二、数据处理(Pandas读写数据、数据查询/类SQL操作、数据清洗)
2024-09
浏览量:321
本文字数:10130
读完约 34 分钟
在实际的数据处理工作中,经常需要同时处理多张表,以及对多张表的字段进行合并、提取等操作。本章主要介绍数据处理的基本方法,包括数据读取、数据整合及数据清洗。
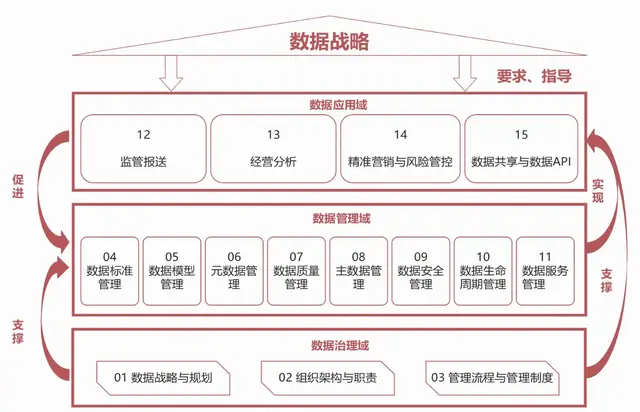
一、使用pandas读取结构化数据
pandas是Python中的一个库,它是基于NumPy开发的更高级的结构化数据分析工具,提供Series、DataFrame等数据结构,可以很方便地对序列、截面数据(二维表)进行处理。DataFrame即我们常见的二维数据表,包含多个变量(列)和样本(行),通常被称为数据框。Series是一个一维结构的序列,包含指定的索引信息,可以被视作DataFrame中的一列,其操作方法与DataFrame的操作方法相似。
按照惯例,pandas会以pd作为别名。
1、读取数据
使用pandas读取文件
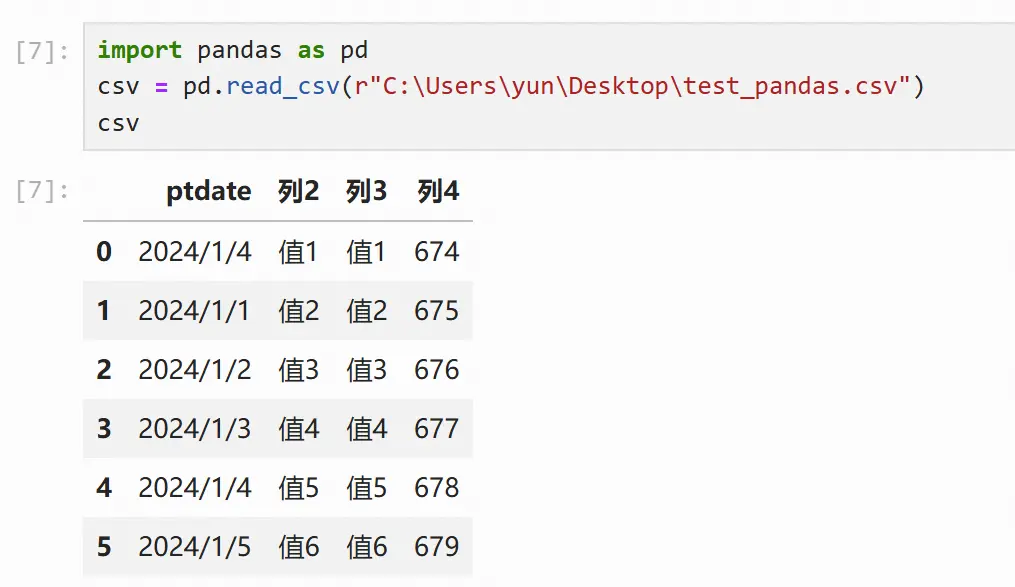
pandas.read_csv()
打印出来的DataFrame包含索引(index,第1列)、列名(column,第1行)及数据内容(values,除第1行和第1列外的部分)。
pandas除可以直接读取CSV、Excel、JSON、HTML等文件并生成DataFrame外,也可以从列表、元组、字典等数据结构中创建DataFrame。
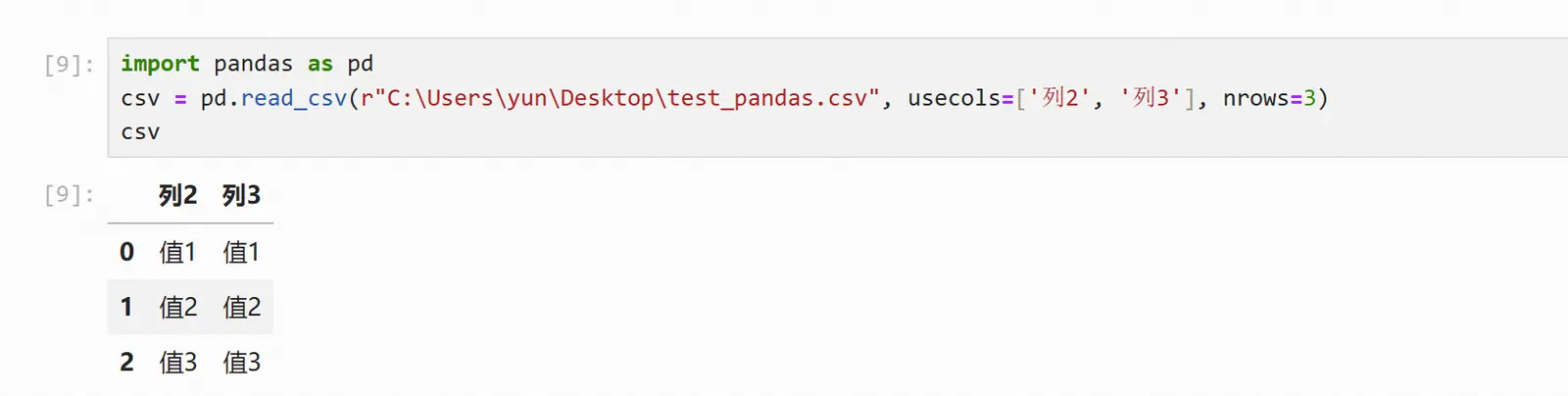
读取指定行和指定列
usecols=[], nrows=
使用分块读取
使用参数chunksize可以指定分块读取的行数(固定行数/对行进行分块),此时返回一个可迭代对象
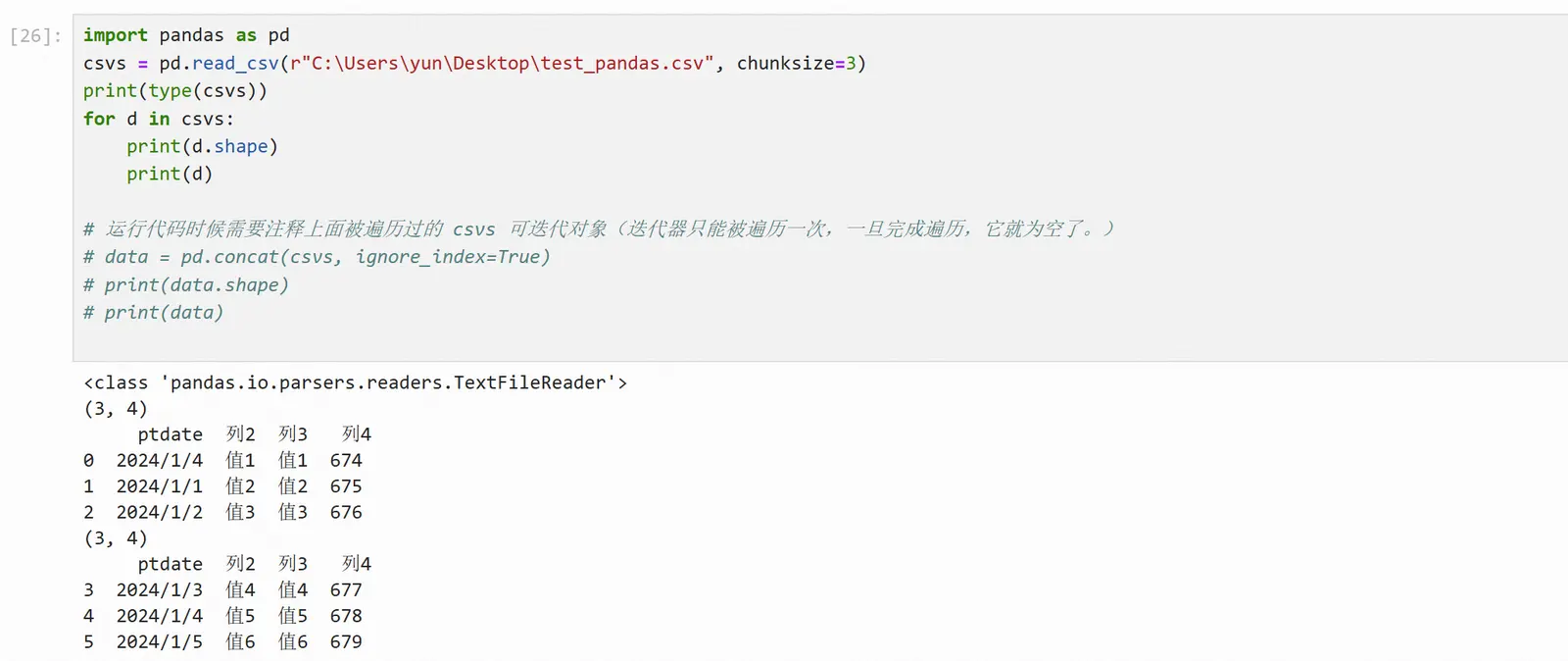
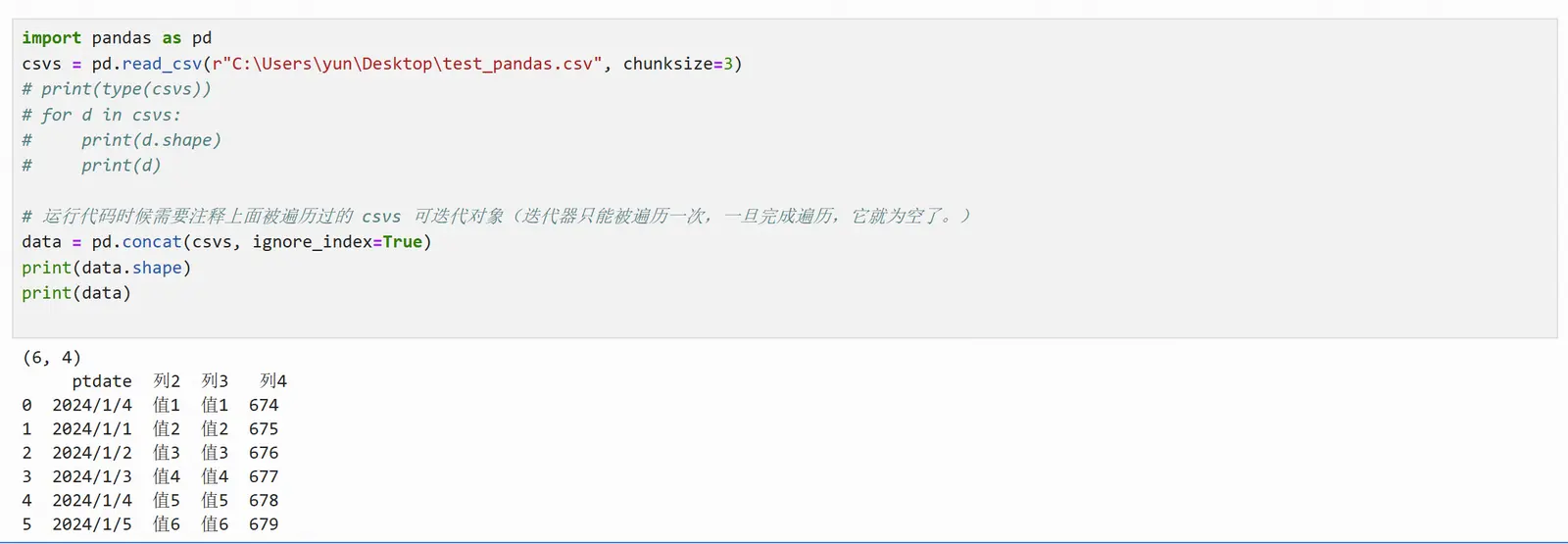
使用pd.concat函数读取全部数据
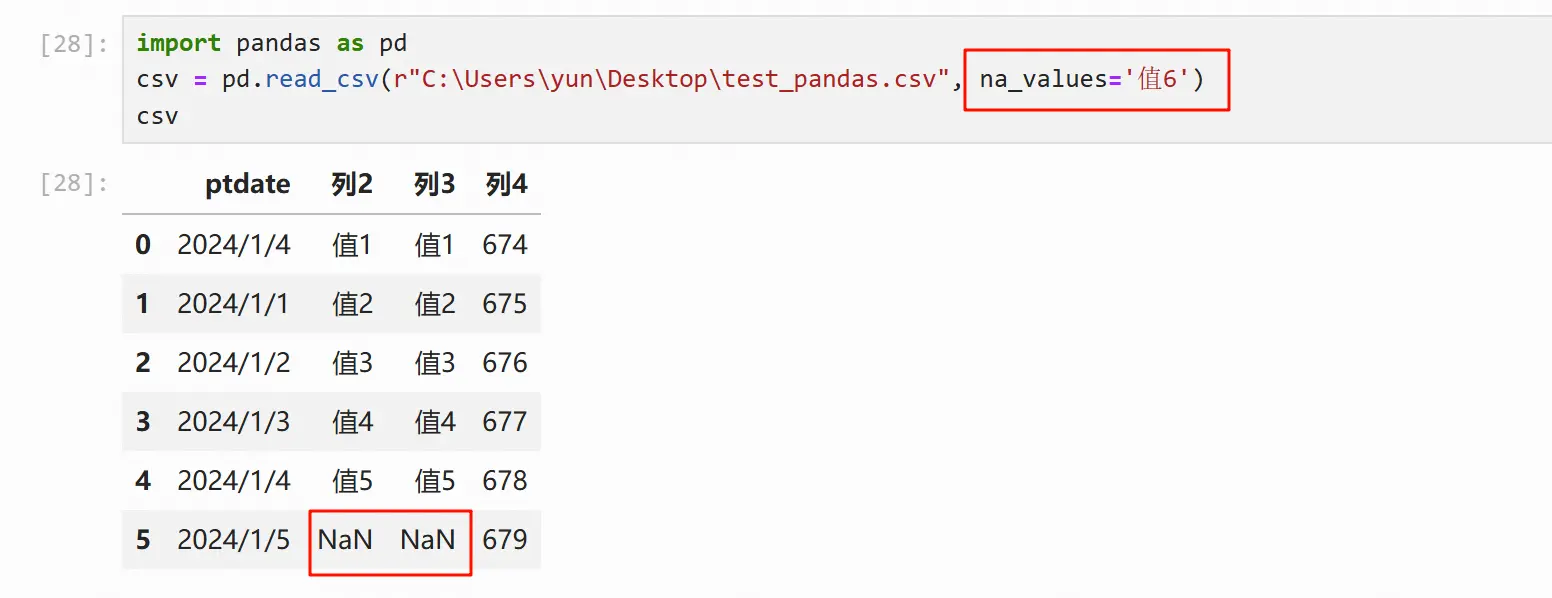
缺失值操作
使用 na_values 参数可以指定预先定义的缺失值(将某个值替换指定为缺失值NaN)
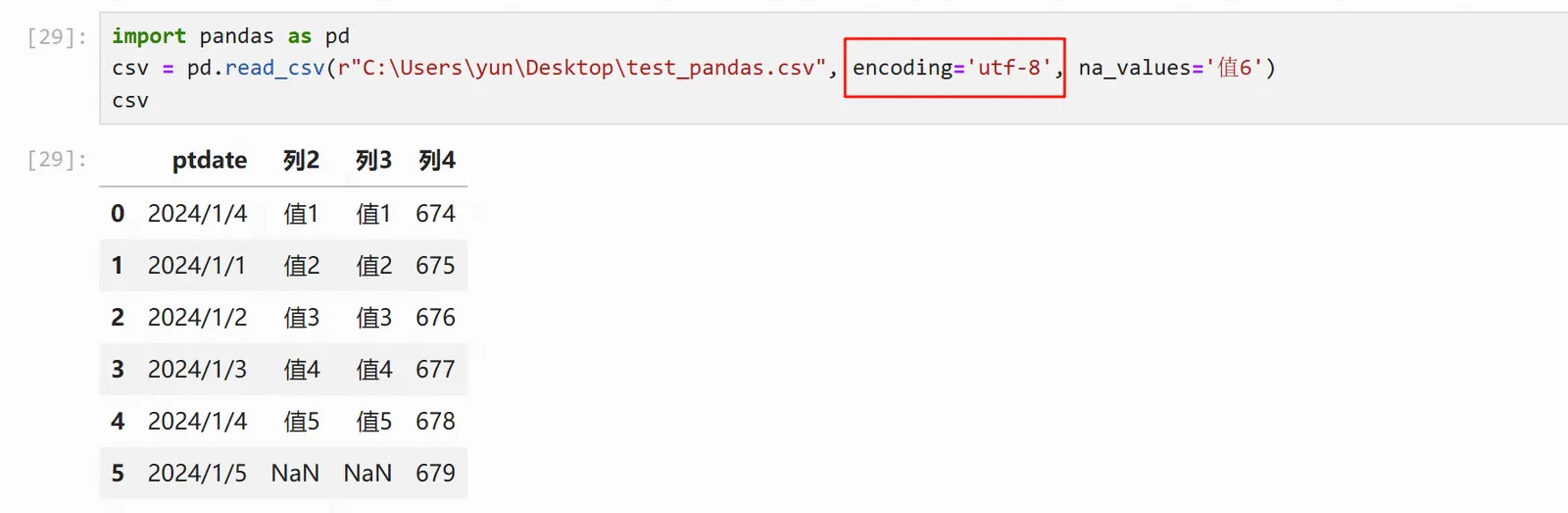
文件编码
参数encoding
2、写出数据
pandas的数据框对象有很多方法,其中pandas.to_csv方法可以将数据框对象以CSV格式写入本地
pandas.to_csv方法的常见参数:
path_or_buf:写入本地CSV文件的路径
sep=',':分隔符,默认为逗号
na_rep='':缺失值写入代表符号,默认为空''
header=True:bool类型,是否写入列名,默认为True
cols=[...]:list类型,写入指定列,默认为None
index=True:bool类型,是否写出索引列,默认为True
encoding=str:str类型,以指定编码写入
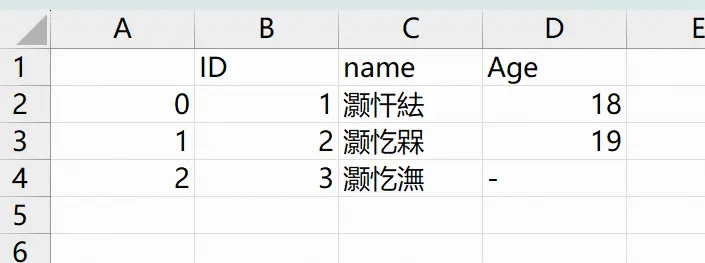
import pandas as pd
import numpy as np
df = pd.DataFrame({'ID':[1, 2, 3], 'name':['小张', '小明', '小李'], 'Age':[18, 19, np.nan]})
df.to_csv(r"C:\Users\yun\Desktop\test_pd_to_csv.csv", encoding='utf-8', na_rep='-')结果:win下出现乱码;需要修改编码 encoding='gb2312'
二、数据整合
涉及NumPy的操作
1、行、列操作
使用pandas数据框可以方便地选择指定列、指定行。
构造数据:通过函数np.random.randn(4, 5)生成一个4行5列的正态分布随机数组,利用这个数组生成一个数据框
import numpy as np
import pandas as pd
# 为保证代码每次运行都能得到同一组数据设置随机数种子
np.random.seed(0)
sample = pd.DataFrame(np.random.randn(4, 5), columns=list("abcde"))
sample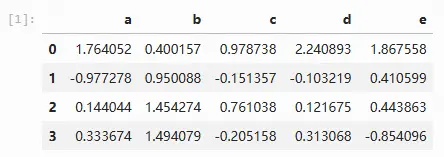
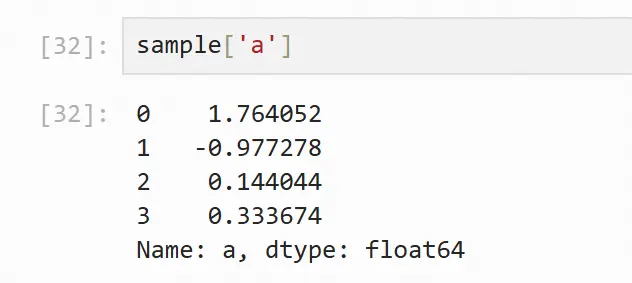
选择单列:
最直接的方法是用列名选择列
数据框的 iloc 方法和 loc 方法都可以用于选择行、列。
iloc 方法基于位置的索引,只能使用索引位置信息选择行、列。
loc 方法基于标签的索引,只能使用索引名字即行名或列名选择行、列。
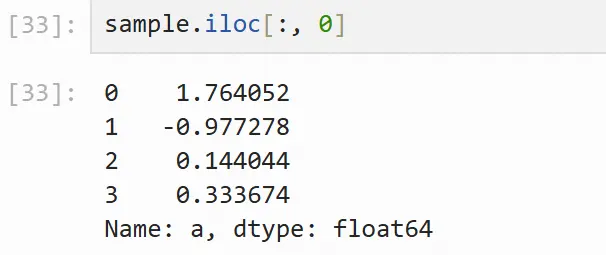
使用iloc方法选择a列:
# 所有行,索引 0 的列 sample.iloc[:, 0]
使用loc方法选择a列:
# 所有行,列标签名为 a 的列 sample.loc[:, 'a']
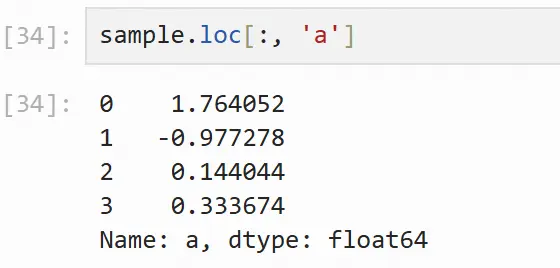
在选择单列时,返回的是pandas序列结构的类,也可以使用以下方式在选择单列时返回 pandas 数据框类
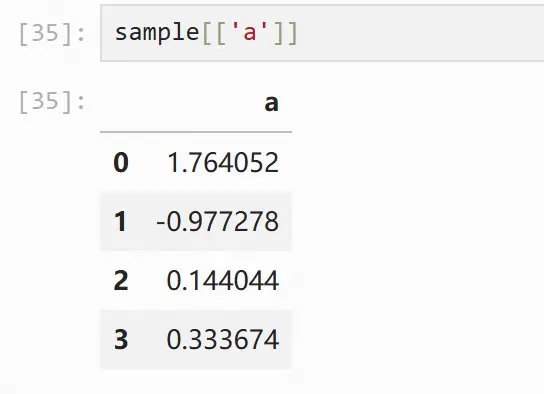
选择多行和多列:
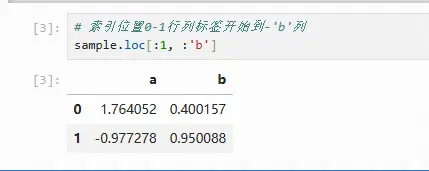
在使用数据框选择行时,可以直接使用行索引进行选择(注意在使用基于标签的索引即loc方法选择时,索引区间是全闭的)
# 索引位置0-1行列标签开始到-'b'列 sample.loc[:1, :'b']
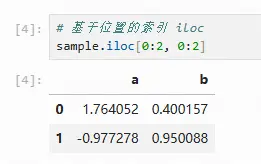
使用基于位置的索引即iloc方法进行选择
# 基于位置的索引 iloc sample.iloc[0:2, 0:2]
创建和删除列
创建新列的两种方法:
列赋值
# 新建new_col列,取值由已知两列的值计算得出 sample['new_col']=sample['a']-sample['b'] sample

数据框的 assign 方法(使用这个方法生成的新变量并不会被保留在原始表中,需要赋值给新表才可以保存)
sample.assign(new_col_2=sample['a']-sample['b'], new_col_3=sample['a']+sample['b']) sample

sample.assign(new_col_2=sample['a']-sample['b'], new_col_3=sample['a']+sample['b'])

删除列
数据框的drop方法,默认返回一个新对象,并不会对原始表产生影响。如果需要删除原表的数据并保留结果,可以通过参数进行设置。
常用参数详解:
labels:待删除的行名or列名;
axis:删除时所参考的轴,0为行,1为列;
index:待删除的行名
columns:待删除的列名
level:多级列表时使用,暂时不作说明
inplace:布尔值,默认为False,这是返回的是一个copy;若为True,返回的是删除相应数据后的版本
errors:一般用不到,这里不作解释
sample.drop(columns=['a', 'b'])

sample.drop(columns=['a', 'b']) # 原表数据没有变 sample

2、条件查询
单条件
一般使用比较运算符。比较运算符有>、==、<、>=、<=、!=。比较运算符产生布尔类型的索引可用于条件查询。
# 构造数据
sample=pd.DataFrame({'group':[1,1,2,1,2,3], 'name':['小张', '小赵', '小李', '小王', '小陈', '小刘'], 'score':[98, 78, 88, 65, 50, 70]})
sample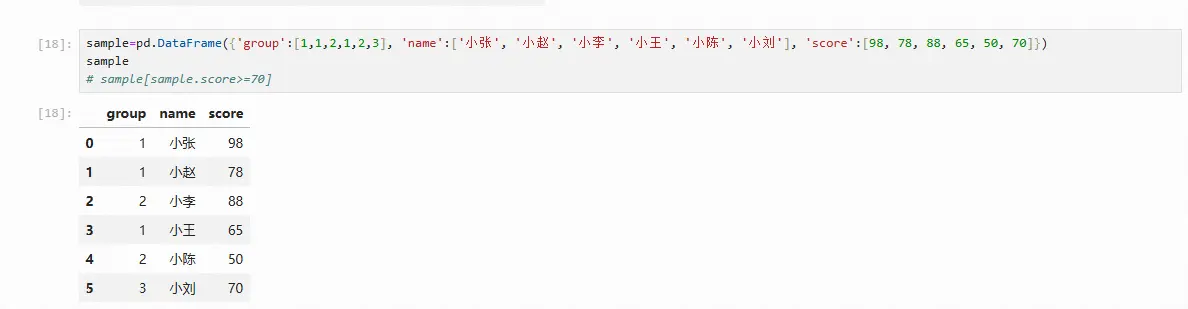
生成bool索引:

通过指定索引进行条件查询,返回bool值为True的数据:
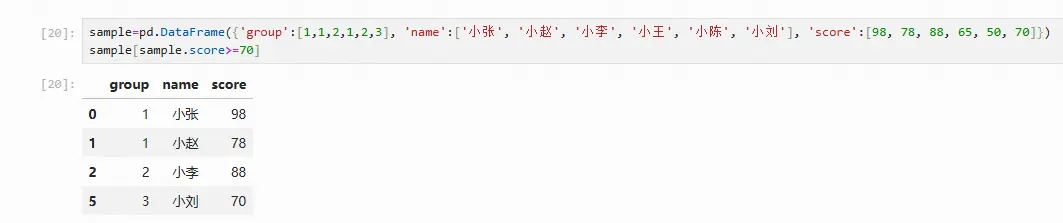
多条件
在多条件查询时,涉及bool运算符,pandas支持的bool运算符有&、~、|,分别代表逻辑运算“与”“非”“或”。
sample[(sample.score>=70)&(sample.group==2)]

sample[~(sample.group==1)]
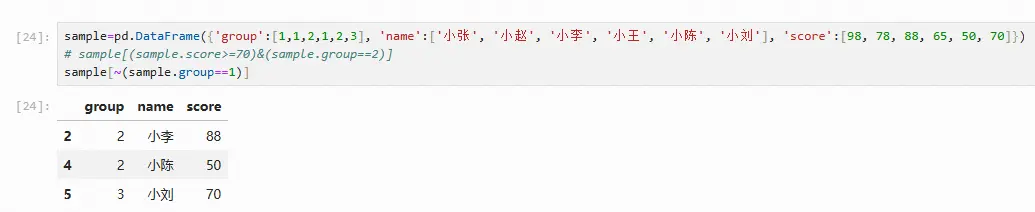
sample[(sample.group==1)|(sample.score>70)]
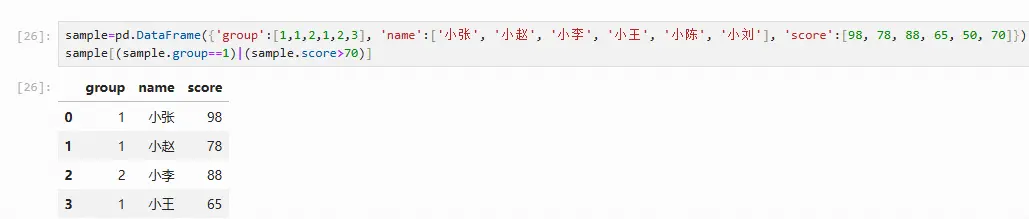
使用query
pandas数据框提供了query方法,用于完成指定的条件查询。
sample.query('score>90')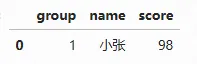
多条件查询的写法与bool索引的写法类似:
sample.query('(score>80)|(group==2)')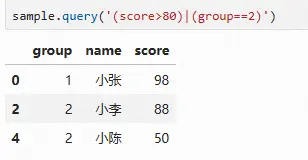
其他
pandas常用条件查询方法
between:DF[DF.col.between(10,20)],默认为闭区间,区间设置参数 inclusive 其取值为 'both', 'left', 'right', or 'neither'(是否:都包含、左包含、右包含、都不包含)
isin:DF[DF.col.isin(10,20)]
str.contains:DF[DF.col.str.contains('[M]+')]
import pandas as pd
sample=pd.DataFrame({'group':[1,1,2,1,2,3], 'name':['小张', '小赵', '小李', '小王', '小陈', '小刘'], 'score':[98, 78, 88, 65, 50, 70]})
# 左闭右开区间 inclusive='left'
sample[sample['score'].between(50, 70, inclusive='left')]
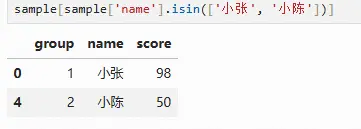
sample[sample['name'].isin(['小张', '小陈'])]
sample[sample['name'].str.contains('[李|刘]+')]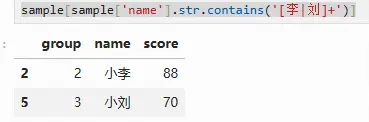
3、横向连接
pandas数据框提供了merge方法以完成各种表的横向连接操作,这种连接操作与SQL中的连接操作是类似的,包括内连接和外连接。此外,pandas也提供了按照行索引进行横向连接的方法
内连接
内连接使用merge函数,根据公共字段保留两张表共有的信息,how='inner'表示使用内连接,on表示两张表连接的公共字段,若公共字段在两张表中名称不一致,则可以通过left_on和right_on指定
import pandas as pd
data1 = pd.DataFrame({'col1':list('abcd'), 'id':[1,2,3,4]})
data2 = pd.DataFrame({'col1':list('ef'), 'id':[3,6]})
data1.merge(data2, how='inner', on='id')
data1.merge(data2, how='inner', left_on='id', right_on='id')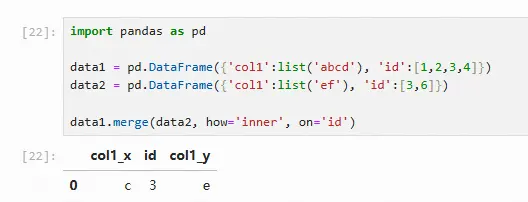
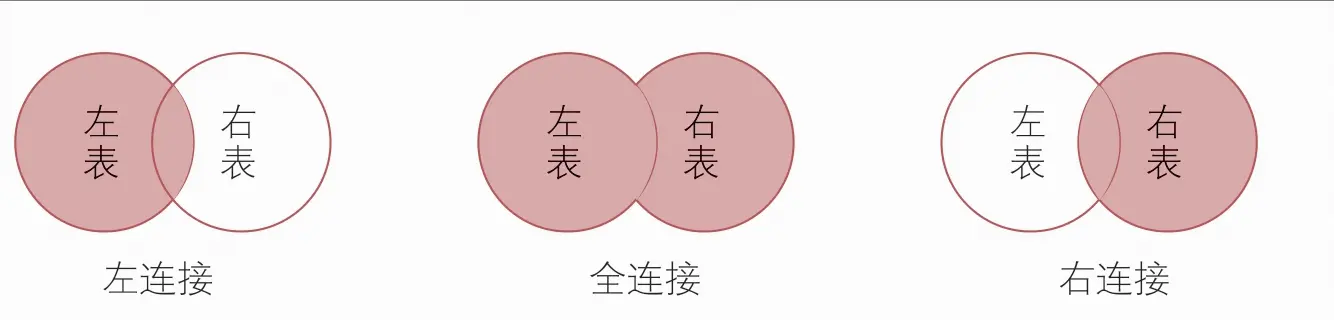
外连接
外连接(Outer join)包括左连接(Left join)、右连接(Right join)和全连接(Fulljoin)3种
left join:how='left'
right join:how='right'
full join:how='outer'
行索引连接
pandas还提供了直接按照索引连接,使用pd.concat函数或数据框的join方法
import pandas as pd
data1 = pd.DataFrame({'col1':list('abc'), 'id':[1,2,3]}, index=[1,2,3])
data2 = pd.DataFrame({'col1':['aa','bb', 'cc'], 'id':[1,2,3]}, index=[1,3,2])
# 当参数axis=1时,表示进行横向合并
pd.concat([data1, data2], axis=1)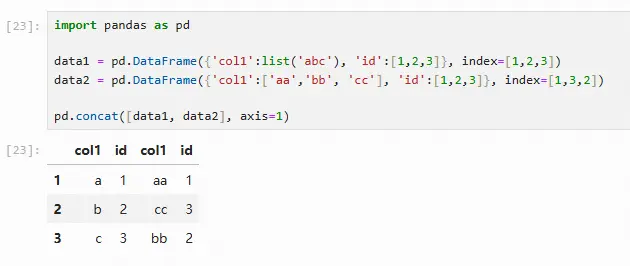
join:通过索引或者指定的列连接两个DataFrame
语法:DataFrame.join(other, on=None, how=’left’, lsuffix=”, rsuffix=”, sort=False)
参数:
other:【DataFrame,或者带有名字的Series,或者DataFrame的list】如果传递的是Series,那么其name属性应当是一个集合,并且该集合将会作为结果DataFrame的列名
on:【列名称,或者列名称的list/tuple,或者类似形状的数组】连接的列,默认使用索引连接
how:【{‘left’, ‘right’, ‘outer’, ‘inner’}, default:‘left’】连接的方式,默认为左连接
lsuffix:【string】左DataFrame中重复列的后缀
rsuffix:【string】右DataFrame中重复列的后缀
sort:【boolean, default=False】按照字典顺序对结果在连接键上排序。如果为False,连接键的顺序取决于连接类型(关键字)。
import pandas as pd
data1 = pd.DataFrame({'col_1':list('abc'), 'id_1':[1,2,3]}, index=[1,2,3])
data2 = pd.DataFrame({'col_2':['aa','bb', 'cc'], 'id_2':[1,2,3]}, index=[1,3,2])
data1.join(data2)
# 当列名有重复时需要进行处理,增加列名后缀(lsuffix='_left', rsuffix='_right')
data1.join(data2, lsuffix='_left', rsuffix='_right')

4、纵向合并
数据的纵向合并指将两张表或多张表纵向拼接起来,将原来两张表或多张表中的数据整合到一张表上。
pandas中提供的pd.concat方法用于完成横向和纵向合并,当参数axis=0时,类似SQL中的UNION ALL操作。ignore_index=True表示忽略df1与df2原来的行索引,合并并重新排列索引
import pandas as pd
df1 = pd.DataFrame({'id':[1,2,3,4,5,6], 'col':list('abcdef')})
df2 = pd.DataFrame({'id':[7,8,9], 'col':list('ABC')})
# ignore_index=True表示忽略df1与df2原来的行索引,合并并重新排列索引
# 当参数axis=0时,类似SQL中的UNION ALL操作
pd.concat([df1, df2], axis=0)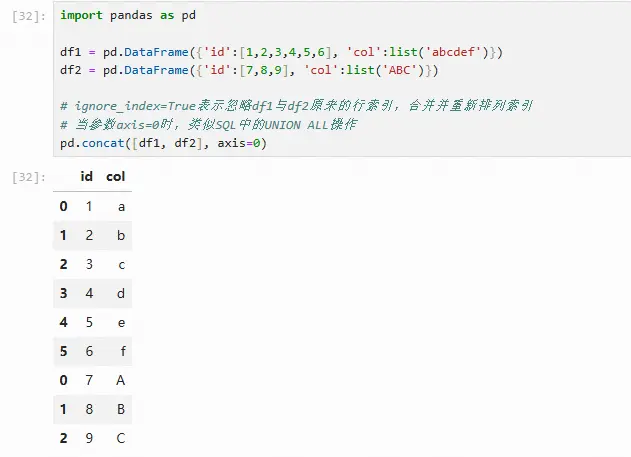
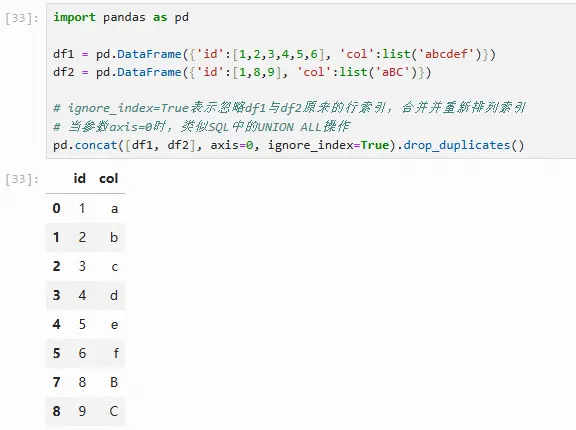
若希望纵向连接并去除重复值,可直接调用数据框的drop_duplicates方法,类似SQL中的UNION操作
import pandas as pd
df1 = pd.DataFrame({'id':[1,2,3,4,5,6], 'col':list('abcdef')})
df2 = pd.DataFrame({'id':[1,8,9], 'col':list('aBC')})
# ignore_index=True表示忽略df1与df2原来的行索引,合并并重新排列索引
# 当参数axis=0时,类似SQL中的UNION ALL操作
pd.concat([df1, df2], axis=0, ignore_index=True).drop_duplicates()df2 中的第一行(1, 'a') 会被去重删除
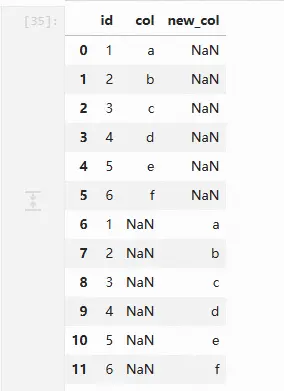
在进行纵向连接时,若连接的表的列名或列个数不一致,则不一致的位置会产生缺失值。
import pandas as pd
df1 = pd.DataFrame({'id':[1,2,3,4,5,6], 'col':list('abcdef')})
df2 = pd.DataFrame({'id':[1,8,9], 'col':list('aBC')})
df3 = df1.rename(columns={'col': 'new_col'})
df3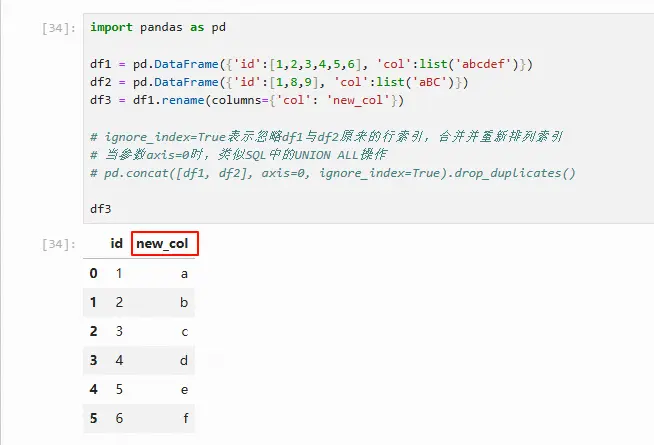
pd.concat([df1, df3], ignore_index=True, axis=0).drop_duplicates()
5、排序
pandas在排序时,根据排序的对象不同可分为sort_values和sort_index,分别表示按照数值进行排序和按照索引进行排序。
函数sort_values的第1个参数表示排序的依据列,此处设为score;ascending=False表示按降序排列,设为True时表示按升序排列(默认);na_position='last'表示缺失值数据排列在数据的最后(默认值),该参数还可以被设为first,表示缺失值排列在数据的最前面
import pandas as pd
import numpy as np
df = pd.DataFrame({'group': list('1234'), 'name': list('abcd'), 'score':[80,30, np.nan, 90]})
df.sort_values('score',ascending=False, na_position='last')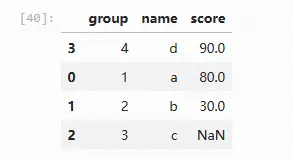
排序的依据变量也可以是多个列(与SQL同理)
import pandas as pd
import numpy as np
df = pd.DataFrame({'group': list('1124'), 'name': list('abcd'), 'score':[80,30, np.nan, 90]})
df.sort_values(['group', 'score'],ascending=False, na_position='last')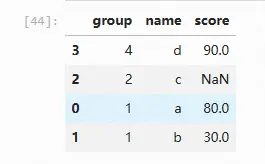
6、分组汇总
SQL中的group by语句。在分组汇总操作中,会涉及分组变量、度量变量和汇总统计量。pandas提供了groupby方法进行分组汇总。
分组变量
在进行分组汇总时,分组变量可以有多个,如按照年级、班级顺序对数学成绩进行均值查询,此时在groupby方法后接多个分组变量,以列表形式写出,结果中产生了多重索引,指代相应组的情况
测试数据如下:
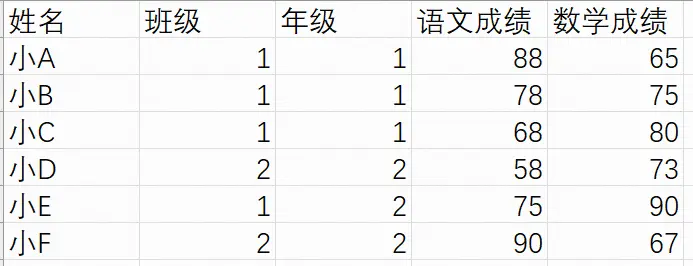
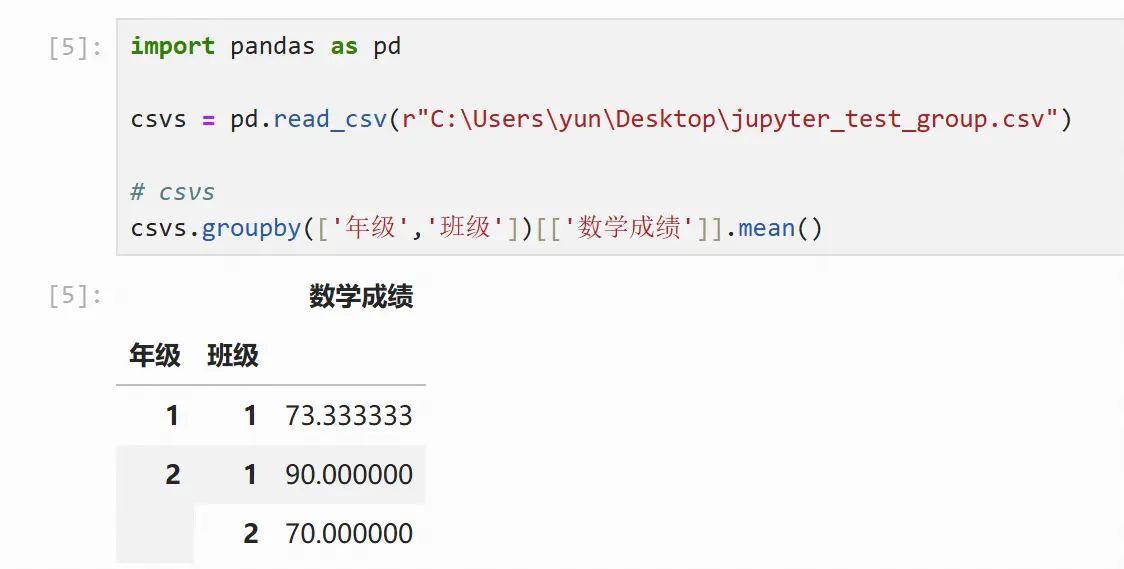
csvs.groupby(['年级','班级'])[['数学成绩']].mean()
度量变量
在进行分组汇总时,度量变量可以有多个
csvs.groupby(['年级'])[['数学成绩', '语文成绩']].mean()
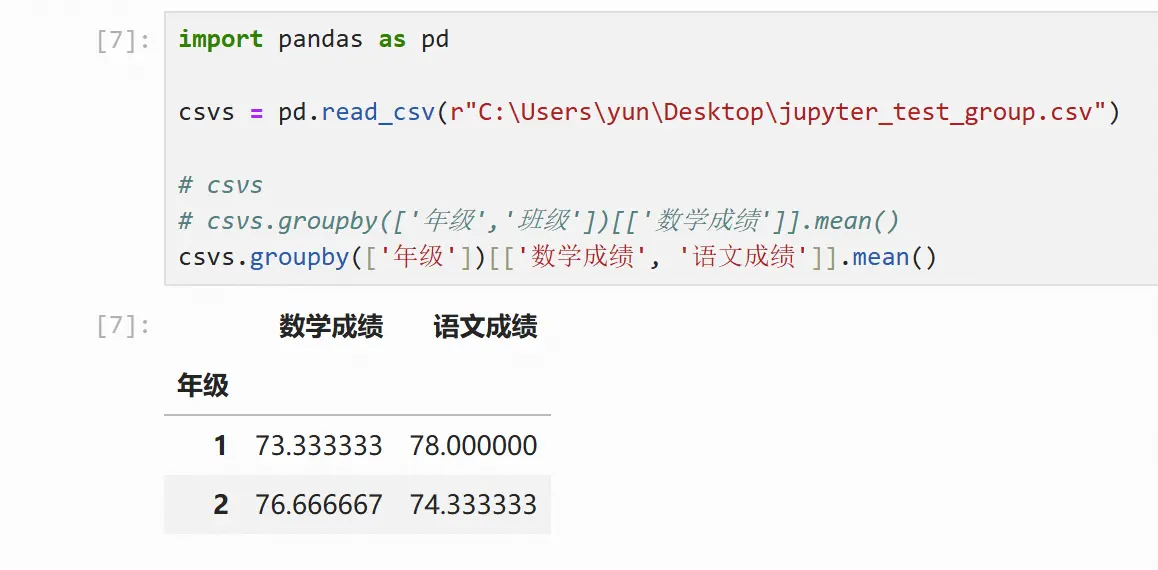
汇总统计量
mean:均值
max:最大
min:最小
median:中位数
std:标准差
mad:平均绝对偏差
count:计数
skew:偏度
quantile:指定分位数
这些统计量方法可以直接连接groupby对象使用。另外,agg方法提供了一次汇总多个统计量的方法。例如,汇总各个班级数学成绩的均值、最大值、最小值,代码如下(可在agg方法后接多个字符串用于指代相应的汇总统计量):
csvs.groupby(['班级'])[['数学成绩']].agg(['mean', 'min', 'max'])
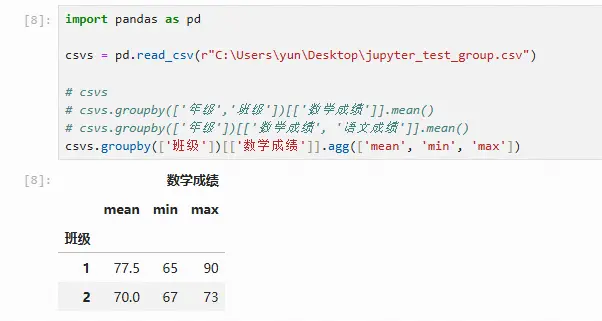
多重索引
在进行分组汇总操作时,产生的结果并不是常见的二维表数据框,而是具有多重索引的数据框。pandas开发者设计这种类型的数据框借鉴了Excel数据透视表的功能
csvs.groupby(['年级','班级'])[['数学成绩','语文成绩']].agg(['min', 'max'])
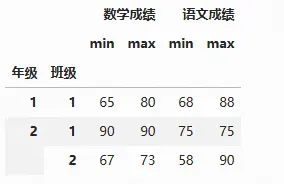
此时df数据框中有两个行索引和两个列索引。当需要筛选列时,第1个中括号表示筛选第1重列索引,第2个中括号表示筛选第2重列索引
df = csvs.groupby(['年级','班级'])[['数学成绩','语文成绩']].agg(['min', 'max']) df['数学成绩']['max']

也可以用loc方法查询指定的列,注意多重列索引以“()”方式写出:
df = csvs.groupby(['年级','班级'])[['数学成绩','语文成绩']].agg(['min', 'max'])
df.loc[:, ('数学成绩', 'max')]
7、拆分列
在进行数据处理时,有时要将原数据的指定列按照列的内容拆分为新的列。pandas提供了pd.pivot_table函数用于拆分列。
测试数据如下:
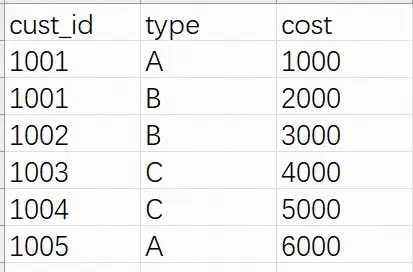
import pandas as pd table = pd.read_csv(r"C:\Users\yun\Desktop\jupyter_test_group.csv") pd.pivot_table(table, index='cust_id', columns='type', values='cost')
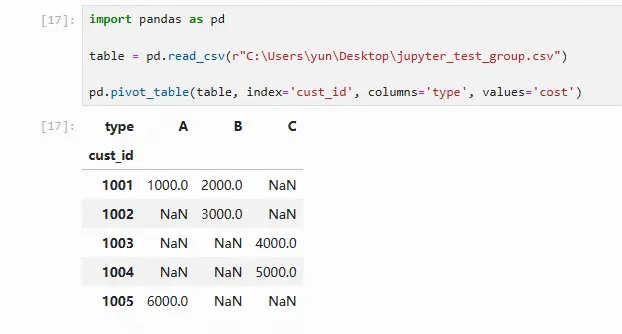
pd.pivot_table() 第1个参数为待拆分列的表 index表示原数据中的标示列 columns表示该变量中的取值将成为新变量的变量名 values表示待拆分的列 拆分列后默认使用的汇总函数为mean函数,且缺失值由NaN填补 fill_value参数和aggfunc函数用于指定拆分列后的缺失值和分组汇总函数
import pandas as pd able = pd.read_csv(r"C:\Users\yun\Desktop\jupyter_test_group.csv") pd.pivot_table(table, index='cust_id', columns='type', values='cost', fill_value=0, aggfunc='sum')
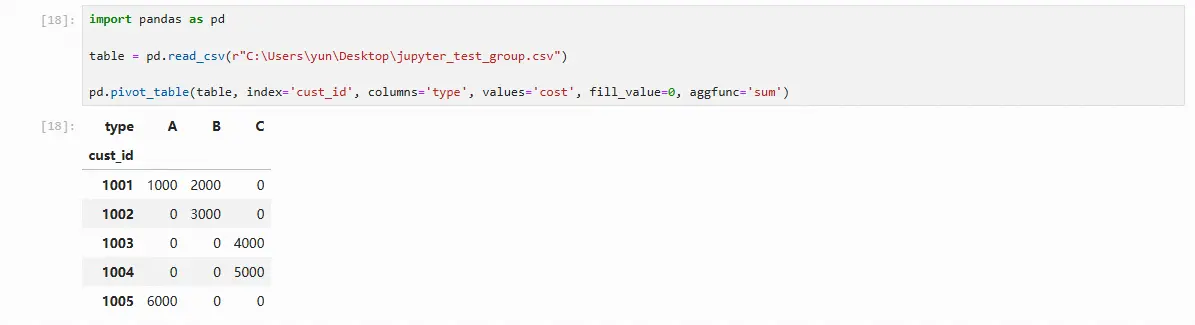
8、赋值与条件赋值
赋值
在一些特定场合下,如错误值处理、异常值处理,可能会对原数据的某些值进行修改,此时涉及类似SQL的insert或update操作。pandas提供了一些方法能够快速、高效地完成赋值操作。
replace方法替换值
# 替换成绩999为NaN sample.score.replace(999, np.nan)
当遇到一次替换多个值时,可以写为字典形式。
# 将sample数据框中score列所有取值为999的值替换为NaN、name列中取值为Bob的值也替换为NaN
sample.replace({'score':{999: np.nan}, 'name':{'Bob': np.nan}})条件赋值
条件赋值可以通过apply方法完成,pandas提供的apply方法可以对一个数据框对象进行行、列的遍历操作,将参数axis设为0时表示对行class_n进行循环,将axis设为1时表示对列进行循环,且apply方法后面接的汇总函数是可以自定义的。
测试数据;
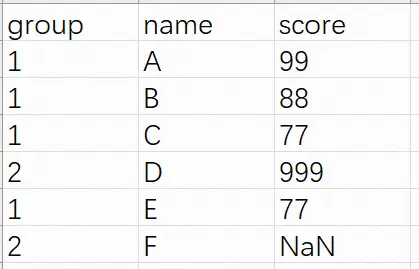
代码:
import pandas as pd
import numpy as np
sample = pd.read_csv(r"C:\Users\yun\Desktop\jupyter_test_group.csv")
def transform(sample):
if sample['group'] == 1:
return ('class1')
elif sample['group'] == 2:
return ('class2')
sample.apply(transform, axis=1)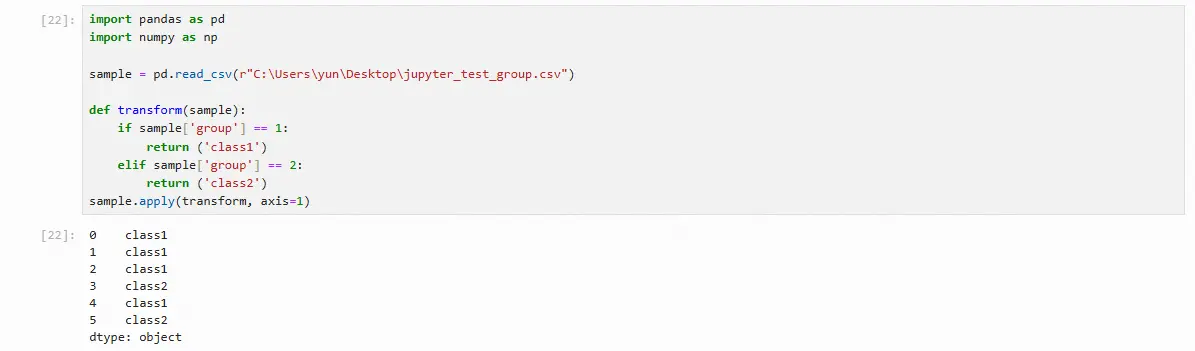
使用apply方法生成pd.Series类型的对象,进而可以通过assign将对象加入到数据中:
sample.assign(class_n = sample.apply(transform, axis=1))
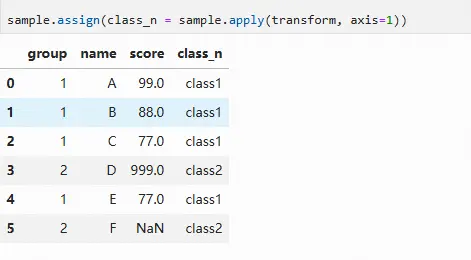
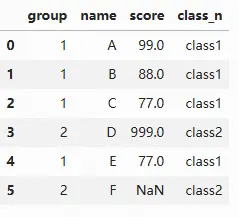
除apply方法外,还可以通过条件查询直接赋值,如下所示,注意第一句sample=sample.copy()最好不要省略,否则可能弹出警告信息:
import pandas as pd import numpy as np sample = pd.read_csv(r"C:\Users\yun\Desktop\jupyter_test_group.csv") # 进行copy,否则可能会弹出警告信息 sample=sample.copy() sample.loc[sample.group==1, 'class_n']='class1' sample.loc[sample.group==2, 'class_n']='class2' sample
三、数据清洗
数据清洗是数据分析的必备环节,在分析过程中,有很多不符合分析要求的数据,例如重复、错误、缺失、异常类的数据。
1、重复值处理
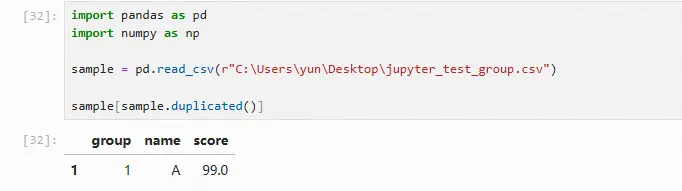
直接删除是处理重复数据的主要方法。pandas提供的查看和处理重复数据的方法分别为duplicated和drop_duplicates
测试数据;
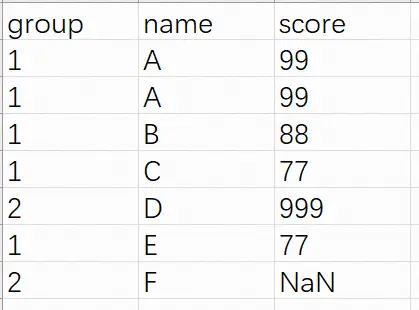
查看重复数据
代码:
import pandas as pd import numpy as np sample = pd.read_csv(r"C:\Users\yun\Desktop\jupyter_test_group.csv") # 查看重复数据 sample[sample.duplicated()]
删除重复数据
import pandas as pd import numpy as np sample = pd.read_csv(r"C:\Users\yun\Desktop\jupyter_test_group.csv") # 删除重复数据 sample.drop_duplicates()
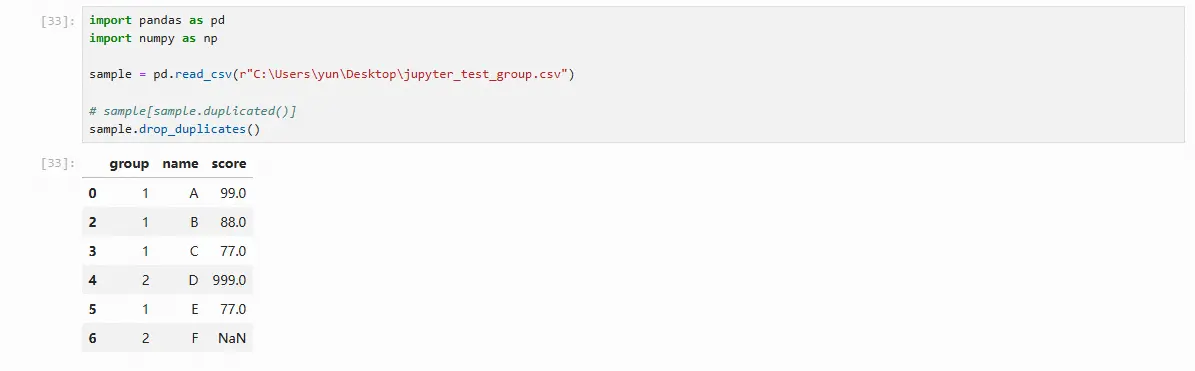
按列去重
# 删除 group 列重复的所有记录
sample.drop_duplicates('group')
2、缺失值处理
缺失值是数据清洗中比较常见的情况,缺失值一般由NaN表示,在处理缺失值时要遵循一定的原则。
首先需要根据业务理解处理缺失值,弄清楚缺失值产生的原因是故意缺失还是随机缺失,再通过一些业务经验进行填补。
一般来说,当缺失值数量少于20%时,连续变量可以使用均值或中位数填补;分类型变量不需要填补,单算一类即可,或者可以用众数填补。
当缺失值数量处于20%~80%时,填补方法同上,同时每个有缺失值的变量可以生成一个指示哑变量,参与后续的建模。
当缺失值数量多于80%时,每个有缺失值的变量生成一个指示哑变量,参与后续的建模,原始变量不再被使用。
pandas提供了fillna方法用于替换缺失值数据,其功能类似之前讲解的replace方法
查看缺失情况
测试数据:
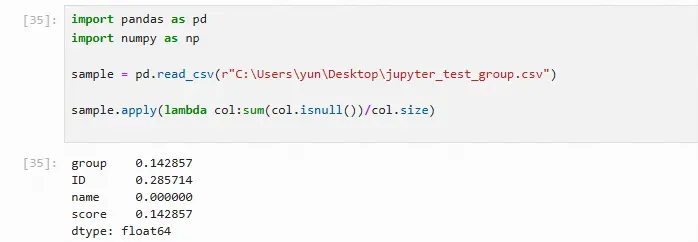
# 构造一个lambda函数查看缺失情况,在该lambda函数中,sum(col.isnull())表示当前列有多少缺失,col.size表示当前列总共有多少行数据 import pandas as pd import numpy as np sample = pd.read_csv(r"C:\Users\yun\Desktop\jupyter_test_group.csv") sample.apply(lambda col:sum(col.isnull())/col.size)
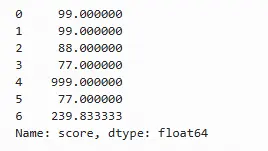
以指定值填补
pandas数据框提供了fillna方法完成对缺失值的填补,例如对sample表的score列填补缺失值,填补方法为均值:
sample.score.fillna(sample.score.mean())
缺失值指示变量
pandas数据框对象可以直接调用方法isnull,生成缺失值指示变量
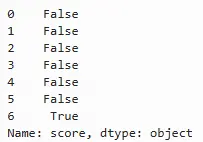
sample.score.isnull()
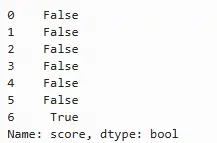
若想转换为数值0、1型指示变量,可以使用apply方法,int表示将该列替换为int类型:
sample.score.isnull().apply(int)
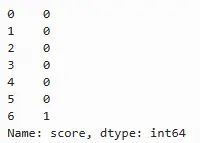
# str类 sample.score.isnull().apply(int)