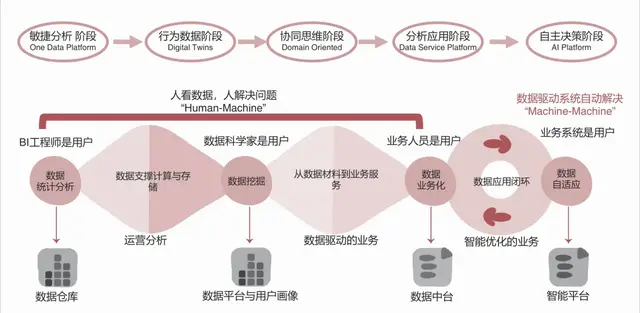
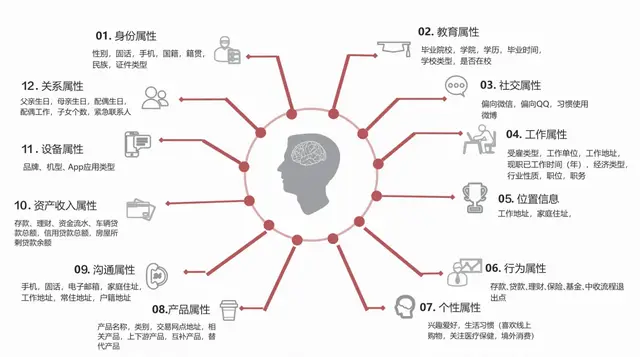
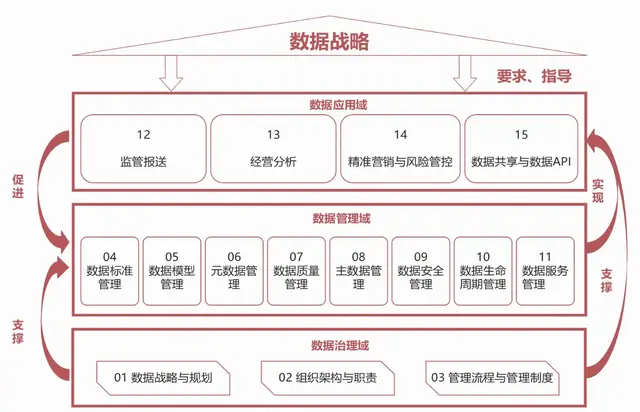
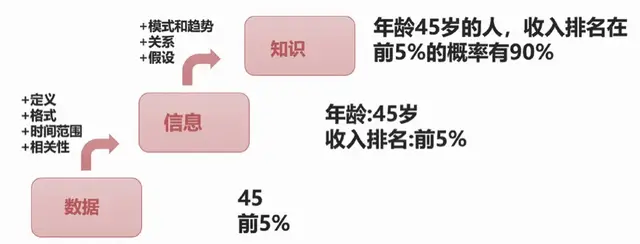
五、宏观业务分析方法(矩阵分析法、连续型变量降维、主成分分析法、因子分析、多维尺度分析)
2024-11
浏览量:325
本文字数:8256
读完约 28 分钟
在实际业务中,收集到的数据往往维度众多,将其全部纳入模型进行分析不仅会造成维度灾难,而且成本较高。本章主要从宏观业务角度出发,讲解大数据小分析的基本思想与合理性,并介绍常用的数据降维方法——主成分分析法与因子分析法。
一、矩阵分析法
矩阵分析法的基本思想是大数据小分析,所谓大数据小分析就是在做决策时对数据进行降维,以便决策者更加明确地了解事务的本质。因此,在学习矩阵分析法之前先引入维度分析的思想。
选取在一些重要维度中有代表性的变量进行分析。一般来讲,在收集的数据中有很多是高度相关的,这表明这些变量很可能提供的是同一个维度的信息,这时就需要对数据进行压缩,从大量的数据中归纳出少量的、最具代表性的变量,选取的变量应该满足同目标变量相关且各个变量之间互不相关的两个基本要求。
维度分析:从成千上万个变量中选择符合上述条件的变量,就是维度分析。这里的维度是指表述事物的不同方面。比如,从长、宽、高3个维度描述立体图形;从思维、认识、创造、适应环境和表达5个维度描述一个人的智力情况。
案例1:某企业有多个产品,如何根据不同产品的表现制定发展战略?
波士顿咨询公司认为,只有相对市场占有率和市场成长率两个变量在这个问题的回答上最有价值,并将其固化为“波士顿矩阵”

为什么会选择这两个变量呢?原因在于产品相对市场占有率和利润率、产品知名度有较强的关系,反映了该产品的市场地位和产生现金流的能力,而市场成长率和市场饱和度强相关,反映了产品的市场发展潜力,也就是说这两个变量是最具代表性的两个变量,符合维度分析的基本思想。
市场成长率反映了产品生命周期的变化情况,而市场占有率反映了企业具体产品的市场渗透情况,也就是说它们是两个独立的变量,分别反映不同维度(市场成长率反映了市场的情况,市场占有率反映了企业在市场上的情况)的信息,从而通过不同的维度对产品进行正确的分类。

上述案例分析表明,波士顿矩阵分析可以帮助企业制定出不同的产品发展战略,包括资源分配、拟定业务战略、制定绩效目标及平衡投资组合等。
对于瘦狗产品,一般不会对其进行发展性资源的分配,而且制定的绩效会比较苛刻;
对于问号产品,要观察其未来市场的发展情况,如果发展良好,市场占有率不断增加,则可以考虑为其配置战略性资源,制定温和的绩效目标(比如用户黏性、用户增长率、用户好评度等);
对于金牛产品,更加关注其收益类指标,至于用户黏性基本不做过多关注。
对波士顿矩阵的象限特征进行总结,并根据不同类型产品的特征制定不同的发展战略:

在矩阵分析法中,问号产品的发展轨迹:

案例2:某外企计划开拓中国市场,应该先主攻哪个省呢?
描述这个问题的两个重要变量分别是市场规模和市场增长率,运用这两个变量对省(市)进行分类

案例3:一家信用卡公司希望将用户按照价值贡献—活跃度进行分类,有哪些类型?如何进行用户维护?
根据波士顿矩阵分析思路,对个体用户打标签,通过聚类分析,得到用户的类别,并且投影在由循环信用次数和交易次数这两个指标组成的二维空间上,便于业务人员理解,其中,交易次数反映用户的黏性,循环信用次数反映用户的价值。总体来说,本案例是通过维度分析的方法对用户进行分类的。

如果当前没有波士顿矩阵,那么数据分析师该如何产出该矩阵呢?即如何从成千上万个指标中选出有代表性的指标进行分析呢?这就用到了常用的信息压缩方法——主成分分析法。主成分分析法能够将多个指标压缩为少量的几个综合指标,但是这几个综合指标没有实际的业务含义,于是就产生了因子分析。因子分析可以在主成分分析的基础上探查综合指标的业务含义,最终可以直接根据因子分析的结果构建相应的分析矩阵,也可以根据因子分析的结果发现与因子相关的变量,根据具有代表性的变量构造分析矩阵。
若数据的维度能够被降低到符合预期的程度且不至于损失太多对模型有用的信息,那么这种降维就是理想的。
二、连续型变量降维
建模的两大问题是引入了不相关变量和冗余变量。不同算法剔除不相关变量的方式不同,比如在分类模型中可以通过两个变量统计检验、逐步法、决策树等模型算法剔除不相关变量;而聚类模型完全依靠分析师的个人经验,借助维度分析的手段进行不相关变量的剔除。至于去除冗余变量,统一采用主成分算法及其变体,将相关性较强的变量合成一个变量,或者只选取其中一个变量。
虽然特征选择与转换在理论上可以针对所有类型的变量,但在实操中只有连续型变量才能比较方便地降维,分类型变量往往先进行水平规约,然后转换为连续型变量(该方法被称为WoE转换)进行降维。
变量聚类:从一些相关性较强的变量中提取有代表性的变量,在统计学中称为变量聚类。
特征转换:将相关性较强的一组变量合成为一个变量,代表算法是主成分分析法和因子分析法。
1、方法概述
降低数据维度属于特征变换的操作,分为变量筛选和维度规约两个方面。
2、变量筛选
变量筛选的方法分为:
两个变量独立性检验:通过在被解释变量和单个解释变量之间做假设检验来完成,包括卡方检验、方差分析(含两个样本t检验)、相关分析。
模型筛选法:使用与建模算法高度融合的算法进行有价值的变量筛选,比如决策树通过计算熵增益、基尼增益等指标筛选出高价值变量。在线性回归中变量筛选的方法,包括向前回归法、向后回归法、逐步回归法等,这些方法的核心思想都是删除那些无法提升模型效果的变量,从而降低建模复杂度。
3、维度归约
维度归约就是减少数据的特征数目,摒弃不重要的特征,尽量只用少数的关键特征描述数据。
很多人担心信息损失的问题,实际上模型的可运用性才是最重要的。一般预测类模型要求信息损失越少越好,而聚类模型为了追求模型的可解释性,信息损失可以多一点,这也体现了抓大放小的思想。
1)主成分分析
主成分分析是考察多个变量之间线性相关性的一种多元统计方法。从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,并且彼此间互不相关,以达到用少数几个主成分揭示多个变量间结构的目的。
由于原始数据经过主成分分析之后,得到的主成分不再具有可解释性,因此该方法多用于不可解释类的预测模型,比如神经网络、支持向量机等。
2)变量聚类
从本质上讲,变量聚类是主成分分析的一个运用。变量聚类方法通过摒弃一些相关性较强的变量,达到减少冗余信息、避免共线性的目的。该方法多用于构建可解释类预测模型前的特征处理,比如线性回归、逻辑回归、决策树等,也可用于聚类模型。
3)因子分析
根据因子分析的底层逻辑,少量的因素会驱动事务的发展。因子分析方法就是力图从表象数据中提取深层次的影响因子。因子分析的方法众多,如因子旋转法的因子分析是主成分分析的延伸。由于主成分不具有可解释性,而社会科学(商业、心理学、社会学等)工作者在研究问题时又非常关心变量的可解释性,因此通常通过调整主成分在原始变量中的权重来发现(实际上一大部分是人为赋予的)主成分所代表的含义。该方法主要用于描述性统计分析和聚类模型,多用于市场研究、研究报告中,不用于预测类模型建模。
4)奇异值分解
奇异值分解是主成分分析在非方阵情况下的推广,某些方面与对称矩阵或Hermite矩阵基于特征向量的对角化类似。奇异值分解方法被广泛用于推荐算法,也可以用于缺失值填补。
三、主成分分析法
1、主成分分析简介
主成分分析的目的是构造输入变量的少数线性组合,从而达到降维的目的,并且尽量多地解释原始数据的变异性。这些线性组合被称为主成分,可用于后续的预测或聚类模型。
两个连续型变量相关性的强弱可以通过散点图进行直观的展示,也可以通过计算公式生成表示线性相关性强弱的相关系数。当连续型变量多于两个时,生成的相关系数矩阵直观地展示多个连续型变量之间的关系。当多个变量两两之间的相关性较强时,表示这些变量之中共同的信息比较多,此时若能通过一种方法提取多个变量之间的共同信息,同时又能最大程度地保留原始数据信息,那么就可以把复杂的多元分析问题变得简单。
2、主成分分析原理
1)几何解释
假设有两个有较强线性关系的连续型变量X和Y,其散点图如图,第一个主成分由图中比较长的直线代表,在这个方向上能够最多地解释数据的变异性,即数据在该轴上投影的方差最大。第二个主成分由图中比较短的直线代表,与第一个主成分正交,能够最多地解释数据中剩余的变异性。一般而言,每个主成分都需要与之前的主成分正交,并且能够最多地解释数据中剩余的变异性。

假设有三个有比较强线性关系的连续型变量X、Y、Z,其散点图如图,三维空间中的相关连续型变量呈压扁的椭球状分布,只有这样的分布才需要做主成分分析。如果散点在空间中呈球形分布,则说明变量间没有线性相关关系,没有必要做主成分分析,也不能做变量的压缩。

在三个变量中,首先找到这个空间中椭球的最长轴,即数据变异最大的轴

在与第一个主成分直线垂直的所有方向上,找到第二根最长的轴,然后在垂直于第一个、第二个主成分直线的所有方向找到第三根最长的轴。

这三根轴可以提取原多元数据的信息。在这个案例中,第一根轴是最长的,其携带的信息量也是最多的,第二根轴和第三根轴所携带的信息量依次减少,三根轴累计提取了原数据的所有的信息量。如果前两个轴上的信息占较高的比例,如超过90%,则第三个轴上的信息就可以丢弃不用,从而达到压缩变量的目的。
2)线性代数解释(基于协方差矩阵的主成分提取)
主成分是在原始数据空间中的线性转换,其表达式如下:
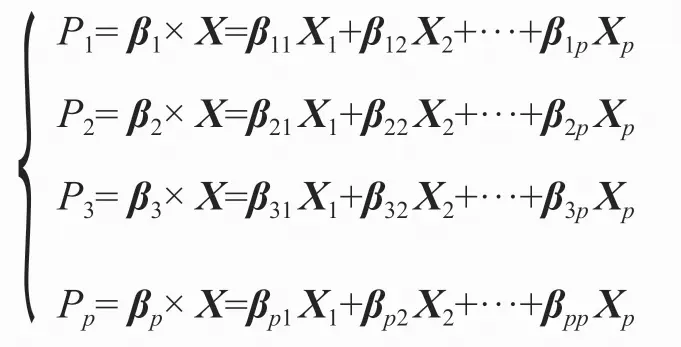
设多个随机向量集合为X=(X1, X2, X3, …XP),其协方差矩阵为:
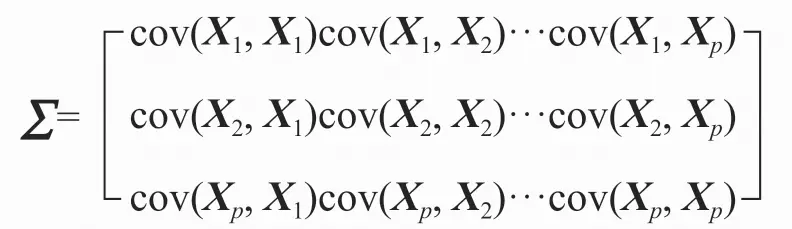
则通过线性代数的知识可以得到主成分P的方差的计算公式:
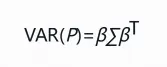
其中,β代表主成分在每个变量上的权重。主成分算法的目标函数是计算特征向量β,使得上式取得最大值,即主成分上的方差取得最大值。这个求极值的过程就是线性代数中计算方阵的特征向量和特征根的算法。
显然协方差矩阵∑是一个P×P的对称矩阵,对此矩阵求解特征值与特征向量,主成分就是特征向量,设该协方差矩阵的特征值为λ1>λ2>…>λk,对应的特征向量为:
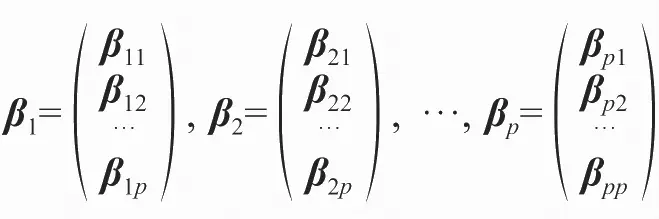
那么对于这个协方差矩阵有:
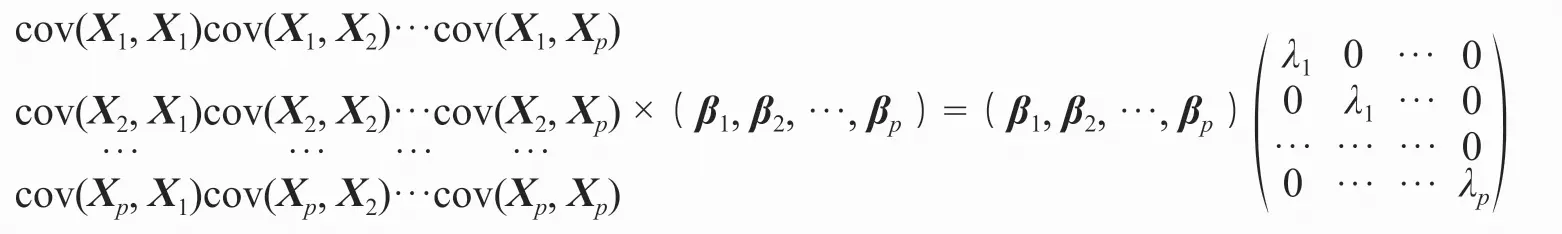
这样就可以写出主成分得分。
由于特征向量:
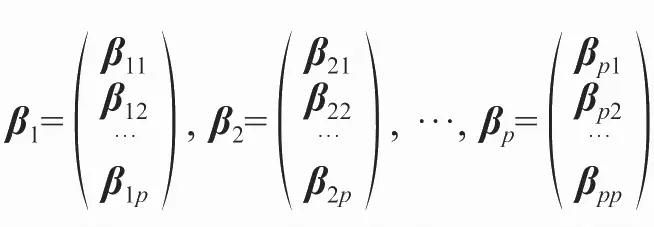
两两正交,因此主成分之间无相关性。
主成分分析有如下几个特点:
(1)有多少个变量就会有多少个正交的主成分。
(2)主成分的变异(方差)之和等于原始变量的所有变异(方差)之和。
(3)前几个主成分的变异(方差)可以解释原多元数据中的绝大部分变异(方差)。
(4)如果原始变量不相关,即协方差为0,则不需要做主成分分析。
那么,选取多少个主成分表达原多元数据合适呢?通常的选取原则为单个主成分解释的变异(特征值)不应该小于1,并且选取的前几个主成分累计解释的变异能够达到总体的80%~90%。
主成分解释变异的能力可以以方差解释比例来计算:
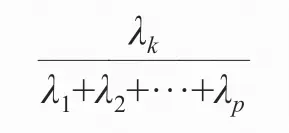
λk表示主成分k的特征值大小,分母表示所有特征值的和。
3)线性代数解释(基于相关系数矩阵的主成分提取)
