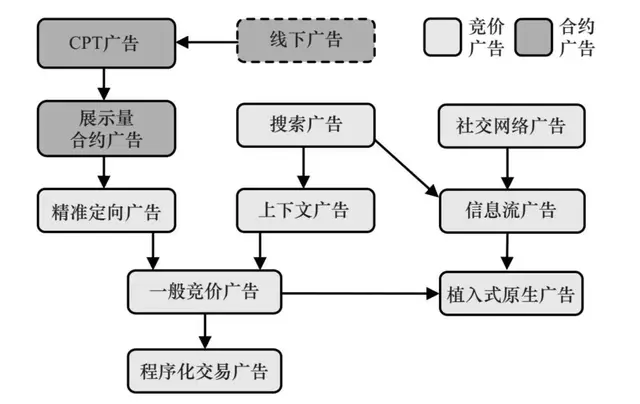
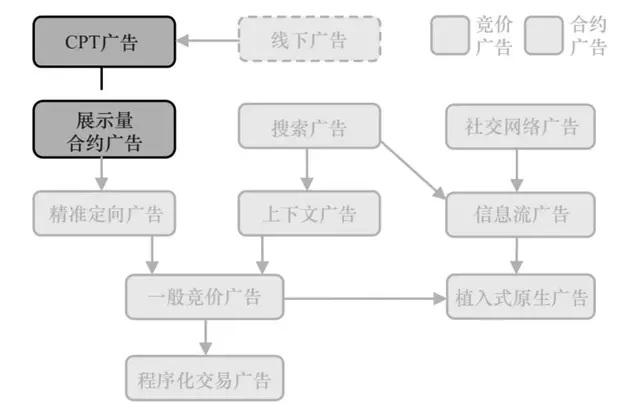
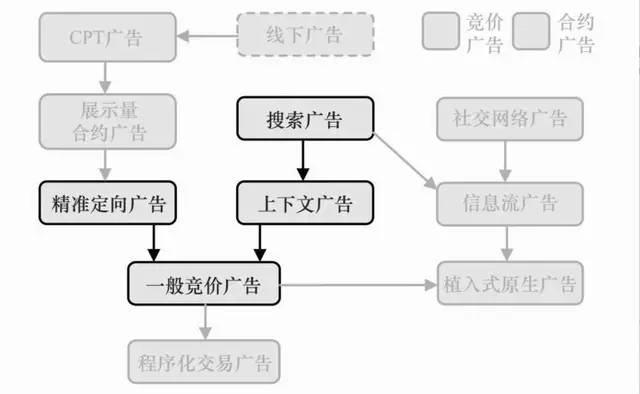
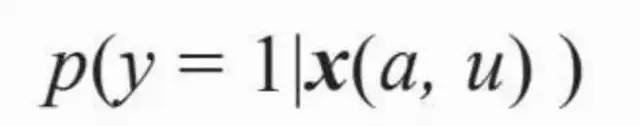计算广告关键技术4—受众定向核心技术(技术分类、上下文、行为、人口属性)
2024-10
浏览量:288
本文字数:2913
读完约 10 分钟
受众定向技术是对广告(a)、用户(u)、上下文(c)这3个维度提取有意义的特征(这些特征也称为标签)的过程。
上下文定向需要对广告所在的页面进行分析,然而这一分析过程与搜索引擎的爬虫有很大的不同。结合广告对上下文信息的需求特点,一般可以采用一种半在线的方式抓取和分析页面,这种方式避免了无效的页面分析计算,又能够快速地对需要分析的页面做出响应。
行为定向是根据用户历史上的网络访问行为对用户打标签的过程。
一、受众定向技术分类
总体上看,按照计算框架的不同,这些受众定向技术可以分为以下3种类型。
(1)用户标签,即可以表示成t(u)形式的标签,这是以用户历史行为数据为依据,为用户打上的标签。
(2)上下文标签,即可以表示成t(c)形式的标签,这是根据用户当前的访问行为得到的即时标签。
(3)定制化标签,即可以表示成t(a,u)形式的标签,这也是一种用户标签,不同之处在于是针对某一特定广告主而言的,因而必须根据广告主的某些属性或数据来加工。
二、上下文定向
(1)用规则将页面归类到一些频道或主题分类。例如,将auto.sohu.com下的网页归在“汽车”这个分类中。这种方法相对简单。
(2)提取页面中的关键词。这种方法是在将搜索引擎的关键词匹配技术推广到媒体广告上时自然产生的,也是上下文定向的基本方法。
(3)提取页面入链锚文本中的关键词。这种方法需要一个全网的爬虫作支持,因此已经超出了一般意义上广告系统的范畴。
(4)提取页面流量来源中的搜索关键词。这种方法除了页面内容,也需要页面访问的日志数据作支持,从技术方案上看更接近后面介绍的行为定向。
(5)用主题模型将页面内容映射到语义空间的一组主题上,这样做的目的是为了泛化广告主的需求,提高市场的流动性和竞价水平。
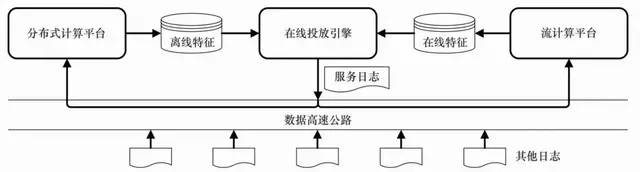
半在线抓取系统
(1)如果该请求的上下文URL在缓存中存在,那么直接返回其对应的标签。
(2)如果该URL在服务中不存在,为了广告请求能及时得到处理,当时返回空的标签集合,同时立刻向后台的抓取队列中加入此URL,这样在较短的一段时间(通常为秒至分钟量级)之后,该URL就被抓取下来,并打上标签存入缓存中。
(3)考虑到页面内容可能会不定期更新,可以设置缓存合适的TTL(time to live)以做到自动更新标签。
半在线的上下文抓取系统非常典型地揭示了在线广告系统弱一致的业务需求:只要保证大多数的广告决策最优正常,很少量的次优决策甚至随机决策都是可以接受的。充分把握这一特点,对于设计高效率、低成本的广告系统至关重要。
三、文本主题挖掘
根据上下文内容进行受众定向的粒度,可以精细到关键词,也可以粗略到页面的类型。除了这两种极端情况,我们也可以考虑将页面内容直接映射到一组有概括性意义的主题上,比如将一个讲编程语言的博客页面映射到“IT技术”这样的主题上。如果把页面视为一个文档,这就对应于文本主题模型(topicmodel)的研究问题。文本主题模型有两大类别:一种是预先定义好主题的集合,用监督学习的方法将文档映射到这一集合的元素上;另一种是不预先定义主题集合,而是控制主题的总个数或聚类程度,用非监督学习的方法自动学习出主题集合,以及文档到这些主题的映射函数。
1、LSA模型
文本主题模型最初的解决思路是对上面文档和词组成的矩阵X进行奇异值分解(singular value decomposition,SVD),找到这一矩阵的主要模式,这一方法称为潜在语义分析(Latent Semantic Analysis,LSA)
2、PLSI模型
概率潜在语义索引(Probabilistic Latent Semantic Indexing,PLSI)方法。PLSI方法是通过对文档生成的过程进行概率建模来进行主题分析的。
3、LDA模型
潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)方法。在LDA方法中,我们视PLSI模型的参数为随机变量。不过在实际的工程实践中,LDA模型更为常用的更新方法是吉布斯采样(Gibbs sampling)法,而且这种方法更容易实现分布式更新求解。
4、词嵌入word2ve
所谓词嵌入(word embedding),指的是将词级别的语义信息映射成稠密的实数向量来表达。具体来说,把词典大小的维度降维到一个K维的特征空间,每个词对应特征空间内的一个点,即一个K维的稠密的实数向量。相近的词会出现在特征空间中离得更近的地方,从而使词的表示具有一定的泛化性。
四、行为定向
行为定向需要进行大规模的数据挖掘,是在线广告中数据利用和变现最重要的计算问题之一。这一问题可以描述为,根据某用户一段时期内的各种网络行为,将该用户映射到某个定向标签上。
1、行为定向建模问题
行为定向问题的目标是找出在某个类型的广告上eCPM相对较高的人群。如果假设在该类型的广告上点击价值近似一致,那么问题就转化为找出在该类型广告上点击率较高的人群。
2、行为定向特征生成
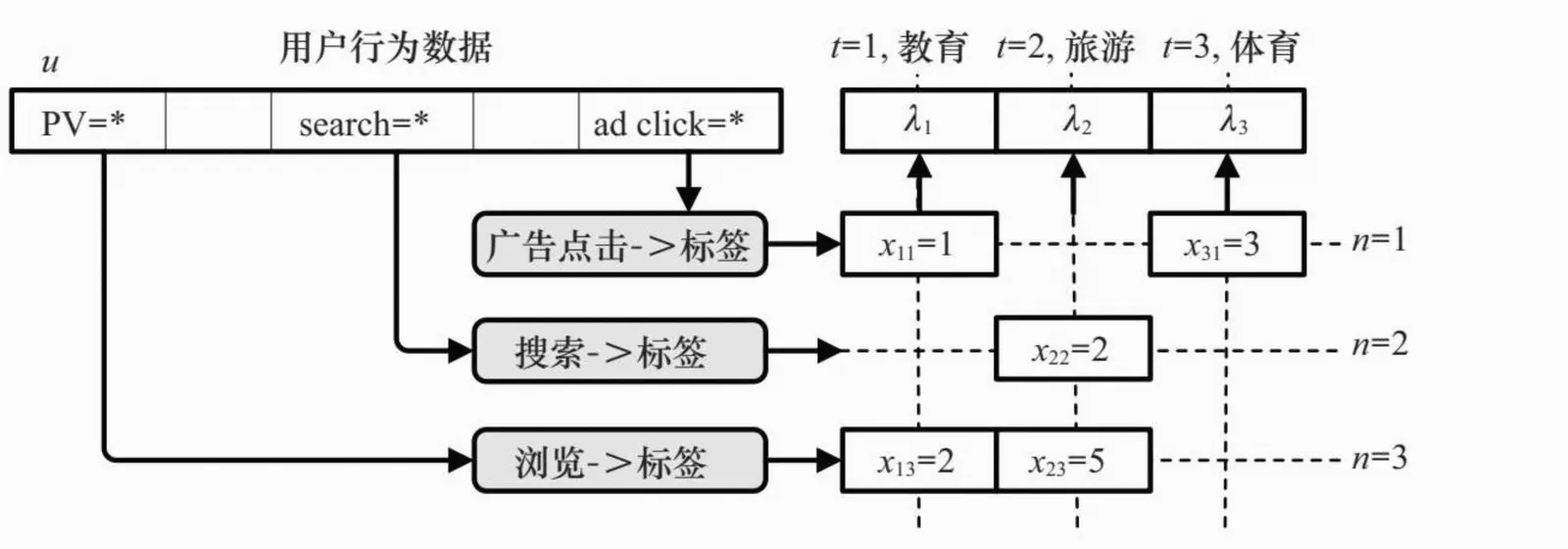
(1)网页浏览、分享等与内容相关的行为,可以通过有监督文本主题模型的方法,将其映射到预先定义好的标签体系上,也可以直接提取内容中的关键词作为标签。
(2)广告点击等与广告活动相关的行为,可以转化为对广告落地页内容的分析,因此可以使用与网页浏览相同的方法。
(3)最值得重视的是搜索、搜索点击等与查询相关的行为。由于查询的信息量较少,很难直接提取标签。可行的方案有两种,都要用到搜索引擎:第一种方案是利用搜索引擎做内容扩展,即将查询送入搜索引擎,用返回的若干结果描述或者链接页的内容作为该查询对应的内容,这种方案借助通用搜索引擎即可;第二种方案是对查询进行某垂直领域分类时,直接利用相应垂直媒体的标签体系和搜索引擎。
(4)转化、预转化等需求方行为,往往可以对应到一个单品。同样,利用该单品的分类信息,可以将其映射到某个标签上,而对于预转化中的站内搜索行为,可以按照上面的一般搜索行为来处理。
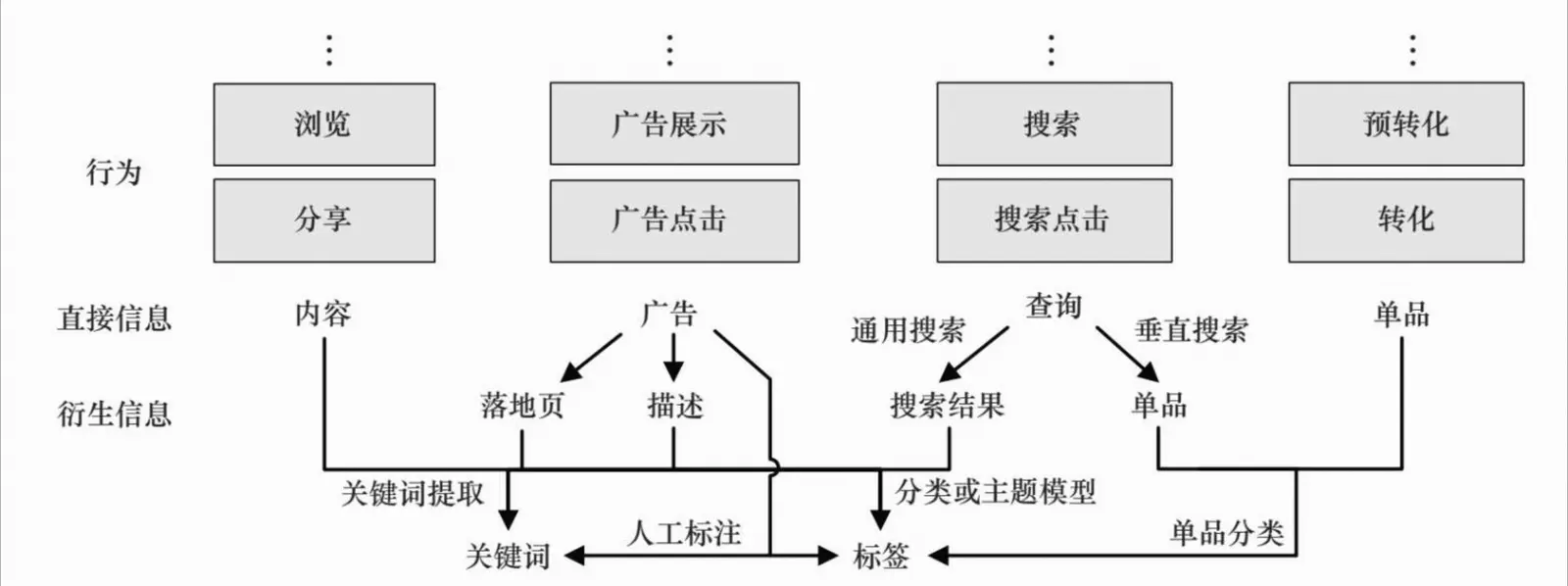
3、行为定向决策过程
在行为定向的决策过程中,不需要λ到h的泊松分布,只需要计算线性函数λ的值,然后根据预先确定的阈值来确定某个用户是否应该被打上某个定向标签。
4、行为定向的评测
一般来说,行为定向可以通过reach/CTR曲线来进行半定量的评测。在正常情况下,较小的人群规模应该较为精准,也即对该类型广告的CTR较高;而随着人群规模的扩大,该CTR也会逐渐走低。我们把标签接触到的人群规模称为reach,而这一reach和CTR构成的曲线是评价该标签上的定向是否合理,以及效果如何的重要依据。
五、人口属性预测
规模化地获得人口属性比较困难,因此我们往往还是需要数据驱动的模型,以用户的行为为基础自动预测其人口属性。
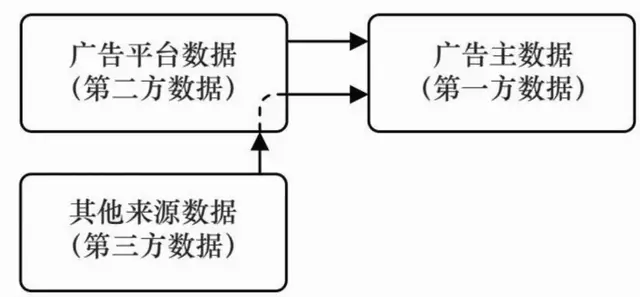
六、数据管理平台
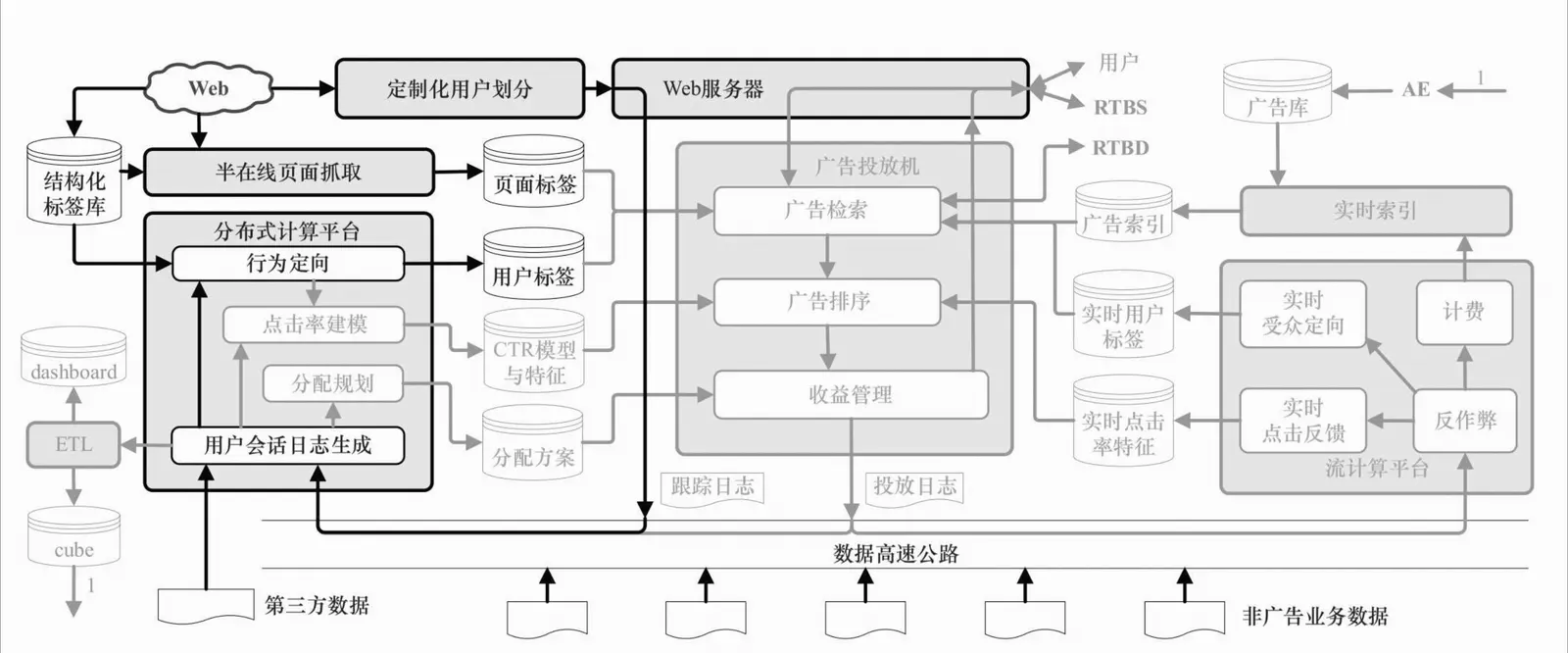
通过部署在媒体上的代码或SDK收集第一方访问日志,送入数据高速公路。同时通过数据高速公路收集自有的第二方数据,然后把这些日志原始行为映射到结构化或非结构化的受众标签体系上。另外,还会有一些第三方提供的加工好的标签数据直接进入用户标签集,再通过统一的接口对外提供。在这一架构中,DMP同时对接了第一方、第二方和第三方的数据,并根据这些数据对受众群体做灵活的、自定义的划分。虽然这些功能并不直接体现在广告交易环节中,却是数据驱动的在线广告中越来越重要的一环。