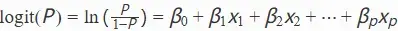统计学七支柱
2024-12
浏览量:340
本文字数:2897
读完约 10 分钟
追溯统计学来龙去脉,阐释统计推理核心思想。
“统计学是什么?”早在1838年就有人提出过这个问题(与英国皇家统计学会有关),此后这个问题又被反复提起。多年来,铁打的问题和流水的答案已成为该讨论的特点。
统计学有各种各样的问题、方法和解释,那到底有没有自己的核心科学呢?
这个问题就是我想在本书中解决的。我不打算告诉你统计学是什么或不是什么,而是尝试制定七个原则,即支撑统计学领域的七根支柱。它们在过去曾以不同方式支撑统计学,我保证,它们一定还会在无限的未来继续起到这样的作用。我会尽力使你相信,每根支柱的引入都是革命性的,并对统计学的发展产生了深远影响。
它们是七根“支撑”的柱子,是统计学的学科基础,而不是完整的体系。
第一根支柱:聚合(Aggregation)
我们也可以使用它在19世纪的名称“观测的组合”,甚至使用最简化的名称:均值。名字太简单可能误导读者,其实,虽然它现在看来已不新鲜,但在早年却真正地具有革命性,并且时至今日依然如此——无论它在何时进入新的应用领域。那么,它如何体现革命性?按照规定,给定一些观测值,你可以通过丢弃信息而真正获得信息!我们对观测值取简单的算术平均值,丢弃观测值的个别特征,而将其都纳入汇总值进行考虑。目前,这在重复测量中很常见,比如观测恒星在太空中的位置。然而在17世纪,可能需要忽略这样一些信息,比如法国是个酒鬼观测员做出的观测,俄罗斯人是用旧仪器做出的观测,英国是个很靠谱的朋友做的观测。事实上,抹去个体观测的细节比任何单个观测都能给出更棒的指示。
根据记录,算术平均值的使用最早出现在1635年;而其他形式的统计汇总的历史则更为悠久,可以追溯到美索不达米亚文明最初出现文字的时代。当然,第一根支柱最近的重要实例更为复杂。最小二乘法及其衍生方法的本质都是均值,它们通过对数据进行加权汇总而抹去数据的个体特性——指定的协变量除外。甚至核密度估计和各类现代平滑器在本质上也是均值。
第二根支柱:信息(Information)
更具体地说是“信息度量”,也是说来话长又很有意思。我们什么时候有足够的证据证明一种药物的疗效?这个问题可以追溯到古希腊。而研究信息积累率的时代则要近很多。18世纪早期,人们发现在很多情况下,一个数据集的信息量仅与观测个数n 的平方根成正比,而不与n 本身成正比。这也是革命性的思想。假设你试图说服一名宇航员,如果他想将研究精度提高一倍,那么他需要用4倍数目的观测;又或者,第二组20个观测值与前20个观测值尽管同样精确,但第二组的信息量并不像第一组的那么大。我们将这个思想称为“根号n 规则”。它需要一些很强的假设,并且在很多复杂的情形中使用时需要修正。无论如何,1900年就明确建立了这样的思想:数据中的信息可以测量,而测量的精度与数据量有关,某些情形下可以精确刻画相关性的形式。
第三根支柱:似然(Likelihood)
意味着使用了概率的推理的校准。显著性检验和普通的P值都是最简单的似然形式,但诚如其名,与“似然”有关的方法丰富多彩,其中许多方法或者与费舍尔推断的参数族有关,或者与贝叶斯推断的参数族有关。各种各样的检验可以追溯到至少一千年前,但最早使用概率的检验则出现在18世纪早期。许多例子出现在18世纪~19世纪,而系统性处理则出现在20世纪罗纳德·费舍尔的工作,以及耶日·奈曼和伊冈·皮尔逊的工作中。从那时起,统计学家开始认真发展了一整套似然理论。人们最熟悉的检验可能是用概率校准推断,但一个概率数字无论作为置信区间还是贝叶斯后验概率,都必须完全附属于一种推断。事实上,250年前发表的“托马斯·贝叶斯定理”就是为了完成这个目标。
第四根支柱:相互比较(Intercomparison)
这个名称借鉴了弗朗西斯·高尔顿的一篇论文,它表达了一个过去激进但现在普通的思想:统计比较常常可以采用数据自身的内部标准,而不必采用外部标准。相互比较最常见的例子是学生t 检验和方差分析的检验。一方面,在复杂设计中,变化的划分可能错综复杂;另一方面,复杂设计允许区组设计、裂区设计,或完全根据手头数据评价的层次设计。这种思想非常激进,而且在“有效”的检验中,这种思想有着与最强大的工具一样的问题:可能由于忽略外部科学标准而导致错误方式的滥用。我们可以将自助法视为相互比较在假设弱化后的现代版本。
第五根支柱:回归(Regression)
这个名称源于高尔顿1885年发表的论文,这份文献基于二元正态分布解释了什么是回归。达尔文的自然选择理论存在内部矛盾:选择需要增加多样性,但定义物种需要群体外观稳定。高尔顿尝试为这个理论设计一个数学框架,并成功地克服了这组矛盾。
回归现象可简单解释为:假设有两个不完全相关的观测变量,你选择了其中极值远离均值的变量,那么可以预期另一个(以标准差为单位)不会那么极端。高个子的父母平均会孕育身高稍矮的子女,而高个子的子女平均会有身高稍矮的父母。但这一现象涉及的不只是一个简单的悖论:真正新奇的思想在于,提问的方式不同,答案就完全不同。事实上,这项工作引入了现代多元分析和任何推断理论都需要的工具。引入这个条件分布的工具前,真正一般化的贝叶斯定理无法使用。因此,这根支柱与因果、推断一样,是贝叶斯学派的核心内容。
第六根支柱:设计(Design)
类似于在“实验设计”中的含义,但“设计”的范围更广泛,它的目标是:先设定观测的权重相同,再训练我们的思想。设计的某些要素历史悠久,《旧约全书》和早期的阿拉伯医学提供了相应的例子。从19世纪晚期,随着查尔斯·皮尔斯和费舍尔先后发现随机化在推断中的巨大作用,统计学出现了对设计主题的新理解。费舍尔认识到结合严谨的随机化方法将会带来好处,于是在实验法则中引入激进的改变。这些改变一反几个世纪以来的实验哲学和实践,将这一主题提升到了一个新的高度。多因素现场试验中,费舍尔的设计允许效应的分离和相互作用的估计;实施随机化后,有效推断不再需要正态性或者材料的均匀性的假设。
第七根支柱:残差(Residual)
“残差”表示“其他的一切”,你也许会怀疑这是一种托词,但我想表达一种更具体的思想。从19世纪30年代开始,有关残差现象的概念在关于逻辑的书籍中就很常见。正如一位作者所说:“复杂的现象……可以通过减去已知原因的影响进行简化……留下……需要解释的残差现象。通过这样处理……科学……得到了极大的促进。”而后,这种思想总体上归入古典的范围,却以一种新方式在统计学中得到使用。这种新方式结合了结构化模型族,并通过概率计算和统计逻辑在族内做选择,从根本上强化和规范了方法。模型诊断(画出残差)在统计学中极为常见,但通过拟合和比较嵌套模型探索高维空间的方法更具重大意义。每个对回归系数显著性的检验都体现了这种思想,针对时间序列的每一个探索亦是如此。
我重新概括了七根支柱,用七种基本统计思想的作用来表达——尽管这样做也许会导致过度简化的风险。
(1) 定向减少或压缩数据的价值。
(2) 数据量上升,价值会减少。
(3) 如何使用概率测量我们做的事?
(4) 如何使用数据中的内部变化帮助分析?
(5) 从不同角度提问可以产生有启发性的不同答案。
(6) 规划观测的重要作用。
(7) 所有这些思想如何用于科学探索和比较彼此矛盾的解释。