既然主成分分析是根据原始变量的方差进行计算的,那么就要求所有变量在取值范围上是可比的,不能出现一个变量的取值范围是0~10000,而另一个变量的取值范围是0~1。例如,变量“企业销售额”和“利润率”,“企业销售额”的方差非常大,而“利润率”的方差则比较小,这样计算出的协方差矩阵就有问题。由于原始变量取值范围不可比,因此一般情况下不使用协方差矩阵计算主成分。
这种情况下需要先进行中心标准化,然后构建协方差矩阵,而更多时候可以直接使用变量的相关系数矩阵代替协方差矩阵作为主成分分析的基础。大部分软件的主成分分析默认都是使用相关系数矩阵而非协方差矩阵的。
4)主成分的解释
可以根据每个主成分对应的主成分方程来解释主成分的含义,如下面的主成分方程:P1=β11X1+β12X2+…+β13Xp
若|β12|最大,则X2所占权重最大,该主成分就可以使用变量X2的实际含义解释。不过在很多情况下,主成分方程的系数差异不大,此时解释起来会比较困难,应使用因子旋转的因子分析法对主成分结果进行解释。
3、主成分分析的运用
1)综合打分:
这种情况在日常工作中经常遇到,如员工绩效的评估和排名、城市发展综合指标等。这种情况只要求得出一个综合分数,因此使用主成分分析比较适合。相对于单项成绩简单加总的方法,主成分分析会使评分更聚焦于单一维度上,即更关注这些原始变量的共同部分,去除掉不相关的部分。不过当主成分分析不支持取一个主成分时,就不能使用该方法了。
2)对数据进行描述:
描述产品情况,如子公司的业务发展状况、区域投资潜力等,这些情况通常需要将多个变量压缩到少数几个主成分进行描述,能压缩到两个主成分是最理想的。这类分析一般只进行主成分分析是不适宜的,进行因子分析会更好。
3)为聚类或回归等分析提供变量压缩。
消除数据分析中的共线性问题,常用的有三种方法:①在同类变量中保留一个最有代表性的变量,即变量聚类;②保留主成分或因子;③从业务理解上进行变量修改。主成分分析是以上3个方面的基础。
4)去除数据中的噪声:
如图像识别。
4、实战案例:在Pyton中实现主成分分析
5、基于主成分的冗余变量筛选
在进行数据分析时有两种数据的筛选。第一种是变量的价值,考量纳入模型的变量是否对被解释变量有解释力度,这类筛选方法使用的是有监督筛选法,即统计检验方法。第二类是变量的信息冗余,考量纳入模型的变量是否有强线性相关性,这类筛选方法使用无监督筛选法,即变量聚类的方法。
首先根据所有输入变量之间的相关性将它们分成不同的类,然后在每个类中找出一个最有代表性的变量。

变量选取的思路:

四、因子分析
因子旋转法的因子分析是主成分分析的延伸,最早由英国心理学家C.E.斯皮尔曼提出,他发现学生的各科成绩之间存在着一定的相关性,某科成绩好的学生往往其他科成绩也比较好,从而推想是否存在某些潜在的共性因子,或者某些一般智力条件影响着学生的学习成绩。因子分析可在许多变量中找出隐藏的具有代表性的因子。将相同本质的变量归入一个因子,可减少变量的数目,还可检验变量间关系的假设。
统计学家发明了因子旋转法,尽量加大主成分在原始变量上权重的差异性,使得原本主成分权重小的因子权重更小,原本主成分权重大的因子权重更大,最终提高了主成分的可解释性。这就是因子旋转法的思路。
1、因子分析模型
主成分分析的问题在于得到的主成分有时极不好解释。如果希望得到的主成分具有更好的可解释性,就需要用到因子分析。
因子分析的方法众多,如极大似然法、主成分法。本节讲解的是基于主成分的因子分析法,该方法是在主成分分析的基础上进行因子旋转,使得主成分更容易解释(称为因子),即可对因子的含义做出比较明确的解释。
1)因子分析模型
假设随机变量的集合X=(X1, X2, …, Xp)
因子分析模型可以被写为:
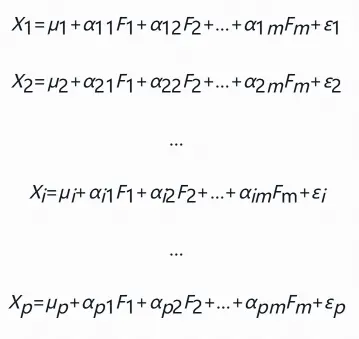
aim代表变量Xi的第m个公共因子Fm的因子的系数,又被称为因子载荷;εi表示公共因子外的随机因子;μi表示Xi的均值,因子载荷矩阵为:
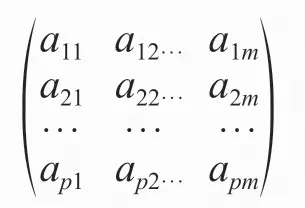
这里公共因子Fm是一个不可观测的内在属性或特征,并且公共因子和随机因子两两正交,这与主成分分析中的主成分两两正交类似。另外,m一般小于或等于p,否则就不能达到以少数因子表达多数变量信息的目的。
2)因子分析模型的矩阵形式
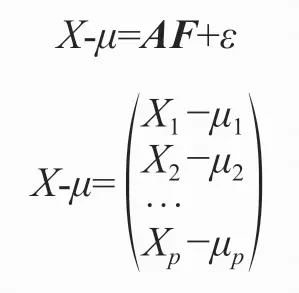
A表示因子载荷矩阵:
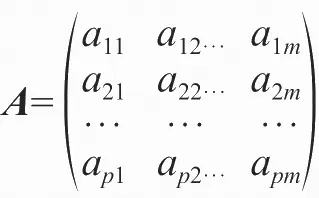
F表示公共因子向量,F=(F1, F2, …, Fm);ε为随机因子向量,ε=(ε1, ε2, …, εp)。
3)因子分析中的几个重要概念
(1)因子载荷。因子载荷aim的统计意义就是第i个变量与第m个公共因子的相关系数,表示Xi依赖Fm的份量(比重),统计学术语称作权重,心理学家把它叫作载荷。aim的绝对值越大,表示相应的公共因子Fm能提供表达变量的信息越多,即认为信息更多“承载”在该因子上面。
(2)变量共同度。共同度是指一个原始变量在所有因子上的因子载荷平方和,代表所有因子合起来对该原始变量的变异解释量,我们知道因子用来代替繁多的原始变量的简化测量指标,那么共同度高即代表某个原始变量与其他原始变量相关性高,而共同度低则表明该原始变量与其他原始变量相关性很低,也就是说,这个原始变量的独特性很强。若其值接近1,则说明因子分析的效果不错。
(3)方差贡献。公共因子Fm的方差贡献就是在所有变量中该公共因子的因子载荷平方和,用其可以衡量公共因子Fm能够提供多少信息。
2、因子分析算法
1)因子载荷矩阵的估计:主成分分析法
假设随机变量的集合X=(X1, X2, …, Xp),其协方差矩阵为∑,设该协方差矩阵的特征值为λ1>λ2>…>λk,相对应的特征向量为:
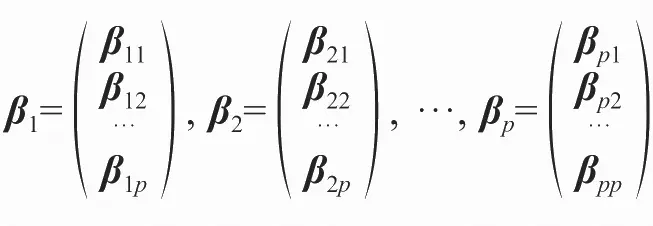
那么这个协方差矩阵有:
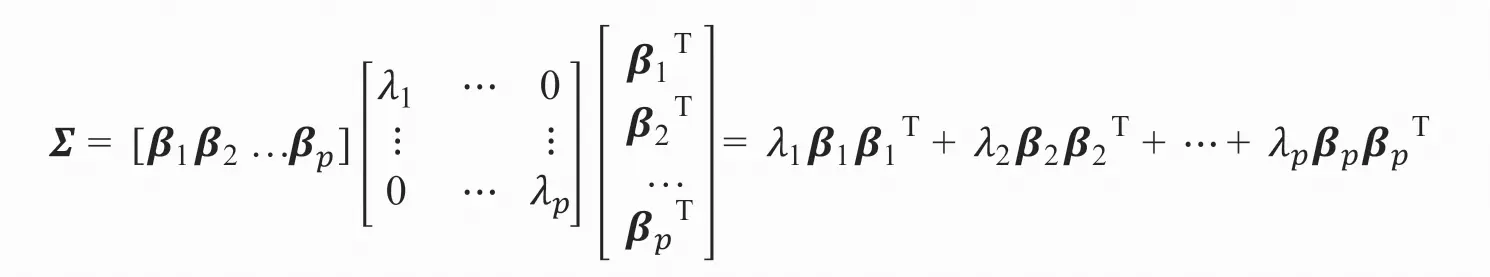
假设P个公共因子中前m个公共因子贡献较大,则上述公式可以写为:
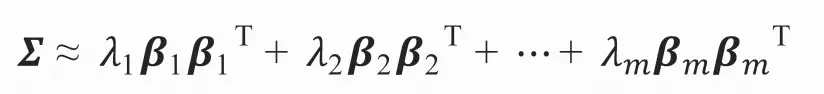
同时,我们又知道因子模型的矩阵形式可以写为:X-μ=AF+ε
可以推导:
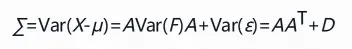
其中,A表示因子载荷矩阵,D表示随机因子的协方差矩阵。所以:
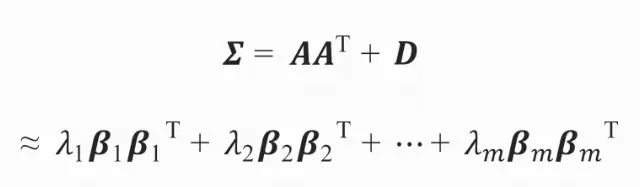
则:
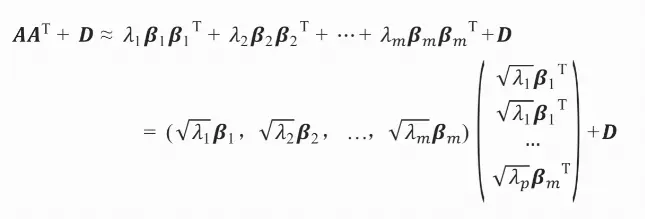
因子载荷矩阵的估计值为:
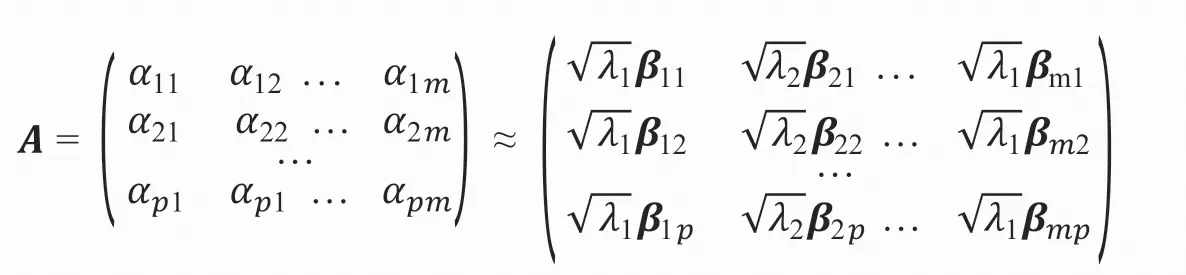
对于变量Xi的第m个公共因子Fm,其因子载荷的估计值为![]() ,因子方程可以写为:
,因子方程可以写为:
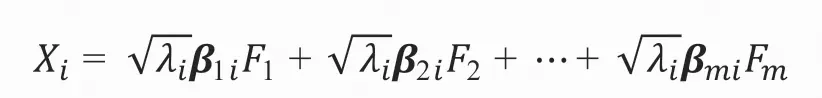
2)因子旋转——最大方差法
有些时候,估计出的因子载荷在各个因子上不太明显与突出,在解释因子时有困难。而因子载荷矩阵并不唯一,可以通过旋转的方式突出因子的特征,便于解释
因子旋转前,散点代表原始变量在因子(与主成分概念一致)上的权重数值,由于所有变量在第一个因子上的权重均高,因此不好解释其含义。
因子旋转后,有的权重在第一个因子上高,有的权重在第二个因子上高,因此便于解释每个因子的含义。
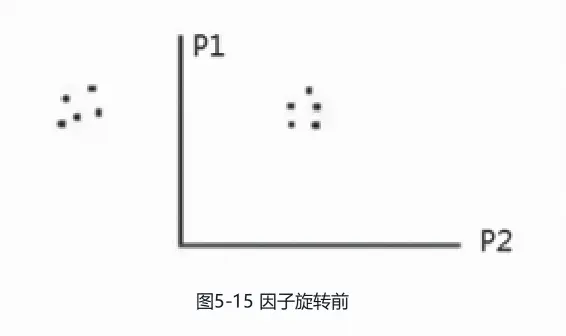
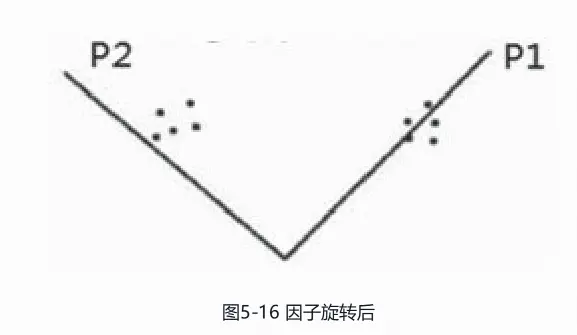
这里使用最大方差法进行因子旋转,最大方差法的思想是使因子载荷的平方和最大,即使因子贡献的方差最大,这样可以使得各个因子的载荷尽量拉开距离,让某些载荷偏大而另一些载荷偏小,从而达到便于解释因子的目的。
3)因子得分
公共因子本身是未知变量,一般通过因子载荷对因子进行定性解释。接下来需要对公共因子本身的数值进行下一步分析,这里就涉及因子得分。
在估计因子得分时,一般以因子载荷矩阵为自变量,以X-μ为因变量,构造回归方程进行估计:
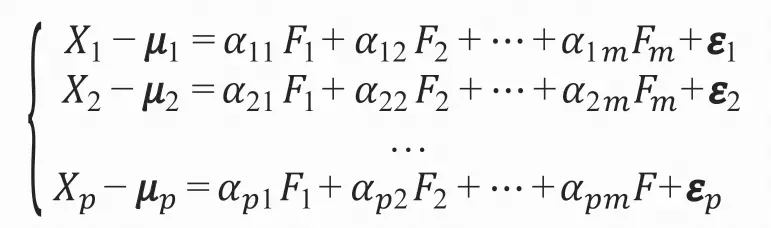
因为随机因子向量ε方差不齐,所以估计方法为加权最小二乘法,这里不再详细介绍。于是对于随机变量集合X的某个观测,就可以估计其在各个公共因子上的得分了。
4)因子分析总结
(1)因子分析是主成分分析法的拓展,可以很好地辅助进行维度分析。
(2)对于缺乏业务经验的数据分析人员来说,可以通过观察每个原始变量在因子上的权重绝对值来给因子命名。而业务知识丰富的数据分析人员已经对变量的分类有一个预判,并且可以通过不同的变量转换方式和旋转方式使得预判为同一组的原始变量在共同的因子上权重绝对值最大化。所以,因子分析的要点在于选择变量转换方式。
(3)因子分析是构造合理的聚类模型的必然步骤,也是在建立分类模型时重要的维度分析手段。在这方面,主成分回归法只是在建模时间紧张和缺乏业务经验情况下的替代办法。
3、实战案例:在Python中实现因子分析
五、多维尺度分析
在商业分析中,经常需要了解不同观测之间(不同产品之间、不同服务之间、不同品牌或体验之间等)的差异程度或相似程度,用以发现产品间的关系、明确互相竞争的产品、发现市场机会等。差异性或相似性一般用不同观测间的“距离”来衡量。
由于需要比较的距离是多个观测之间的,而且一般要求在二维或三维空间中展示出来(用于直观比较并发现特征),因此出现了一种被称为多维尺度分析(Multi-Dimensional Scaling, MDS)的技术。如果各个变量为连续型变量,则相应的多维尺度分析也被称为计量多维尺度(Metric MDS, MMDS)。相对地,基于等级变量的多维尺度分析被称为非计量多维尺度(Nonmetric MDS, NMMDS),如用户对不同品牌相似度的评分属于定序分类型变量,需要使用NMMDS分析。
多维尺度分析会在原始距离矩阵的基础上,寻找每个观测在较低维度上的位置,以使得基于这个位置计算的距离矩阵与原始距离矩阵的差异尽可能小。
例如,城市间的距离是用球面(地球表面)上的相对位置计算出来的,可以将原始位置看作是三维的,经过多维尺度分析后,可以将每个点的位置坐标降到二维,因此多维尺度分析实际上也起到了降维的作用。图中的左图记录了城市间的距离,右图是经过MDS处理后的结果。
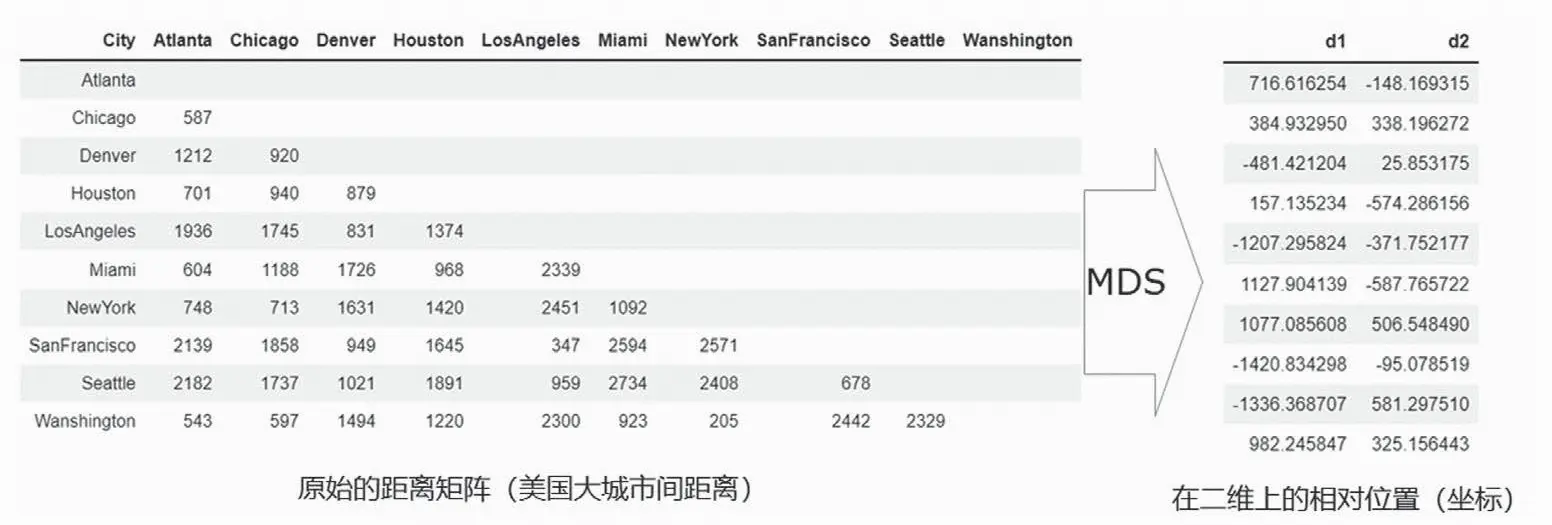
下面介绍多维尺度分析的计算原理。
原始数据矩阵为:
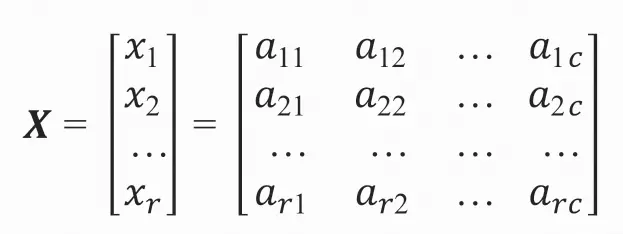
定义任意两个样本间的距离为(以欧氏距离为例):
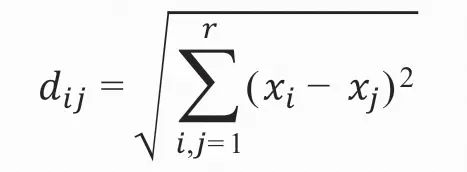
设需要求取的矩阵(在较低维空间上的位置)为M,M同样有r行,对应r个样本。
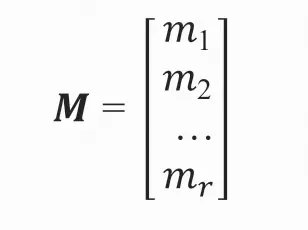
设定的目标函数(被称为应力函数或压力函数)为:
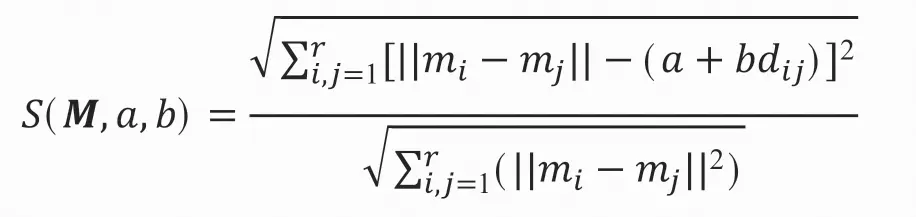
多维尺度分析的问题就是取M、a、b,使得压力函数最小,即:
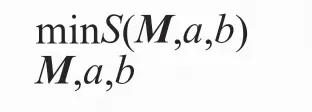
使用前面的城市间距离矩阵,经过MDS处理后,在输出的评估结果中,Stress为模型压力函数收敛后的最小值,RSQ为总变异中能被相对距离所解释的比例,本例中为0.99996,说明模型的解释力度很强:

可以使用Python代码实现MDS算法过程,先导入数据并查看数据,代码如下: