阿里云人工智能ACA认证(7)—自然语言处理基础
2025-05
浏览量:527
本文字数:2114
读完约 8 分钟
一、基本介绍
自然语言理解:
所有支持机器理解文本内容的方法模型或任务的总称,是推荐、问答、搜索等系统的必备模块
自然语言生成:
将非语言格式的数据转换成人类可以理解的语言格式,是翻译、协作等系统的必备模块
自然语言处理的发展趋势
智能人机交互
不同语言、不同领域下的人机交互提升
多语言交互从不同语言理解上升到不同文化的理解
多模态融合
视频、图像、文本、语音等模态的全面融合
在对话系统产品中应用效果显著
解决方案建设
在每种场景领域都有特定的需求及其相应的场景数据
模型结合场景数据进行训练能够更好地满足场景需求
行业知识库
结合已有的知识和技术提高非结构化数据理解能力
基于过去已知知识进行推理,理解行业事件知识
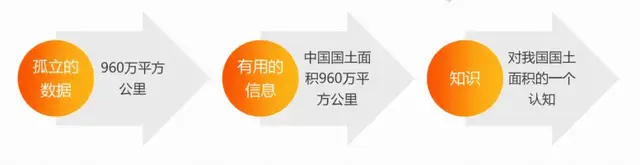
自然语言处理的数据基础
语料库
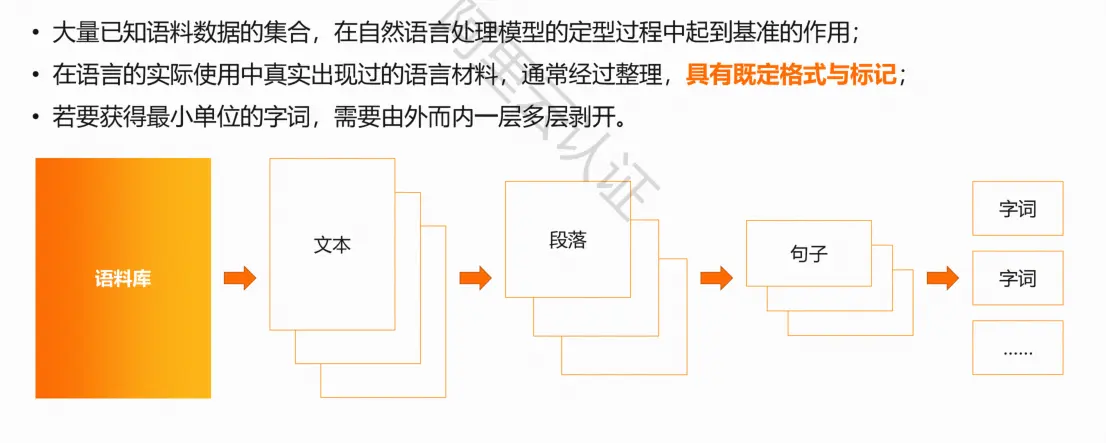
常见语料库

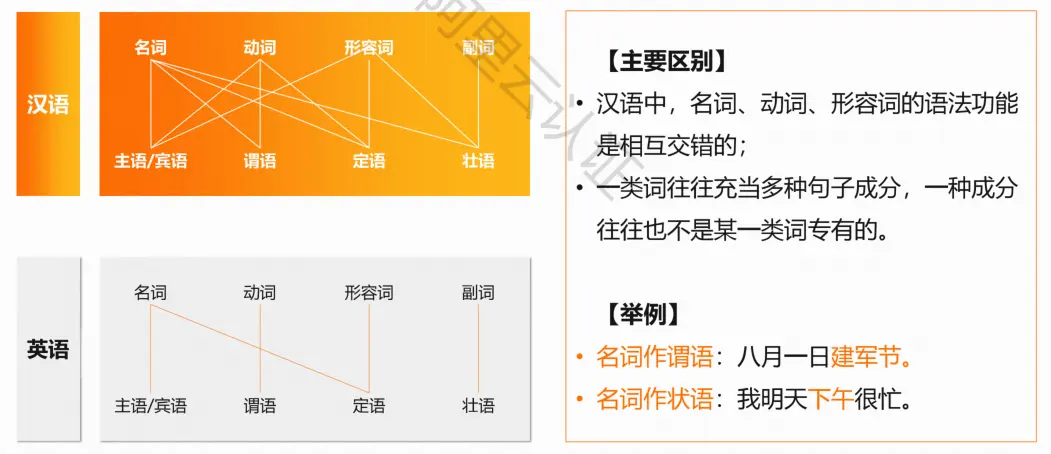
汉英区别
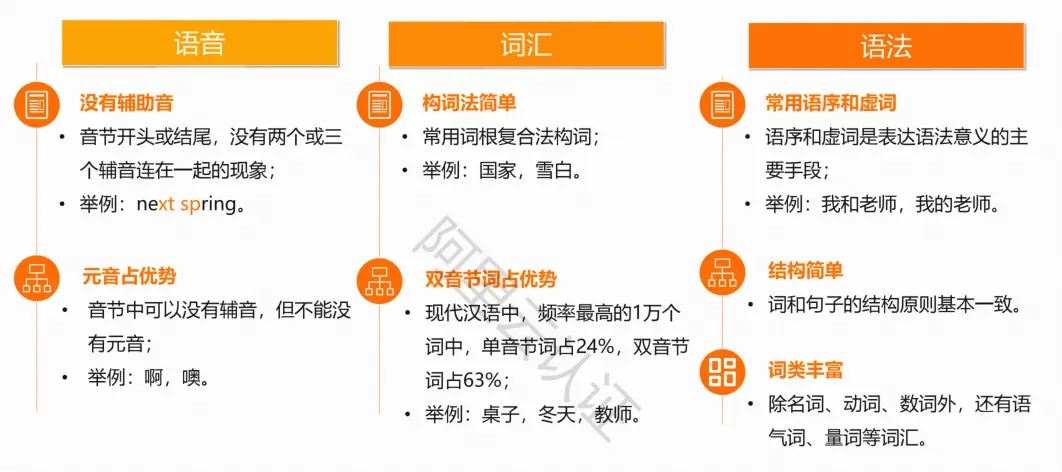
现代汉语的特点
技术体系
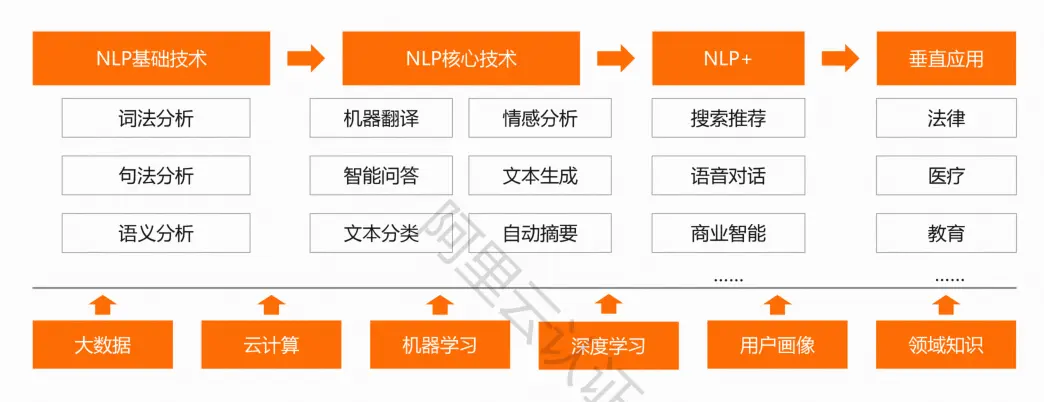
基础技术

二、详细技术介绍
分词
将句子、段落、文章等长文本分解为以字词为单位的数据结构
常见的方法包括最大匹配分词算法和最短路径分词算法

分词的难点

分词实现方法
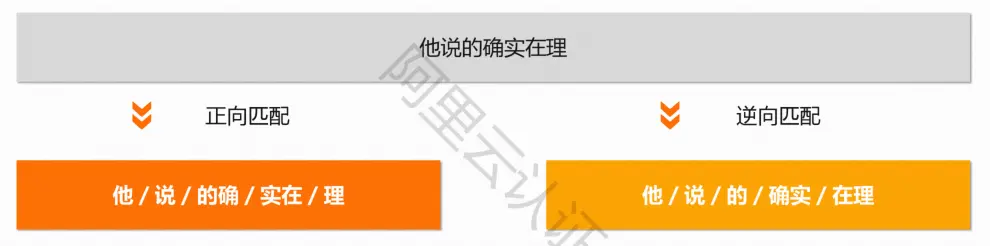
最大匹配分词:
以词典为依据,取词典中最长词长度作为第一次取字数量的长度
在词典中进行匹配,然后逐字递减,在对应的词典中进行查找
根据匹配的方向不同,分为正向匹配和逆向匹配
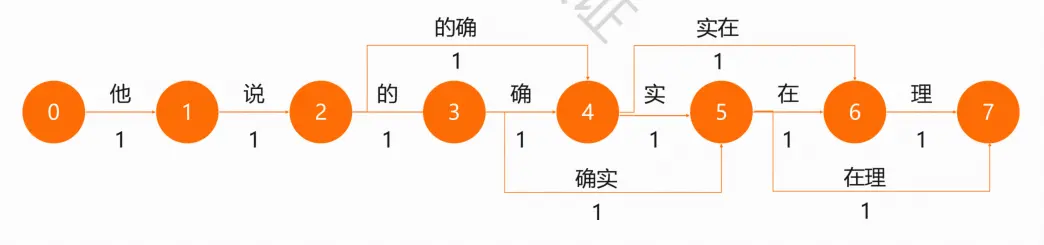
最短路径分词算法:
首先将文本中的所有词匹配出来,构成词图,寻找从起始点到终点的最短路径
词图中每个词的权重都是相等的,因此每条边的权重都为1
两点之间的最短路径也包含了路径上其他顶点间的最短路径
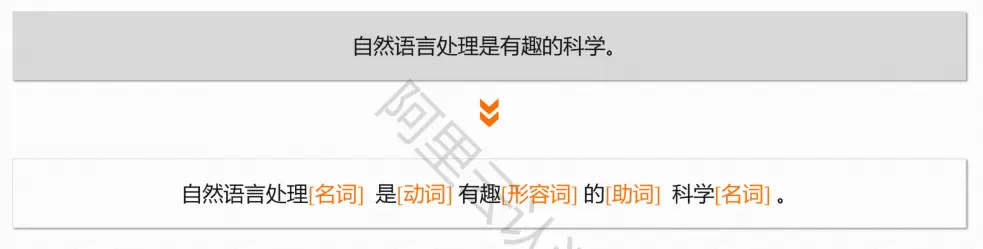
词性标注
在给定句子中判断每个词的语法范畴,确定其词性并加以标注的过程
中文词性分类:名词、动词、形容词、副词、代词、介词、连词、数词、量词、助词、感叹词、拟声词
标注规范
先将词分为名词、动词、形容词等,然后用“n”、“v”、“adj”等进行表示

关键词提取
关键词即文本中一些“重要的”词,通过这些重要的词可以理解文本中心思想
关键词提取质量,体现在关键词提取的准确性、全面性和代表性
关键词提取的评价指标为词的权重

关键词提取的实现包括两个步骤,第一步是获取文本的候选词,第二步则是对候选词进行打分
输出的关键词是候选词中得分比较高的

关键词提取算法一般分为有监督和无监督两类

命名实体识别
识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等
通常把对这些词的识别在词汇形态处理任务中独立处理

命名实体识别的标注方法
三大类:实体类、时间类、数字类
七小类:人名、机构名、地名、时间、日期、货币、百分比
常用 BIOES-四位序列标注法
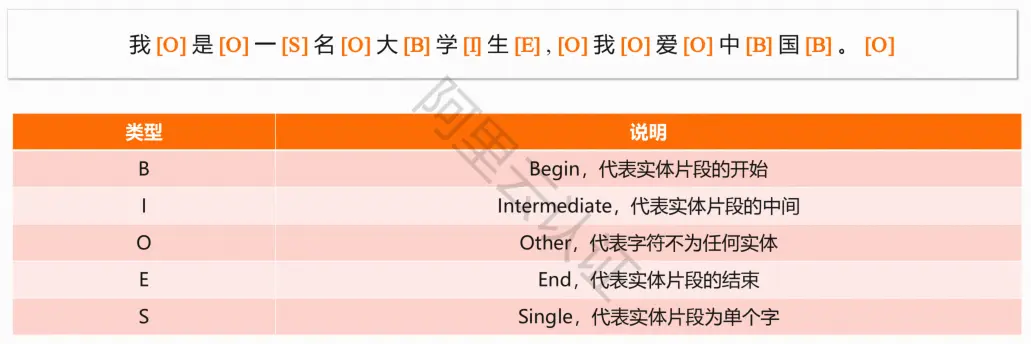
语法分析
判断输出的字符串是否属于某种语言
消除输入句子中词法和结构等方面的歧义
分析输入句子的内部结构,如成分结构、上下文关系

语法分析的难点
歧义和搜索空间

语法分析实现方法
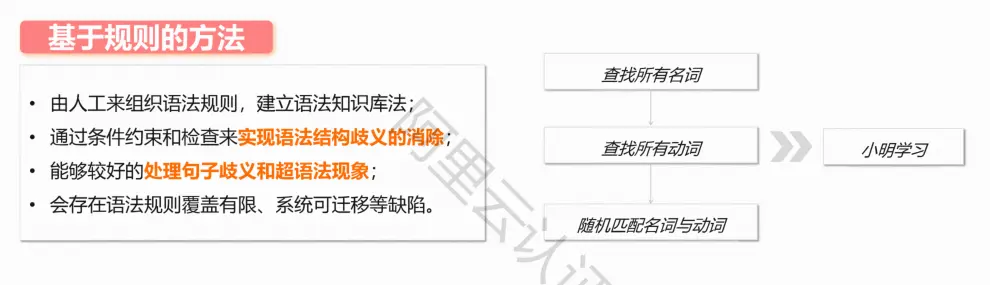
基于规则的方法是语法分析中的常用方法
以“小明在快乐地学习”为例
文本向量化
自然语言处理前,需要将文本表示成计算机可识别的数值形式
一个语言模型来构建关于输入和输出之间的映射关系
离散式词向量和分布式词向量是文本向量化中的常用方法
文本向量化的实现方法
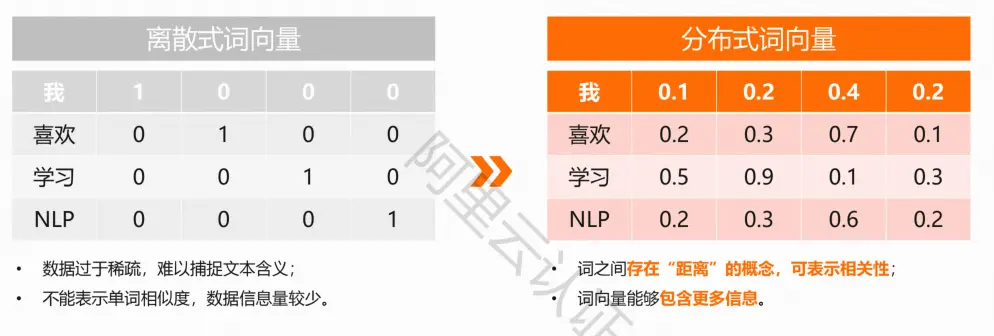
离散式词向量:
常用 One-Hot 编码,每一个词特征都被表示成一个很长的向量
其长度等于词表大小,当前词对应位置为1,其他位置为0
无法衡量不同词之间的相似关系,无法突出词之间重要性的区别

分布式词向量:
将词转化成一种分布式表示,即将词表示成一个定长的连续的稠密向量
三、自然语言理解技术介绍与应用
文本分类
能够对文本按照一定的分类标准进行自动分类标记
机器自动化标注的文本数据具有一致性、高质量等特点
利用待分类数据的特征与类别进行匹配,选择最优的匹配结果作为分类结果
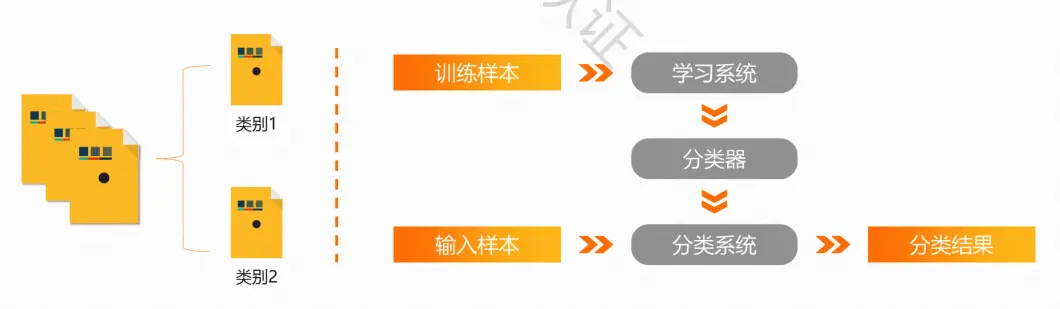
应用场景
从给定的标签集合中自动地给文本打标签

情感分析
用户生产的带有主观性的文本有助于制定决策
对带有情感色彩的主观性文本进行分析、处理、归纳和推理
实现方法:
由预标记词汇组成的字典,使用词法分析器将输入文本转换为单次序列
将每一个新的单词与字典中的词汇进行匹配,根据匹配结果提高或降低文本得分
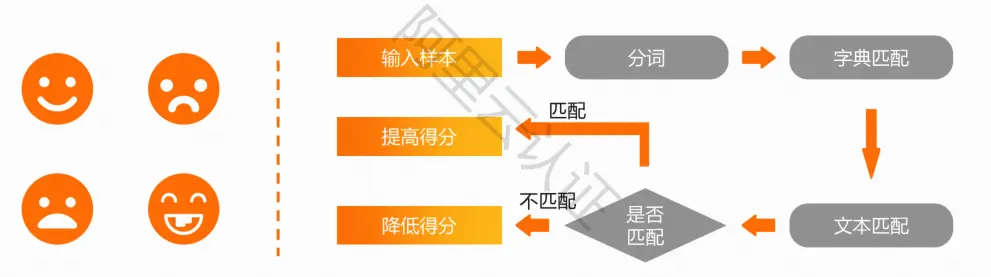
应用场景:

文本纠错
错误类型包含错别字、缺失字、冗余字、词语搭配错误和语法错误等
能够评估和权衡相关因素,比人类更快、更准确地识别

实现方法:
第一步错误检测,第二步错误纠正
从字粒度和词粒度两方面来检测文本错误
遍历所有的疑似错误位置,使用音似、形似等相关词替换错误位置的词

应用场景:

问答系统
一个能回答任意自然语言形式问题的自动化系统
能给对于一个指定问题,能够得到简短、精确的答案

实现方法:
通常采用基于自由文本的方式实现
属于开放域问答系统,能够回答一些答案存在于文档集合中的问题
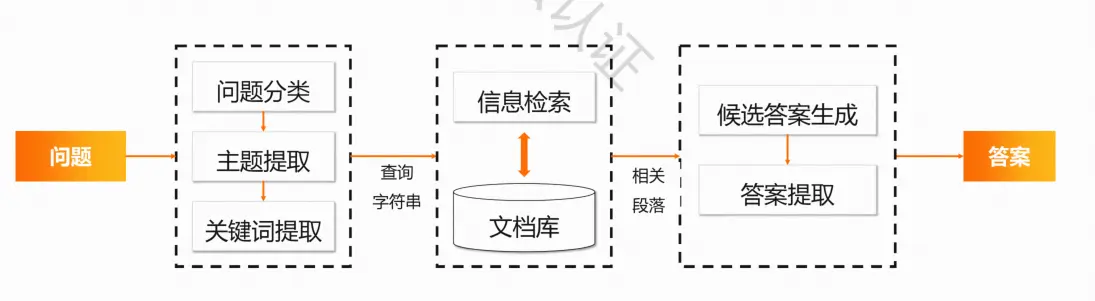
应用场景:
智能客服、快速检索

四、自然语言生成技术介绍与应用
文本标签生成
生成的标签在一定程度上能够体现文本内涵
是文本检索、文档比较、摘要生成、文档分类、聚类等文本挖掘研究的基础性工作
实现方法:
采用计算权重的方式从候选集合中得到文本标签
主要包括词性、词频、逆向文档频率、相对词频、词长等
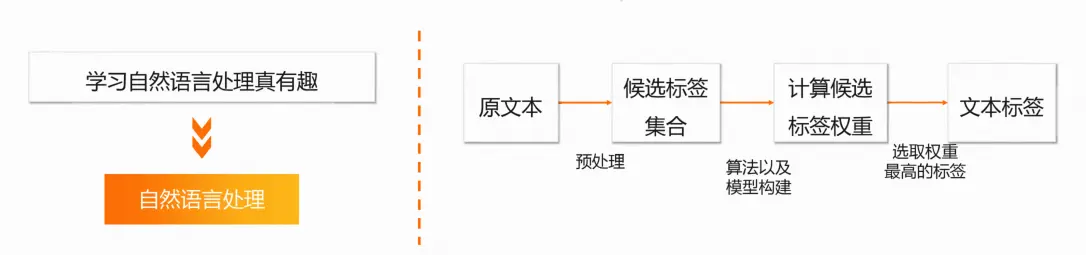
应用场景:
个性化推荐、主题聚合

文本摘要生成
自动生成含原文本中重要信息的新文本内容
通过机器自动输出简洁、流畅、保留关键信息的摘要

应用场景:
自动报告生成、新闻标题生成、搜索结果预览

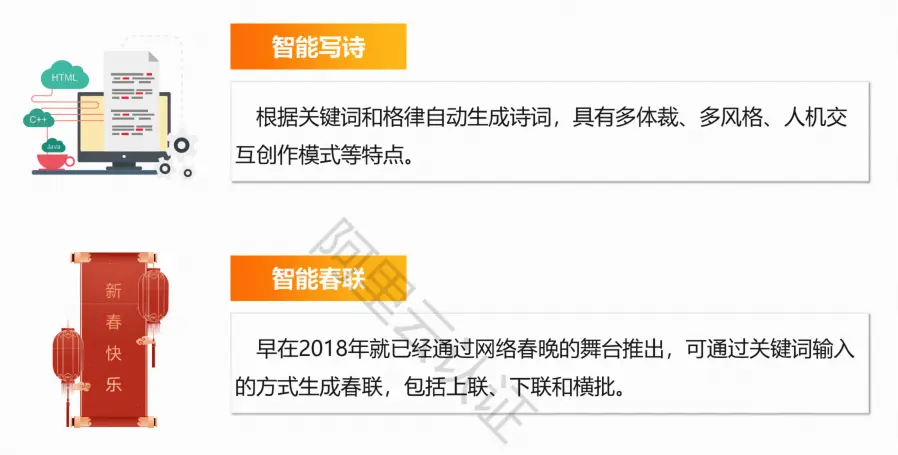
智能创作
可分为人工智能自动写作和人工智能辅助写作两类
具有作品制作高效、具有强大潜能、内容客观、节省人力成本等

应用场景:
智能写诗、智能春联
应用方法: