阿里云人工智能ACA认证(8)—智能语音技术基础
2025-05
浏览量:542
本文字数:1862
读完约 7 分钟
一、智能语音技术概述
通过对语音进行分析、理解和合成,使计算机设备实现“能听会说”、具备自然语言交流的技术能力。
其涉及范围主要有:
语音合成技术
语音识别技术
语音测评技术
语音降噪与增强技术
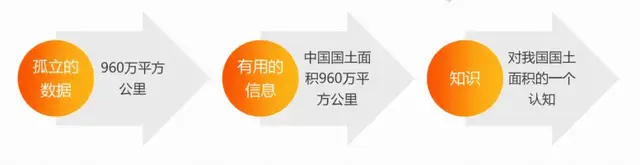
研究任务:
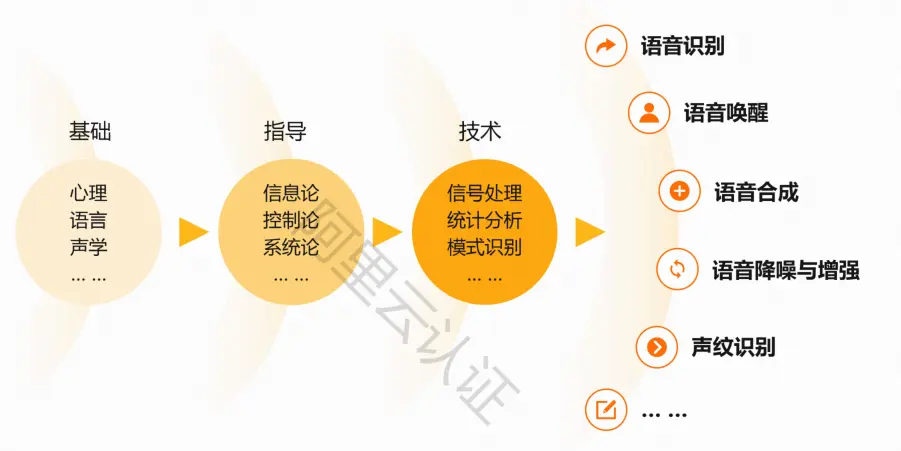
研究难点:
涉及到很多领域,需要掌握各领域的基础知识、掌握很多技能才能实用化
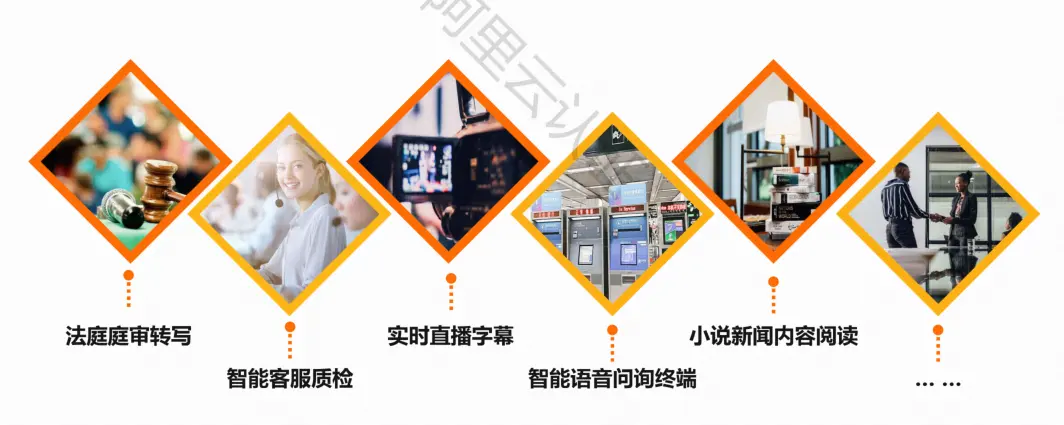
应用场景:
二、智能语音技术处理对象
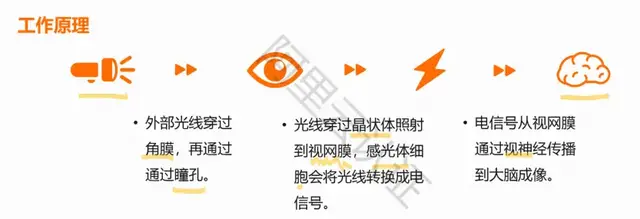
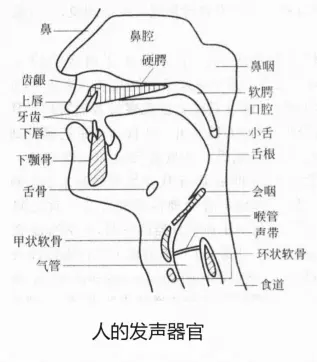
人的发声:肺部呼出的气流透过支气管到达喉头,引发喉头中声带的颤动,振动产生声音,再由口腔或鼻腔控制发声位置。
声音是由物体振动产生的声波,是通过介质(空气或固体、液体)传播并能被人或动物听觉器官所感知的波动现象。
可以被人耳识别的声波频率在 20Hz~20000Hz 之间
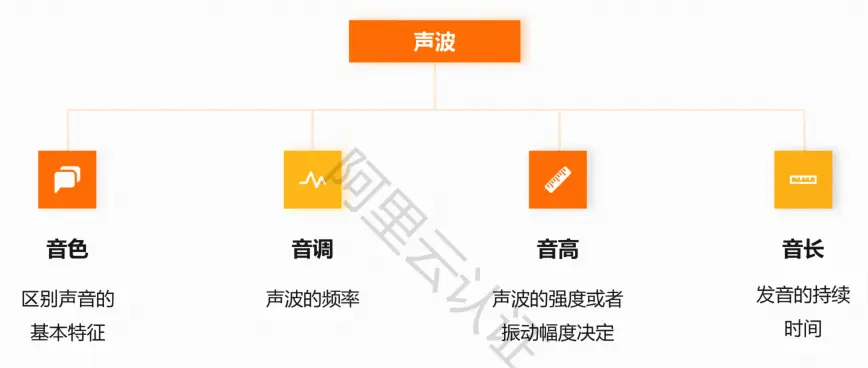
语音的物理载体是一种声波,声波的特征属性包括:
语音的内涵:
人类语言的物质表达
语言的外部形式
最直接地记录人的思维活动的符号体系
人的发音器官发出的具有一定社会意义的声音
语音是声音和语言的组合体
语音是一段语音序列携带语言信息的声音
音节是能够自然发出和觉察到的最小语音单位
一个音节由一个或几个元音和辅音按照一定的规则组织起来

