使用了许多这样的“旋钮”—实际上有1750亿个。
但是值得注意的是,ChatGPT的基本结构—“仅仅”用这么少的参数—足以生成一个能“足够好”地计算下一个词的概率的模型,从而生成合理的文章
4、类人任务(human-like task)的模型
上文提到的例子涉及为数值数据建立模型,这些数据基本上来自简单的物理学—几个世纪以来,我们已经知道可以用一些“简单的数学工具”为其建模。
但是对于ChatGPT,我们需要为人脑产生的人类语言文本建立模型。而对于这样的东西,我们(至少目前)还没有“简单的数学”可用。那么它的模型可能是什么样的呢?
让我们谈谈另一个类人任务:图像识别。一个简单的例子是包含数字的图像(这是机器学习中的一个经典例子)。
我们可以做的一件事是获取每个数字的大量样本图像。
要确定输入的图像是否对应于特定的数字,可以逐像素地将其与已有的样本进行比较。但是作为人类,我们似乎肯定做得更好:因为即使数字是手写的,有各种涂抹和扭曲,我们也仍然能够识别它们。

如果我们将图像中每个像素的灰度值视为变量 x,是否存在涉及所有这些变量的某个函数,能(在运算后)告诉我们图像中是什么数字?事实证明,构建这样的函数是可能的。不过难度也在意料之中,一个典型的例子可能涉及大约50万次数学运算。
如果函数给出的结果总是与人类的意见相符,那么我们就有了一个“好模型”。一个重大的科学事实是,对于图像识别这样的任务,我们现在基本上已经知道如何构建不错的函数了。
能“用数学证明”这些函数有效吗?不能。因为要做到这一点,我们必须拥有一个关于人类所做的事情的数学理论。
5、神经网络
用于图像识别等任务的典型模型到底是如何工作的呢?目前最受欢迎而且最成功的方法是使用神经网络。神经网络发明于20世纪40年代—它在当时的形式与今天非常接近—可以视作对大脑工作机制的简单理想化。
人类大脑有大约1000亿个神经元(神经细胞),每个神经元都能够产生电脉冲,最高可达每秒约1000次。这些神经元连接成复杂的网络,每个神经元都有树枝状的分支,从而能够向其他数千个神经元传递电信号。粗略地说,任意一个神经元在某个时刻是否产生电脉冲,取决于它从其他神经元接收到的电脉冲,而且神经元不同的连接方式会有不同的“权重”贡献。
当我们“看到一个图像”时,来自图像的光子落在我们眼睛后面的(光感受器)细胞上,它们会在神经细胞中产生电信号。这些神经细胞与其他神经细胞相连,信号最终会通过许多层神经元。在此过程中,我们“识别”出这个图像,最终“形成”我们“正在看数字2”的“想法”(也许最终会做一些像大声说出“二”这样的事情)。
上一节中的“黑盒函数”就是这样一个神经网络的“数学化”版本。它恰好有11层(只有4个“核心层”)。

我们对这个神经网络并没有明确的“理论解释”,它只是在1998年作为一项工程被构建出来的,而且被发现可以奏效。(当然,这与把我们的大脑描述为通过生物进化过程产生并没有太大的区别。)
好吧,但是这样的神经网络是如何“识别事物”的呢?关键在于吸引子(attractor)的概念。假设我们有手写数字1和2的图像。

我们希望通过某种方式将所有的1“吸引到一个地方”,将所有的2“吸引到另一个地方”。换句话说,如果一个图像“更有可能是1”而不是2,我们希望它最终出现在“1的地方”,反之亦然。
我们可以将这看成是执行一种“识别任务”,所做的不是识别一个给定图像“看起来最像”哪个数字,而是相当直接地看出哪个点距离给定的点最近。
那么如何让神经网络“执行识别任务”呢?让我们考虑下面这个非常简单的情况。

我们的目标是接收一个对应于位置 {x, y} 的输入,然后将其“识别”为最接近它的三个点之一。换句话说,我们希望神经网络能够计算出一个如下图所示的关于 {x, y} 的函数。

如何用神经网络实现这一点呢?归根结底,神经网络是由理想化的“神经元”组成的连接集合—通常是按层排列的。一个简单的例子如下所示。

每个“神经元”都被有效地设置为计算一个简单的数值函数。为了“使用”这个网络,我们只需在顶部输入一些数(像我们的坐标 x 和 y),然后让每层神经元“计算它们的函数的值”并在网络中将结果前馈,最后在底部产生最终结果。

在传统(受生物学启发)的设置中,每个神经元实际上都有一些来自前一层神经元的“输入连接”,而且每个连接都被分配了一个特定的“权重”(可以为正或为负)。给定神经元的值是这样确定的:先分别将其“前一层神经元”的值乘以相应的权重并将结果相加,然后加上一个常数,最后应用一个“阈值”(或“激活”)函数。
用数学术语来说,如果一个神经元有输入 x={x1, x2, ......},那么我们要计算 f[wx + b] 。对于权重w 和常量 b,通常会为网络中的每个神经元选择不同的值;函数 f 则通常在所有神经元中保持不变。
对于我们希望神经网络执行的每个任务(或者说,对于我们希望它计算的每个整体函数),都有不同的权重选择。(正如我们稍后将讨论的那样,这些权重通常是通过利用机器学习根据我们想要的输出的示例“训练”神经网络来确定的。)
最终,每个神经网络都只对应于某个整体的数学函数,尽管写出来可能很混乱。对于上面的例子,它是

同样,ChatGPT的神经网络也只对应于一个这样的数学函数—它实际上有数十亿项。
在每种情况下,我们都使用机器学习来找到最佳的权重选择。这里展示了神经网络用这些权重计算出的结果。

更大的神经网络通常能更好地逼近我们所求的函数。在“每个吸引子盆地的中心”,我们通常能确切地得到想要的答案。但在边界处,也就是神经网络“很难下定决心”的地方,情况可能会更加混乱。
在这个简单的数学式“识别任务”中,“正确答案”显而易见。但在识别手写数字的问题上,答案就不那么明显了。如果有人把2写得像7一样怎么办?类似的问题非常常见。尽管如此,我们仍然可以询问神经网络是如何区分数字的,下面给出了一个答案。

我们能“从数学上”解释网络是如何做出区分的吗?并不能。它只是在“做神经网络要做的事”。但是事实证明,这通常与我们人类所做的区分相当吻合。
无论输入什么,神经网络都会生成一个答案。结果表明,它的做法相当符合人类的思维方式。正如上面所说的,这并不是我们可以“根据第一性原则推导”出来的事实。这只是一些经验性的发现,至少在某些领域是正确的。但这是神经网络有用的一个关键原因:它们以某种方式捕捉了“类似人类”的做事方式。
找一张猫的图片看看,并问自己:“为什么这是一只猫?”你也许会说“我看到了它尖尖的耳朵”,等等。但是很难解释你是如何把这个图像识别为一只猫的。你的大脑就是不知怎么地想明白了。但是(至少目前还)没有办法去大脑“内部”看看它是如何想明白的。那么,对于(人工)神经网络呢?当你展示一张猫的图片时,很容易看到每个“神经元”的作用。不过,即使要对其进行基本的可视化,通常也非常困难。
在上面用于解决“最近点”问题的最终网络中,有17个神经元;在用于识别手写数字的网络中,有2190个神经元;而在用于识别猫和狗的网络中,有60650个神经元。通常很难可视化出60650维的空间。但由于这是一个用于处理图像的网络,其中的许多神经元层被组织成了数组,就像它查看的像素数组一样。
下面以一个典型的猫的图像为例。

我们可以用一组衍生图像来表示第一层神经元的状态,其中的许多可以被轻松地解读为“不带背景的猫”或“猫的轮廓”。

到第10层,就很难解读这些是什么了。

总的来说,我们可以说神经网络正在“挑选出某些特征”(也许尖尖的耳朵是其中之一),并使用这些特征来确定图像的内容。但是,这些特征能否用语言描述出来(比如“尖尖的耳朵”)呢?大多数情况下不能。
我们的大脑是否使用了类似的特征呢?我们多半并不知道。但值得注意的是,一些神经网络(像上面展示的这个)的前几层似乎会挑选出图像的某些方面(例如物体的边缘),而这些方面似乎与我们知道的大脑中负责视觉处理的第一层所挑选出的相似。
假设我们想得到神经网络中的“猫识别理论”,可以说:“看,这个特定的网络可以做到这一点。”这会立即让我们对“问题的难度”有一些了解(例如,可能需要多少个神经元或多少层)。但至少到目前为止,我们没办法对网络正在做什么“给出语言描述”。也许这是因为它确实是计算不可约的,除了明确跟踪每一步之外,没有可以找出它做了什么的一般方法。也有可能只是因为我们还没有“弄懂科学”,也没有发现能总结正在发生的事情的“自然法则”。
当使用ChatGPT生成语言时,我们会遇到类似的问题,而且目前尚不清楚是否有方法来“总结它所做的事情”。但是,语言的丰富性和细节(以及我们的使用经验)可能会让我们比图像处理取得更多进展。
6、机器学习和神经网络的训练
神经网络之所以很有用(人脑中的神经网络大概也如此),原因不仅在于它可以执行各种任务,还在于它可以通过逐步“根据样例训练”来学习执行这些任务。
当构建一个神经网络来区分猫和狗的图像时,我们不需要编写一个程序来(比如)明确地找到胡须,只需要展示很多关于什么是猫和什么是狗的样例,然后让神经网络从中“机器学习”如何区分它们即可。
重点在于,已训练的神经网络能够对所展示的特定例子进行“泛化”。正如我们之前看到的,神经网络不仅能识别猫图像的样例的特定像素模式,还能基于我们眼中的某种“猫的典型特征”来区分图像。
神经网络的训练究竟是如何起效的呢?本质上,我们一直在尝试找到能使神经网络成功复现给定样例的权重。然后,我们依靠神经网络在这些样例“之间”进行“合理”的“插值”(或“泛化”)。
让我们看一个比“最近点”问题更简单的问题,只试着让神经网络学习如下函数。

对于这个任务,我们需要只有一个输入和一个输出的神经网络。

但是,应该使用什么样的权重呢?对于每组可能的权重,神经网络都将计算出某个函数。例如,下面是它对于几组随机选择的权重计算出的函数。

可以清楚地看到,这些函数与我们想要的函数相去甚远。那么,如何才能找到能够复现函数的权重呢?
基本思想是提供大量的“输入→输出”样例以供“学习”,然后尝试找到能够复现这些样例的权重。以下是逐渐增加样例后所得的结果。

在该“训练”的每个阶段,都会逐步调整神经网络的权重,我们会发现最终得到了一个能成功复现我们想要的函数的神经网络。应该如何调整权重呢?基本思想是,在每个阶段看一下我们离想要的函数“有多远”,然后朝更接近该函数的方向更新权重。
为了明白离目标“有多远”,我们计算“损失函数”(有时也称为“成本函数”)。这里使用了一个简单的(L2)损失函数,就是我们得到的值与真实值之间的差异的平方和。随着训练过程不断进行,我们看到损失函数逐渐减小(遵循特定的“学习曲线”,不同任务的学习曲线不同),直到神经网络成功地复现(或者至少很好地近似)我们想要的函数。

结果表明,微积分的链式法则实际上让我们解开了神经网络中连续各层所做操作的谜团。结果是,我们可以—至少在某些局部近似中—“反转”神经网络的操作,并逐步找到使与输出相关的损失最小化的权重。
事实证明,即使有更多的权重(ChatGPT使用了1750亿个权重),也仍然可以进行最小化,至少可以在某种程度上进行近似。实际上,“深度学习”在2012年左右的重大突破与如下发现有关:与权重相对较少时相比,在涉及许多权重时,进行最小化(至少近似)可能会更容易。
换句话说,有时候用神经网络解决复杂问题比解决简单问题更容易—这似乎有些违反直觉。大致原因在于,当有很多“权重变量”时,高维空间中有“很多不同的方向”可以引导我们到达最小值;而当变量较少时,很容易陷入局部最小值的“山湖”,无法找到“出去的方向”。
在典型情况下,有许多不同的权重集合可以使神经网络具有几乎相同的性能。在实际的神经网络训练中,通常会做出许多随机选择,导致产生一些“不同但等效”的解决方案,就像下面这些一样。

但是每个这样的“不同解决方案”都会有略微不同的行为。假如在我们给出训练样例的区域之外进行“外插”(extrapolation),可能会得到截然不同的结果。

哪一个是“正确”的呢?实际上没有办法确定。它们都“与观察到的数据一致”。但它们都对应着“在已知框架外”进行“思考”的不同的“固有方式”。只是有些方式对我们人类来说可能“更合理”。
7、神经网络训练的实践和学问
在过去的十年中,神经网络训练的艺术已经有了许多进展。是的,它基本上是一门艺术。
在越来越多的情况下,人们并不从头开始训练网络:一个新的网络可以直接包含另一个已经训练过的网络,或者至少可以使用该网络为自己生成更多的训练样例。
有人可能会认为,每种特定的任务都需要不同的神经网络架构。但事实上,即使对于看似完全不同的任务,同样的架构通常也能够起作用。在某种程度上,这让人想起了通用计算(universal computation)的概念和我的计算等价性原理(Principle of Computational Equivalence)
在神经网络的早期发展阶段,人们倾向于认为应该“让神经网络做尽可能少的事”。例如,在将语音转换为文本时,人们认为应该先分析语音的音频,再将其分解为音素,等等。但是后来发现,(至少对于“类人任务”)最好的方法通常是尝试训练神经网络来“解决端到端的问题”,让它自己“发现”必要的中间特征、编码等。
还有一种想法是,应该将复杂的独立组件引入神经网络,以便让它有效地“显式实现特定的算法思想”。但结果再次证明,这在大多数情况下并不值得;相反,最好只处理非常简单的组件,并让它们“自我组织”(尽管通常是以我们无法理解的方式)来实现(可能)等效的算法思想。
这并不意味着没有与神经网络相关的“结构化思想”。例如,至少在处理图像的最初阶段,拥有局部连接的神经元二维数组似乎非常有用。而且,拥有专注于“在序列数据中‘回头看’”的连接模式在处理人类语言方面,例如在ChatGPT中,似乎很有用(后面我们将看到)。
神经网络的一个重要特征是,它们说到底只是在处理数据—和计算机一样。目前的神经网络及其训练方法具体处理的是由数组成的数组,但在处理过程中,这些数组可以完全重新排列和重塑。例如,前面用于识别数字的网络从一个二维的“类图像”数组开始,迅速“增厚”为许多通道,但然后会“浓缩”成一个一维数组,最终包含的元素代表可能输出的不同数字。

但是,如何确定特定的任务需要多大的神经网络呢?这有点像一门艺术。在某种程度上,关键是要知道“任务有多难”。但是类人任务的难度通常很难估计。是的,可能有一种系统化的方法可以通过计算机来非常“机械”地完成任务,但是很难知道是否有一些技巧或捷径有助于更轻松地以“类人水平”完成任务。可能需要枚举一棵巨大的对策树才能“机械”地玩某个游戏,但也可能有一种更简单的(“启发式”)方法来实现“类人的游戏水平”。
当处理微小的神经网络和简单任务时,有时可以明确地看到“无法从这里到达那里”。

我们看到的是,如果神经网络太小,它就无法复现我们想要的函数。但是只要超过某个大小,它就没有问题了—前提是至少训练足够长的时间,提供足够的样例。顺便说一句,这些图片说明了神经网络学问中的一点:如果中间有一个“挤压”(squeeze),迫使一切都通过中间较少的神经元,那么通常可以使用较小的网络。[值得一提的是,“无中间层”(或所谓的“感知机”)网络只能学习基本线性函数,但是只要有一个中间层(至少有足够的神经元),原则上就始终可以任意好地逼近任何函数,尽管为了使其可行地训练,通常会做某种规范化或正则化。]
为特定的任务训练神经网络需要多少数据?根据第一性原则很难估计。使用“迁移学习”可以将已经在另一个神经网络中学习到的重要特征列表“迁移过来”,从而显著降低对数据规模的要求。但是,神经网络通常需要“看到很多样例”才能训练好。至少对于某些任务而言,神经网络学问中很重要的一点是,样例的重复可能超乎想象。事实上,不断地向神经网络展示所有的样例是一种标准策略。在每个“训练轮次”(training round或epoch)中,神经网络都会处于至少稍微不同的状态,而且向它“提醒”某个特定的样例对于它“记忆该样例”是有用的。(是的,这或许类似于重复在人类记忆中的有用性。)
神经网络的实际学习过程是怎样的呢?归根结底,核心在于确定哪些权重能够最好地捕捉给定的训练样例。有各种各样的详细选择和“超参数设置”(之所以这么叫,是因为权重也称为“参数”),可以用来调整如何进行学习。有不同的损失函数可以选择,如平方和、绝对值和,等等。有不同的损失最小化方法,如每一步在权重空间中移动多长的距离,等等。然后还有一些问题,比如“批量”(batch)展示多少个样例来获得要最小化的损失的连续估计。是的,我们可以(像在Wolfram语言中所做的一样)应用机器学习来自动化机器学习,并自动设置超参数等。
能确定“学习曲线”要多久才能趋于平缓吗?似乎也存在一种取决于神经网络大小和数据量的近似幂律缩放关系。但总的结论是,训练神经网络很难,并且需要大量的计算工作。实际上,绝大部分工作是在处理数的数组,这正是GPU擅长的—这也是为什么神经网络训练通常受限于可用的GPU数量。
神经网络的基本思想是利用大量简单(本质上相同)的组件来创建一个灵活的“计算结构”,并使其能够逐步通过学习样例得到改进。在当前的神经网络中,基本上是利用微积分的思想(应用于实数)来进行这种逐步的改进。但越来越清楚的是,重点并不是拥有高精度数值,即使使用当前的方法,8位或更少的数也可能已经足够了。
8、“足够大的神经网络当然无所不能!”
但我们从科学在过去几百年间的发展中得出的教训是,有些事物虽然可以通过形式化的过程来弄清楚,但并不容易立即为人类思维所理解。
我们通常用大脑做的那类事情,大概是为了避免计算不可约性而特意选择的。在大脑中进行数学运算需要特殊的努力。而且在实践中,仅凭大脑几乎无法“想透”任何非平凡程序的操作步骤。
说到底,可学习性和计算不可约性之间存在根本的矛盾。学习实际上涉及通过利用规律来压缩数据,但计算不可约性意味着最终对可能存在的规律有一个限制。
换句话说,能力和可训练性之间存在着一个终极权衡:你越想让一个系统“真正利用”其计算能力,它就越会表现出计算不可约性,从而越不容易被训练;而它在本质上越易于训练,就越不能进行复杂的计算。
9、“嵌入”的概念
神经网络,至少以目前的设置来说,基本上是基于数的。因此,如果要用它来处理像文本这样的东西,我们需要一种用数表示文本的方法。当然,我们可以(本质上和ChatGPT一样)从为字典中的每个词分配一个数开始。但有一个重要的思想—也是ChatGPT的中心思想—更胜一筹。这就是“嵌入”(embedding)的思想。可以将嵌入视为一种尝试通过数的数组来表示某些东西“本质”的方法,其特性是“相近的事物”由相近的数表示。

大致的想法是查看大量的文本(这里查看了来自互联网的50亿个词),然后看看各个词出现的“环境”有多“相似”。例如,alligator(短吻鳄)和crocodile(鳄鱼)在相似的句子中经常几乎可以互换,这意味着它们将在嵌入中被放在相近的位置。但是,turnip(芜菁)和eagle(鹰)一般不会出现在相似的句子中,因此将在嵌入中相距很远。
我们可以将该网络想象成由11个连续的层组成,并做如下简化(将激活函数显示为单独的层)。
![]()
在开始,我们将实际图像输入第一层,这些图像由其像素值的二维数组表示。在最后,我们(从最后一层)得到一个包含10个值的数组,可以认为这些值表示网络对图像与数字0到9的对应关系的确定程度。
最终,我们必须用数来表述一切。一种方法是为英语中约50000个常用词分别分配一个唯一的数。例如,分配给the的可能是914,分配给cat的可能是3542。(这些是GPT-2实际使用的数。)因此,对于“the ___cat”的问题,我们的输入可能是 {914, 3542}。输出应该是什么样的呢?应该是一个大约包含50000个数的列表,有效地给出了每个可能“填入”的词的概率。为了找到嵌入,我们再次在神经网络“得到结论”之前“拦截”它的“内部”进程,然后获取此时的数字列表,可以认为这是“每个词的表征”。
这些表征是什么样子的呢?在过去10年里,已经出现了一系列不同的系统(word2vec、GloVe、BERT、GPT……),每个系统都基于一种不同的神经网络方法。但最终,所有这些系统都是通过有几百到几千个数的列表对词进行表征的。
这些“嵌入向量”在其原始形式下是几乎无信息的。例如,下面是GPT-2为三个特定的词生成的原始嵌入向量。

如果测量这些向量之间的距离,就可以找到词之间的“相似度”。可以对词序列甚至整个文本块进行这样的表征。ChatGPT内部就是这样进行处理的。它会获取到目前为止的所有文本,并生成一个嵌入向量来表示它。然后,它的目标就是找到下一个可能出现的各个词的概率。它会将答案表示为一个数字列表,这些数基本上给出了大约50000个可能出现的词的概率。
[严格来说,ChatGPT并不处理词,而是处理“标记”(token)—这是一种方便的语言单位,既可以是整个词,也可以只是像pre、ing或ized这样的片段。使用标记使ChatGPT更容易处理罕见词、复合词和非英语词,并且会发明新单词(不论结果好坏)。]
10、ChatGPT的内部原理
从根本上说,ChatGPT是一个庞大的神经网络— GPT-3拥有1750亿个权重。它在许多方面非常像我们讨论过的其他神经网络,只不过是一个特别为处理语言而设置的神经网络。它最显著的特点是一个称为Transformer的神经网络架构。
在前面讨论的神经网络中,任何给定层的每个神经元基本上都与上一层的每个神经元相连(起码有一些权重)。但是,如果处理的数据具有特定的已知结构,则这种全连接网络就(可能)大材小用了。因此,以图像处理的早期阶段为例,通常使用所谓的卷积神经网络(convolutional neural net或convnet),其中的神经元被有效地布局在类似于图像像素的网格上,并且仅与在网格上相邻的神经元相连。
Transformer的思想是,为组成一段文本的标记序列做与此相似的事情。但是,Transformer不是仅仅定义了序列中可以连接的固定区域,而是引入了“注意力”的概念—即更多地“关注”序列的某些部分,而不是其他部分。也许在将来的某一天,可以启动一个通用神经网络并通过训练来完成所有的定制工作。但至少目前来看,在实践中将事物“模块化”似乎是至关重要的—就像Transformer所做的那样,也可能是我们的大脑所做的那样。
它的操作分为三个基本阶段。第一阶段,它获取与目前的文本相对应的标记序列,并找到表示这些标记的一个嵌入(即由数组成的数组)。第二阶段,它以“标准的神经网络的方式”对此嵌入进行操作,值“像涟漪一样依次通过”网络中的各层,从而产生一个新的嵌入(即一个新的数组)。第三阶段,它获取此数组的最后一部分,并据此生成包含约50000个值的数组,这些值就成了各个可能的下一个标记的概率。(没错,使用的标记数量恰好与英语常用词的数量相当,尽管其中只有约3000个标记是完整的词,其余的则是片段。)
关键是,这条流水线的每个部分都由一个神经网络实现,其权重是通过对神经网络进行端到端的训练确定的。换句话说,除了整体架构,实际上没有任何细节是有“明确设计”的,一切都是从训练数据中“学习”来的。
注意力头是做什么的呢?它们基本上是一种在标记序列(即目前已经生成的文本)中进行“回顾”的方式,能以一种有用的形式“打包过去的内容”,以便找到下一个标记。在“概率从何而来”一节中,我们介绍了使用二元词的概率来根据上一个词选择下一个词。Transformer中的“注意力”机制所做的是允许“关注”更早的词,因此可能捕捉到(例如)动词可以如何被联系到出现在句子中很多词之前的名词。
在经过所有这些注意力块后,Transformer的实际效果是什么?本质上,它将标记序列的原始嵌入集合转换为最终集合。ChatGPT的特定工作方式是,选择此集合中的最后一个嵌入,并对其进行“解码”,以生成应该出现的下一个标记的概率列表。
在像ChatGPT这样的神经网络中,能以某种方式捕捉到人类大脑在生成语言时所做事情的本质。
11、ChatGPT的训练
基本上,这是基于包含人类所写文本的巨型语料库(来自互联网、书籍等),通过大规模训练得出的结果。正如我们所说,即使有所有这些训练数据,也不能肯定神经网络能够成功地产生“类人”文本。似乎需要细致的工程设计才能实现这一点。但是,ChatGPT带来的一大惊喜和发现是,它完全可以做到。实际上,“只有1750亿个权重”的神经网络就可以构建出人类所写文本的一个“合理模型”。
那么需要多少样例才能训练出“类人语言”模型呢?似乎无法通过任何基本的“理论”方法知道。但在实践中,ChatGPT成功地在包含几百亿个词的文本上完成了训练。
12、在基础训练之外
一旦根据被展示的原始文本语料库完成“原始训练”,ChatGPT内部的神经网络就会准备开始生成自己的文本,根据提示续写,等等。尽管这些结果通常看起来合理,但它们很容易(特别是在较长的文本片段中)以“非类人”的方式“偏离正轨”。这不是通过对文本进行传统的统计可以轻易检测到的。但是,实际阅读文本的人很容易注意到。
值得再次指出的是,神经网络在捕捉信息方面不可避免地存在“算法限制”。如果告诉它类似于“从这个到那个”等“浅显”的规则,神经网络很可能能够不错地表示和重现这些规则,并且它“已经掌握”的语言知识将为其提供一个立即可用的模式。但是,如果试图给它实际的“深度”计算规则,涉及许多可能计算不可约的步骤,那么它就行不通了。(请记住,它在每一步都只是在网络中“向前馈送数据”,除非生成新的标记,否则它不会循环。)
13、真正让ChatGPT发挥作用的是什么
人类大脑“仅”有约1000亿个神经元(及约100万亿个连接),却能够做到这一切,确实令人惊叹。人们可能会认为,大脑中不只有神经元网络,还有某种具有尚未发现的物理特性的新层。但是有了ChatGPT之后,我们得到了一条重要的新信息:一个连接数与大脑神经元数量相当的纯粹的人工神经网络,就能够出色地生成人类语言。
那么,ChatGPT是如何在语言方面获得如此巨大成功的呢?我认为基本答案是,语言在根本上比它看起来更简单。这意味着,即使是具有简单的神经网络结构的ChatGPT,也能够成功地捕捉人类语言的“本质”和背后的思维方式。此外,在训练过程中,ChatGPT已经通过某种方式“隐含地发现”了使这一切成为可能的语言(和思维)规律。
14、意义空间和语义运动定律
ChatGPT续写一段文本,就相当于在语言特征空间中追踪一条轨迹。现在我们会问:是什么让这条轨迹与我们认为有意义的文本相对应呢?是否有某种“语义运动定律”定义(或至少限制)了语言特征空间中的点如何在保持“有意义”的同时到处移动?

再看一个例子,下图展示了不同词性的词是如何布局的。

通过观察包含一个词的句子在特征空间中的布局,人们通常可以“分辨出”它们不同的含义。
但目前,我们还没有准备好从它的“内部行为”中“实证解码”ChatGPT已经“发现”的人类语言的“组织”规律。
15、语义语法和计算语言的力量
我们可以将计算语言—和语义语法—的构建看作一种在表示事物方面的终极压缩。因为它使我们不必(比如)处理存在于普通人类语言中的所有“措辞”,就能够谈论可能性的本质。可以认为ChatGPT的巨大优势与之类似:因为它也在某种意义上“钻研”到了,不必考虑可能的不同措辞,就能“以语义上有意义的方式组织语言”的地步。
16、那么,ChatGPT到底在做什么?它为什么能做到这些?
ChatGPT的基本概念在某种程度上相当简单:首先从互联网、书籍等获取人类创造的海量文本样本,然后训练一个神经网络来生成“与之类似”的文本。特别是,它能够从“提示”开始,继续生成“与其训练数据相似的文本”。
但是就目前而言,看到ChatGPT已经能够做到的事情是非常令人兴奋的。在某种程度上,它是一个极好的例子,说明了大量简单的计算元素可以做出非凡、惊人的事情。它也为我们提供了2000多年以来的最佳动力,来更好地理解人类条件(human condition)的核心特征—人类语言及其背后的思维过程—的本质和原则。
——作者斯蒂芬·沃尔弗拉姆(Stephen Wolfram)