阿里云人工智能ACA认证(6)—计算机视觉基础
2025-05
浏览量:556
本文字数:3407
读完约 12 分钟
一、计算机视觉概述
定义:计算机视觉是一门研究如何使机器“看”的科学,也可以看作是研究如何使人工系统从图像或多维数据中“感知”的科学
目标:计算机视觉成为机器认知世界的基础,终极目的是使得计算机能够像人一样“看懂世界”
计算机视觉的优势
在图像处理上,实现超人类的准确性;例如图片颜色、细节敏感度
在细微变化识别上,性能远胜于人类;例如医疗图像分析
在计算能力上,速度与精确性完胜人类;例如超级计算机
与人类视觉的区别
眼睛看到图像—经过神经传导大脑—大脑分析判断

计算机视觉与人类视觉具有相似的结构
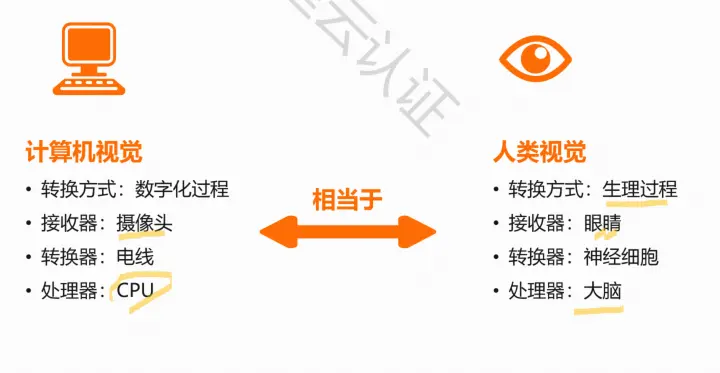
不同点:
人类的眼睛比摄像机更加灵活
人类的神经更加复杂
计算机视觉可以获取人类视觉获取不到的信息,如红外摄像机
计算机视觉可以到人类到不了的地方,如太空作业
计算机视觉的典型应用
视频审核、视频AI
二、计算机视觉的基本原理
数字图像:
用一个数字矩阵来表达客观物体的图像
由模拟图像数字化得到
离散采样点的集合,每个点具有其各自的属性
以像素为基本元素的图像
数字图像处理:
图像变换
图像增强
图像恢复
图像压缩编码
图像分割
图像分析与描述
图像的识别分类
图像数字化的两个过程
采样、量化


关键技术
图像分类:
给定一组各自被标记为单一类别的图像,对一组新的测试图像的类别进行预测,并测量预测的准确性结果
目标检测:
给定一张图像,让计算机找出其中所有目标的位置,并给出每个目标的具体类别
语义分割:
将整个图像分成像素组,然后对像素组进行标记和分类
语义分割是在语义上理解图像中每个像素是什么,还须确定每个物体的边界
如一张“人驾驶摩托车行驶在林间小道上”的图片
实例分割:
在语义分割的基础上进行,将多个重叠物体和不同背景的复杂景象进行分类
同时确定对象的边界、差异和彼此之间的关系
视频分类:
分类的对象是由多帧图像构成的、包含语音数据、运动信息等的视频对象
需要理解每帧图像包含内容,还需要知道上下文关联信息
人体关键点检测:
通过人体关键点的组合和追踪来识别人的运动和行为
对于描述人体姿态,预测人体行为至关重要
场景文字识别:
在图像背景复杂、分辨率低下、字体多样、分布随意等情况下,将图像信息转化为文字序列的过程
目标跟踪:
在特定场景跟踪某一个或多个特定感兴趣对象的过程
三、图像分类基础
图像分类的核心是从给定的分类集合中给图像分配一个标签
图像分类模型读取该图片
生成该图片属于集合{ }中各个标签的概率

根据大类、小类加标签
可以单个、多个标签
不同的标签粒度和个数会形成不同的分类任务
单标签与多标签分类的区别
单标签:
数据样本属于一个大类的
数据进行分类后可以用一个值代表
单标签内有二分类和多分类
例如:单标签三个样本的二分类整形(0/1)输出为 [0, 1, 0]
多标签:
数据样本可以划分到几个大的不冲突主题类别中
在大主题中分别可以进行二分类和多分类问题
例如:多标签(假设为两个标签)三个样本的二分类整形输出为:[[0, 1], [0, 1], [0, 1]]
跨物种语义级别的图像分类
在不同物种层次上识别不同类别的对象
各个类别之间属于不同的物种或大类,往往具有较大的类间方差,而类内具有较小的类内方差
多类别图像分类由传统的特征提取方法转到数据驱动的深度学习方向来,取得了较大进展

子类细粒度图像分类
子类细粒度分类相较于跨物种图像分类难度更大
是一个大类中的子类的分类,如不同鸟的分类
在区分出基本类别的基础上,进行更精细的子类划分
由于图像之间具有更加相似的外观和特征,受采集过程中存在干扰影响,导致数据呈现类间差异性大,类内间差异小,分类难度更高

多标签图像分类
给每个样本一系列的目标标签,表示的是样本各属性且不相互排斥的,预测出一个概念集合
标签树林较大且复杂
标签的标准很难统一,且往往类标之间相互依赖并不独立
标注的标签并不能完美覆盖所有概念面
标签往往较短语义少,理解困难

图像分类的挑战
类别不均衡
数据集小
巨大的类内差异
实际应用环境复杂
图像分类的常用数据集:CIFAR-10
一个用于识别普适物体的小型图像数据集
包含6万张大小为32x32的彩色图像
共有10个类,每类6000张图
共5万张图组成训练集合,训练集合中每一类均等5000张图
1万张图组成测试集合,测试集合中每一类均等1000张图
10个类别:飞机、汽车、鸟类、猫、鹿、狗、蛙类、马、船、卡车
类是完全互斥的,在一个类别中出现的图片不会出现在其它类中
使用的相关神经网络:Lenet-5、AlexNet
典型应用
图片搜索引擎:
通过用户上传图片,应用图像分类计数,识别图中的内容并进行分类
搜索互联网上与这张图片相同或相似信息的其他图片资源进行校对和匹配,识别图中的内容并提供相关信息

四、目标检测基础
目标检测就是识别图中有哪些物体,确定他们的类别并标出各自在图中的位置
目标检测模型读取该图片
寻找识别出图中的物体目标,对其进行定位,框起和标注

图像分类与目标检测的区别
图像分类:整幅图像经过识别后被分类为单一的标签
目标检测:除了识别出图像中的一个或多个目标,还需要找出目标在图像中的具体位置
目标检测的评估指标
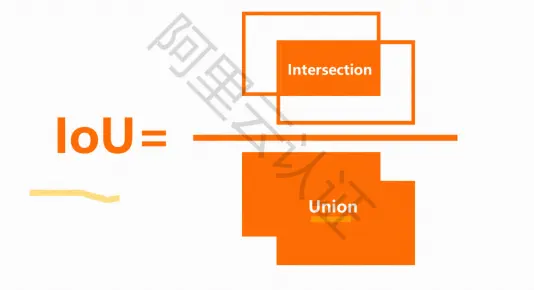
交并比:loU
真实边界框:训练集中,人工标注的物体边界框
预测边界框:模型预测到的物体边界框
交并比:在分子项中,是真实边界框和预测边界框重叠的区域。分母是一个并集,或者更简单地说,是由预测边界框和真实边界框所包括的区域。两者相除就得到了最终的得分
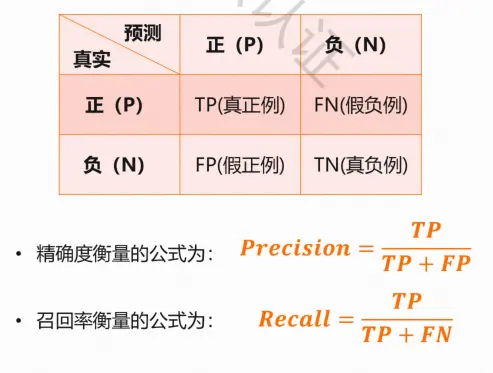
精确度和召回率
平均精度值:mAP
mean Average Precision 各类别平均精度均值
mAP是把每个类别的AP都单独拿出来,然后计算所有类别AP的平均值,代表着对检测到的目标平均精度的一个综合评价
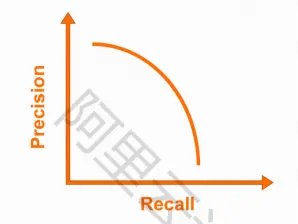
每一个类别都可以根据Recall和precision绘制一条曲线,那么AP就是该曲线下的面积,而mAP则是多个类别AP的平均值,这个值介于0-1之间。mAP是目标检测算法里最重要的一个评估指标
目标检测的挑战
目标数量问题:在图片输入模型前不清楚图片中有多少个目标,无法知道正确的输出数量
目标大小问题:目标的大小不一致,甚至一些目标仅有十几个像素大小,占原始图像中非常小的比例
如何建模:需要同时处理目标定位以及目标物体识别分类这两个问题
目标检测的常用数据集:PASCAL VOC
一个常用于目标检测的小型图像数据集
包含11530张彩色图像,标定了27450个目标识别区域
从初始4个类发展成最终的20个类
在整个数据集中,平均每张图片有2.4个目标
使用的相关神经网络:CenterNet
CenterNet结构优雅简单,直接检测目标的中心点和大小
把目标检测任务看作三个部分:
寻找物体的中心点
计算物体中心点的偏移量
分析物体的大小
CenterNet 检测速度和精度相比于先前的框架都有明显且可观的提高,尤其是与著名的目标检测网络 YOLOv3 作比较,在相同速度的条件下,CenterNet 的精度比 YOLOv3 提高了大约 4 个点。
典型应用
智慧交通
交通异常事件检测,检测各种交通异常事件,车辆占用应急车车辆驾驶员的驾驶行为等
交通流量监控与红绿灯配时控制
五、图像分割基础
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程
包括语义分割、实例分割、全景分割

区域可以表示为一种掩码(灰度或颜色),其中每个部分被分配一个唯一的颜色或灰度值来代表
图像分割的类别
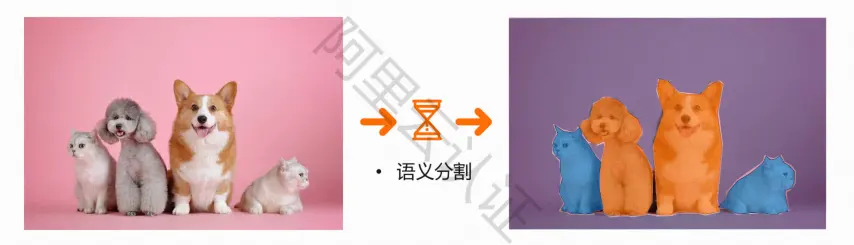
语义分割:
在像素级别上的分类,属于同一类的像素都要被归为一类
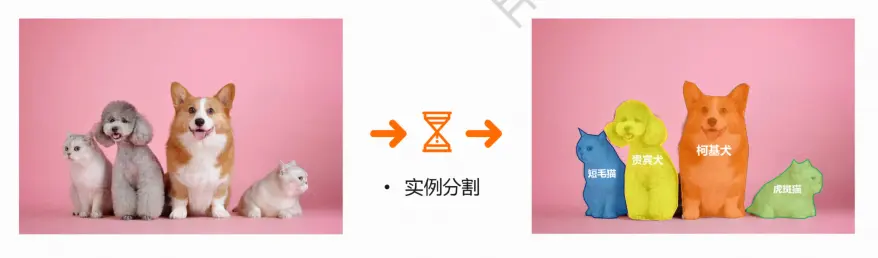
实例分割:
还要在具体类别(猫、狗)像素的基础上区分开不同的实例(短毛猫、虎斑猫、贵宾犬、柯基犬)
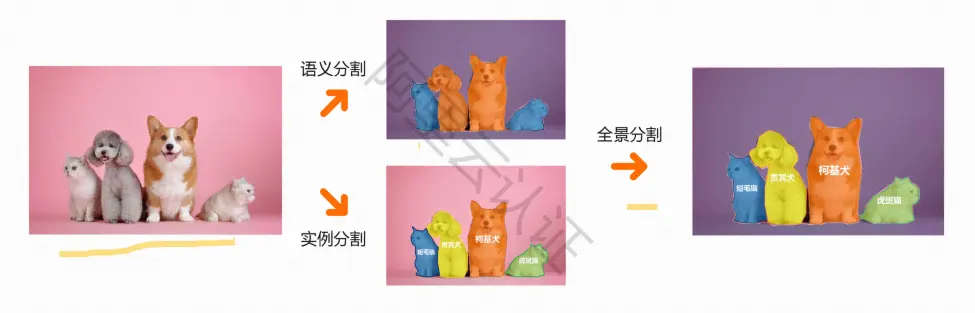
全景分割:
语义分割和实例分割相结合
图像分割的挑战
分割边缘不准:
因为相邻的像素对应感受野内的图像信息太过相似导致
样本质量不一:
目标物体之间的遮挡、重叠
受场景光照影响,样本质量参差不齐
标注成本高:
数据样本标注成本非常高,标注质量难以保证不含噪声
图像分割常用数据集:COCO
33万张彩色图像,标定了50万个目标实例
80个目标类、91个物品类、25万个人物关键点标注
每张图片包含5个描述
每一类的图像多,利于提升识别更多类别位于特定场景的能力
使用的相关神经网络:FCN
FCN全卷积神经网络是图像分割的基础网络(所有层都是卷积层)
卷积神经网络卷到最后特征图尺寸和分辨率越来越小,不适合做图像分割,为解决此问题FCN引入上采样方法,卷积完之后再上采样到大尺寸图
为避免层数不断叠加后原图的信息丢失得比较多,FCN引入一个跳层结构,把前面的层特征引过来进行叠加
FCN实现了端到端的网络
端到端学习是一种解决问题的思路,与之对应的是多步骤解决问题,也就是将一个问题拆分为多个步骤分步解决,而端到端是由输入端的数据直接得到输出端的结果
典型应用
抠图软件

智能证件照