语音信号
语音的基本模拟形式为语音信号的声波波形
语音信号在产生过程中与环境和发声器官的联系很紧密,与各种运动都是相关的,语音信号本身是不平稳的信号
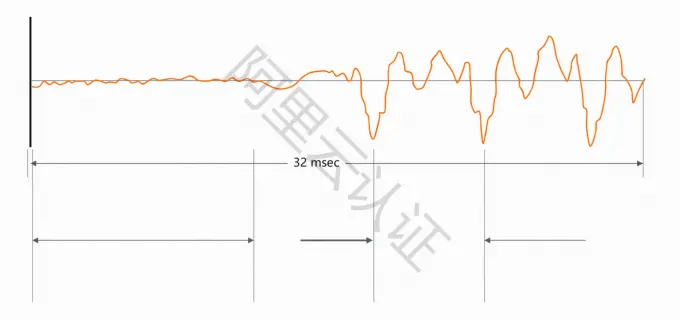
语音信号的特点
通过麦克风转换成电子波形
通过模拟/数字信号处理操作
由扬声器或耳机转换回声学形式

语音信号处理:
将一种语音信号表示形式转换为另一种语音信号,以揭示语音信号的各种数学或实际性质,并进行适当的处理,以帮助解决基本问题和深层问题
语音信号处理的目的:
理解语音是一种交流的手段
语音的传播和复制
对语音进行分析,以便自动识别和提取信息
发现说话者的一些生理特征
计算机音频
音频文件参数:
声道:
录制声音时,在不同空间位置采集的相互独立的音频信号。声道数也就是声音录制时的音源数量。常见的音频数据为单声道或双声道(立体声)
比特率:
数据传输时单位时间传送的数据位数,也就是每秒的传输速率。比特率越高,传送数据速度越快
音频采样率:
是指录音设备在一秒钟内对声音信号的采样次数,采样频率越高声音的还原就越真实自然
音频采样位数:
采样值或取样值,即是将采样样本幅度量化。用来衡量声音波动变化的参数,或是声卡的分辨率。数值越大、分辨率越高,发出声音的能力越强
音频编码
语音数据存储和传输的方式
在调用智能语音交互服务之前需确认语音数据编码格式是服务所支持的

三、智能语音相关技术
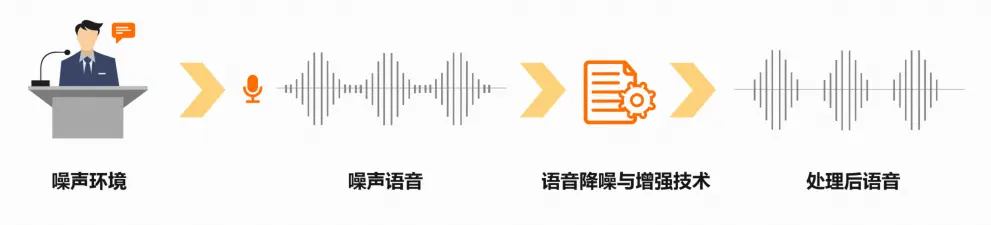
语音降噪与增强
尽可能地从带噪声的语音信号中提取有用语音信号,抑制或降低噪声干扰的技术
降低背景噪声干扰,改善语音质量,提升听者的舒适感
提高语音信息传达的可懂度
传统信号处理方法
实现原理:
基于物理和数学原理推导,适用性强,所以系统一般有比较好的鲁棒性
使用环境:
传统信号处理方法一般具有小计算量、低延迟等优势,容易满足实时性要求
1,基于单通道的语音降噪与增强方法
2,基于麦克风阵列的语音降噪与增强方法

深度学习方法
实现原理:
利用大量的语音数据或噪声数据,训练网络学习相关的特征从而实现降噪,性能变化范围较大,系统在新环境下鲁棒性较差
使用环境:
模型及计算资源等问题一方面会限制其在计算资源有限的系统中的使用,另一方面难以保证实时通信需求

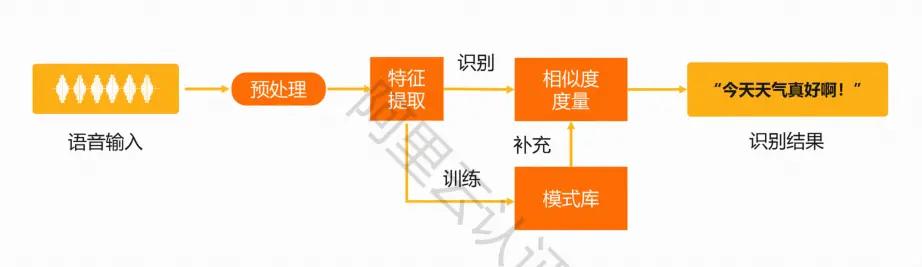
语音识别
语音识别技术就是“机器的听觉系统”
让机器通过识别和理解,把语音信号转变为相应的文本或命令

语音识别技术的本质是一种基于语音特征参数的识别
通过学习,系统能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果
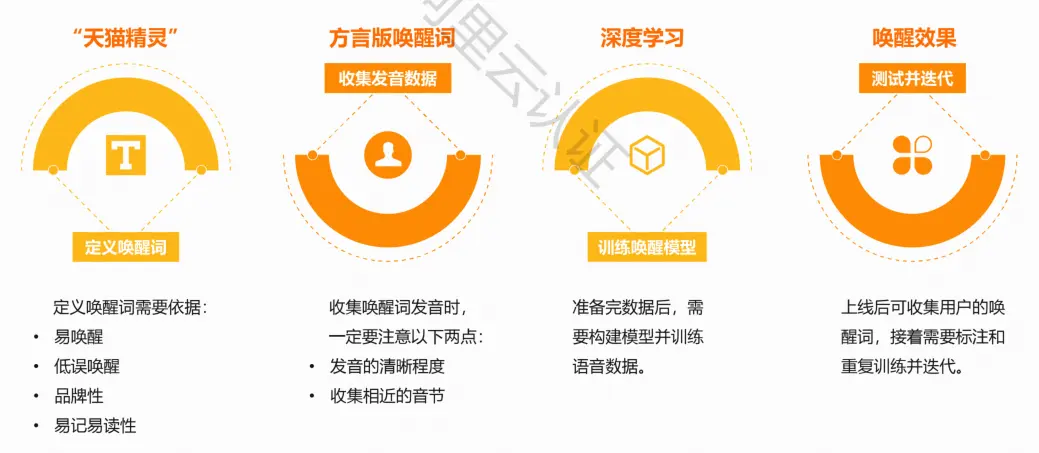
语音唤醒
关键词检测
在一串语音流中,检测出预先定义的激活词或关键词,而不需要对所有的语音进行识别
语音唤醒模型的实现流程
语音合成
一种通过机械的、电子的方法产生人造语音的技术
又称文语转换
可将任意输入文本转换成相应语音
可将基本语音信息数字化,并利用计算机系统仿真出人类的声音

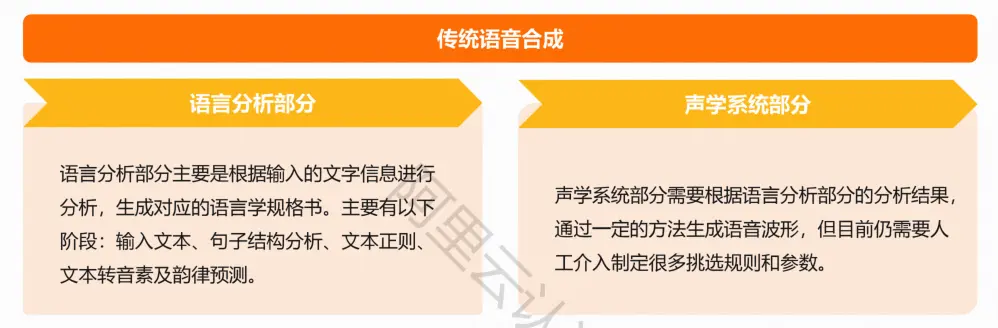
合成原理
传统语音合成
端到端语音合成

四、智能语音交互概述
人机交互趋势
人类通过语音交流与机器进行信息传递的活动
基于语音识别、语音合成、自然语言理解等技术
优势:
信息传递效率:相比较于键盘输入,语音输入在4类场景中,速度及准确率方面更具优势
使用门槛低:语音交互学习成本低,且可为障碍群体带来极大的便利
传递声学信息:依靠声音可以判断性别、年龄层、情绪等信息
劣势:
语音交互无法像文字一样可以跳读,同时会增加用户的记忆负担
嘈杂环境的影响:嘈杂环境使得人声的提取变得非常困难
公开环境的影响:公开环境下进行语音交互具有心理负担
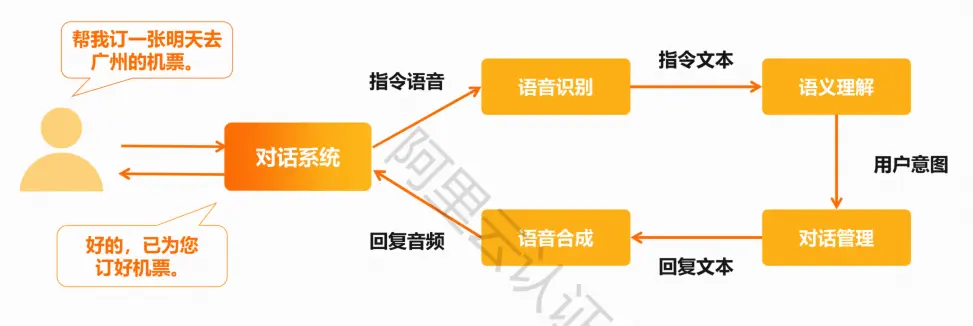
智能对话系统
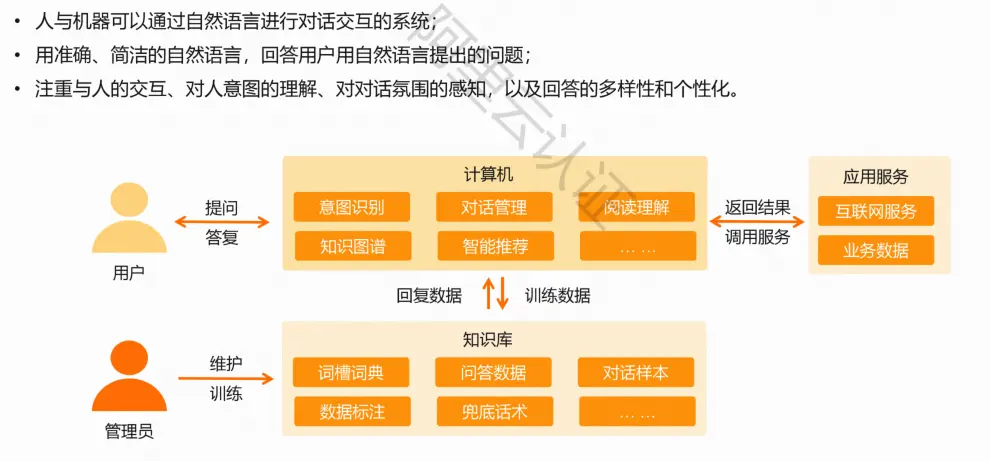
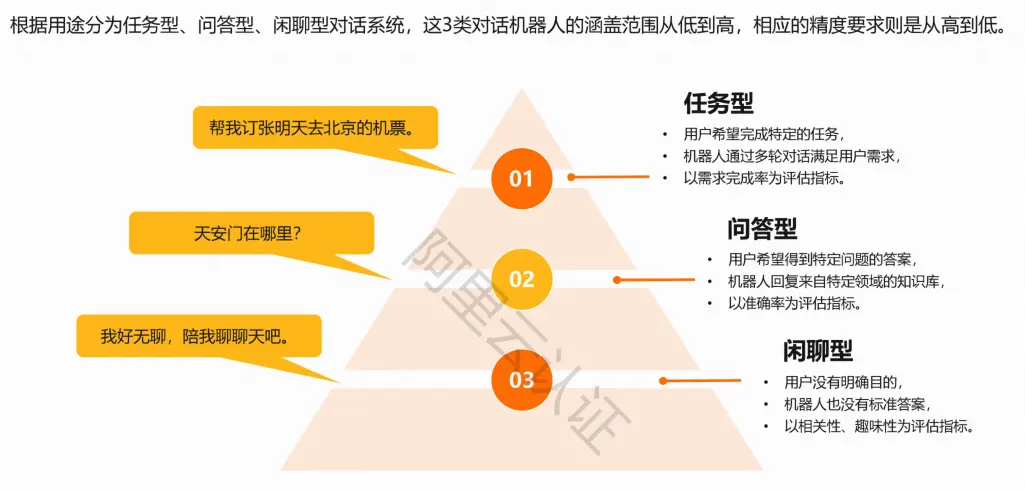
智能对话系统可分为任务型、问答型、闲聊型
发展趋势:快速适应、深度理解、保护隐私


智能对话系统的实现流程
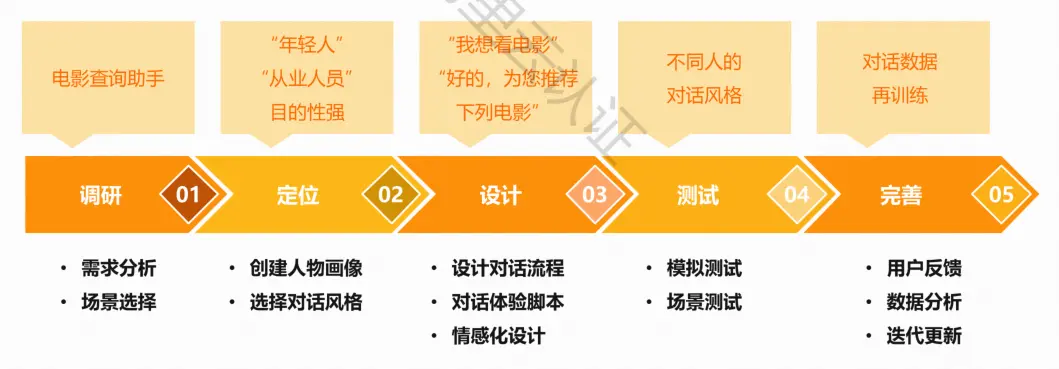
技术应用: