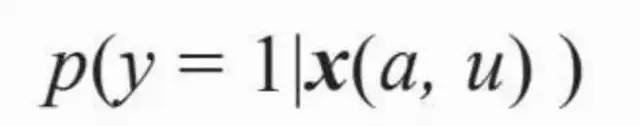计算广告关键技术1—计算广告技术概览(系统目标、架构、主要技术、开源工具)
2024-10
浏览量:276
本文字数:9040
读完约 31 分钟
在计算广告中,无论我们讨论的是产品还是策略,都与技术的关系十分密切。计算广告也是一个典型的个性化系统。不过由于复杂的市场交易结构、多样的数据来源以及预算带来的约束,计算广告是目前工业界遇到的个性化系统中比较复杂的,也是相对成熟的。
个性化系统与搜索系统都是互联网时代具有挑战性的大规模计算问题。由于数据规模的要求,它们一般都采用检索(retrieval)加排序(ranking)这样类搜索的系统架构,因而这两种系统有非常多的相似之处。
个性化系统与搜索系统的主要差别在于大量的用户特征的使用。由于需要对每一个用户进行刻画,这一过程需要用到大规模的分布式数据处理平台,如Hadoop;另外,由于个性化特征的效果与其生成的实时性关系很大,为了尽可能实时地利用线上数据,我们还会用到流计算平台来加工短时的个性化特征。将离线的分布式计算平台和在线的流计算平台相结合,已经成为这样的系统生成个性化特征的常用方案。
在互联网时代,要搭建这样一个五脏俱全的广告系统,实际上并没有看起来那么复杂。这里最关键的方法是要充分利用开源社区的成熟工具快速搭建系统框架,把底层通信、资源分配、集群管理、跨语言调度等与核心业务逻辑无关、但又有较高技术难度的部分用成熟方案来解决,这样广告系统的开发者就可以重点关注业务逻辑和核心算法了。
一、个性化系统框架
计算广告是根据个体用户信息投送个性化内容的典型系统之一,类似的系统还有推荐系统、个人征信系统、室内导航系统等。
一般的个性化系统由4个主体部分构成。
(1)用于实时响应请求,完成决策的在线投放引擎(onlineserving engine)。
(2)离线的分布式计算(distributed computing)数据处理平台。
(3)是用于在线实时反馈的流计算(stream computing)平台。
(4)连接和转运以上三部分数据流的数据高速公路(datahighway)。
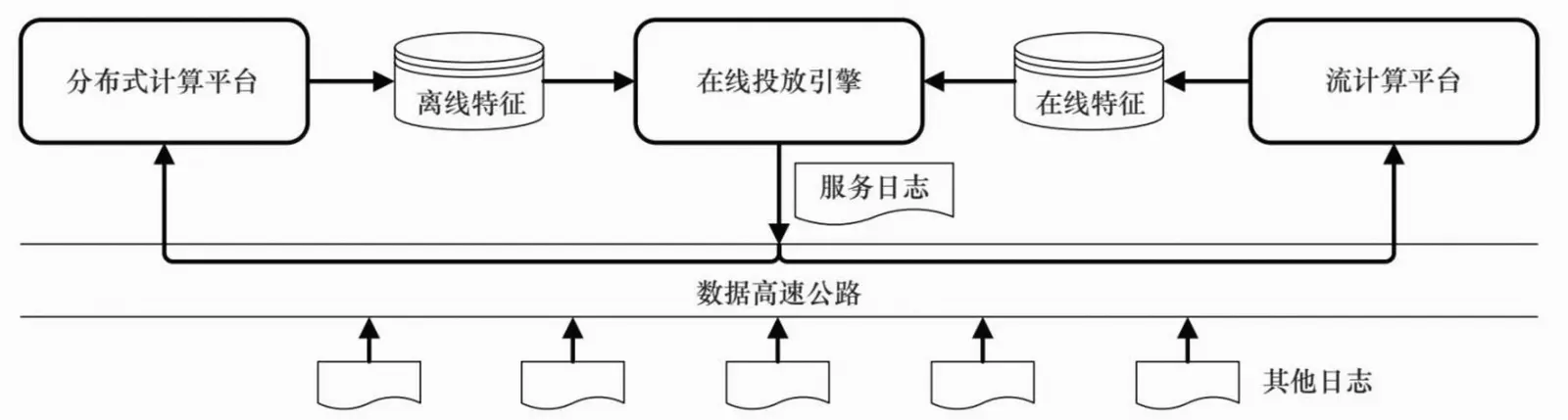
在线投放系统的日志接入数据高速公路,再由数据高速公路快速转运到离线数据处理平台和在线流计算平台;离线数据处理平台周期性地以批处理方式加工过去一段时间的数据,得到人群标签和其他模型参数,存放在缓存中,供在线投放系统决策时使用;与此相对应,在线流计算平台则负责处理最近一小段时间的数据,得到准实时的用户标签和其他模型参数,也存放在缓存中,供在线投放系统决策时使用,这些是对离线处理结果的及时补充和调整。
二、各类广告系统优化目标
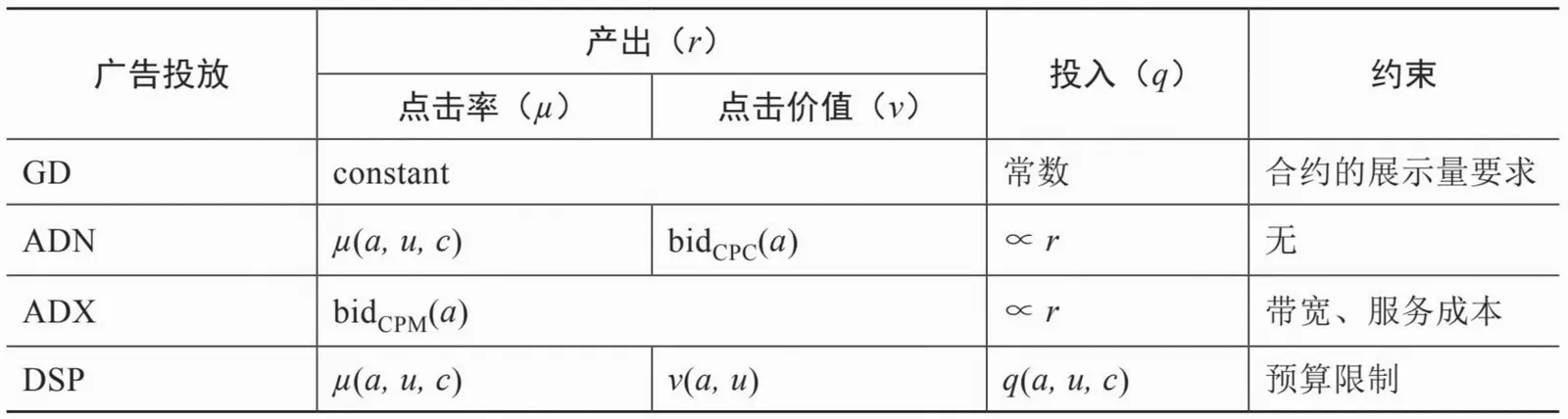
在展示量合约的GD系统中,只要各合约达成,系统的收益就是确定的,因此这一系统的主要优化在于满足各合约带来的约束,而成本由于是媒体静态产生,与广告优化过程无关,可以认为是常数;
ADN需要估计点击率µ(a,u,c),并与广告主出的点击单价bidCPC(a)相乘得到期望收入,而成本是与收入成正比的媒体分成;
ADX直接用广告主出的展示单价bidCPM(a)作为期望收入,成本也是与收入成正比的媒体分成;
在DSP中,点击率µ(a,u,c)、点击价值ν(a,u)和成本q(a,u,c)都可能是需要预估和优化的,因此算法的挑战较大。
三、计算广告系统架构
在实践中,广告系统的建立应该是循序渐进的。一般来说,对一个刚起步的广告产品,有广告投放机和相应的日志系统,实现简单的定向投放逻辑,就可以开始使用。随着对广告效果深入优化的需求,需要建立起完整的广告排序和用户行为反馈模型;而当中小广告主大量增加时,就需要实现广告的倒排索引和相应的检索功能。因此,在一个新的广告产品开始运营和逐步完善的过程中,要特别注意根据当前阶段的实际需求决定哪些模块是必要的,哪些可以暂时省略,以避免过度设计和不必要的投入。
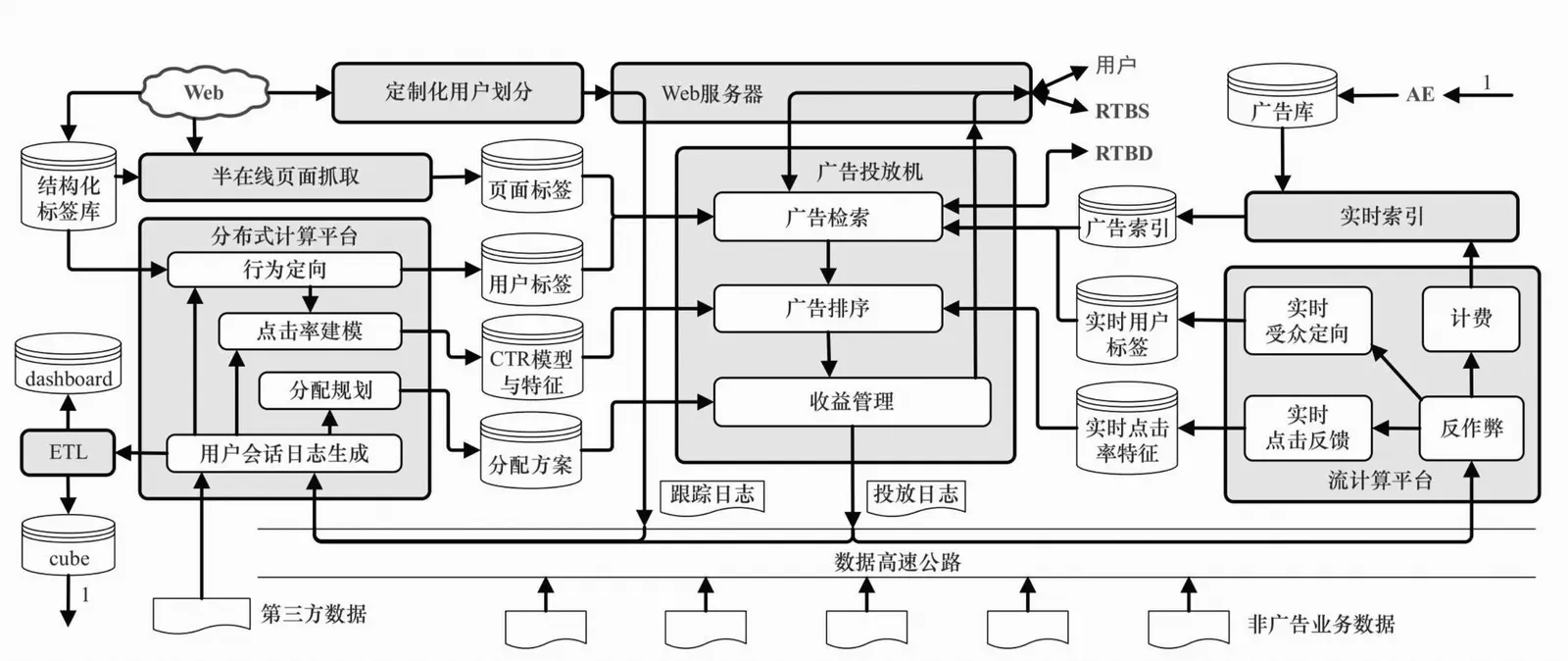
1、广告投放引擎
广告系统中必不可少的部分是实时响应广告请求,并决策广告的投放引擎。一般来说,广告系统的投放引擎采用类搜索的架构,即检索加排序的两阶段决策过程。另外,广告投放引擎还有一个独特模块,就是要从全局优化的角度对整体收益进行管理。
(1)广告投放机(ad server)。这是接受广告前端Web服务器发来的请求,完成广告投放决策并返回最后页面片段的主逻辑。广告投放机的主要任务是与其他各个功能模块打交道,并将它们串联起来完成在线广告投放决策。一般来说,为了扩展性的考虑,我们都采用类搜索的投放机架构,即先通过倒排索引从大量的广告候选中得到少量符合条件的或相关的候选,再在这个小的候选集上应用复杂而精确的排序方法找到综合收益最高的若干个广告。对广告投放机来说,最重要的指标是每秒数(Query per Second,QPS)以及广告决策的延迟(latency)。
(2)广告检索(ad retrieval)。这部分的主要功能是,在线时根据用户标签(user attribute)与页面标签(pageattribute)从广告索引(ad index)中查找符合条件的广告候选。实际上,倒排索引技术的重要性体现在所有Web规模的技术挑战上,也同样是大规模计算广告系统的基础。广告检索得到的候选将被送入广告排序模块。
(3)广告排序(ad ranking)。这部分是在线高效地计算广告的eCPM,并进行排序的模块。eCPM的计算主要依赖于点击率估计,这需要用到离线计算得到的CTR模型和特征(CTRmodel & feature),有时还会用到流计算得到的实时点击率特征(real-time feature)。在需要估计点击价值的广告产品(如按效果结算的DSP)中,还需要一个点击价值估计的模型。
(4)收益管理(yield management)。我们用这部分来统一代表那些在各种广告系统中将局部广告排序的结果进一步调整,以全局收益最优为目的做调整的功能,如GD系统中的在线分配、DSP中的出价策略等。这部分一般都需要用到离线计算好的某种分配计划来完成在线时的决策。
(5)广告请求接口。在实际系统中,根据前端接口形式的不同,广告请求可能来自于基于HTTP的Web服务器,也可能来自于移动App内的SDK或者其他类型的API接口。不过,无论是哪种接口,只要能够提供用户唯一的身份标识ID以及其他一些上下文信息,从逻辑上讲与标准的HTTP请求就没有本质区别,因此我们都用Web服务器来表示。程序化交易市场中的广告请求接口与上面有所不同,它包括作为需求方时使用的RTBS,以及作为供给方时使用的RTBD。这一接口可以采用IAB建议的OpenRTB协议,或者其他主要ADX规定的接口形式。
(6)定制化用户划分(customized audiencesegmentation)。由于广告是媒体替广告主完成用户接触, 那么有时需要根据广告主的逻辑来划分用户群,这部分也是具有鲜明广告特色的模块。这个部分指的是从广告主处收集用户信息的产品接口,而收集到的数据如果需要较复杂的加工,也将经过数据高速公路导入受众定向模块来完成。
2、数据高速公路
数据高速公路(data highway)完成的功能是,将在线投放的数据准实时传输到离线分布式计算平台与流式计算平台上,供后续处理和建模使用
3、离线数据处理
离线数据处理有两个输出目标:一是统计日志得到报表、仪表板等,供人进行决策时作为参考;二是利用数据挖掘、机器学习技术进行受众定向、点击率预估、分配策略规划等,为在线的机器决策提供支持。
(1)用户会话日志生成。从各个渠道收集来的日志,需要先整理成以用户ID为键的统一存储格式,我们把这样的日志称为用户会话日志(session log)。这样整理的目的是让后续的受众定向过程更加简单高效。
(2)行为定向。这部分的功能是完成挖掘用户日志,根据日志中的行为给用户打上结构化标签库(structural labelbase)中的某些标签,并将结果存储在用户标签的在线缓存中,供广告投放机使用。这部分是计算广告的原材料加工厂,也因此在整个系统中具有非常关键的地位。
(3)上下文定向。这部分包括半在线页面抓取和页面标签的缓存,这部分与行为定向互相配合,负责给上下文页面打上标签,用于在线的广告投放中。这里的抓取系统比搜索系统要简单,但也有不太一样的需求
(4)点击率建模。它的功能是在分布式计算平台上训练得到点击率的模型参数和相应特征,加载到缓存中供线上投放系统决策时使用。
(5)分配规划。这部分为在线的收益管理模块提供服务,它根据广告系统全局优化的具体需求,利用离线日志数据进行规 划,得到适合线上执行的分配方案(allocation plan)。
(6)商业智能系统。这部分包括ETL(extract-transform-load)过程、仪表板和Cube。这些是所有以人为最终接口的数据处理和分析流程的总括。因为它担负着对外信息交流的任务。由于实际的广告运营不可能完全通过机器的决策来进行,其间必然需要有经验的运营者根据数据反馈对一些系统设置做及时调整。
(7)广告管理系统。这部分是广告操作者,即客户执行(Account Execute,AE)与广告系统的接口。AE通过广告管理系统定制和调整广告投放,并且与数据仓库交互,获得投放统计数据以支持决策。
4、在线数据处理
在线数据处理的主要模块包括以下几个。
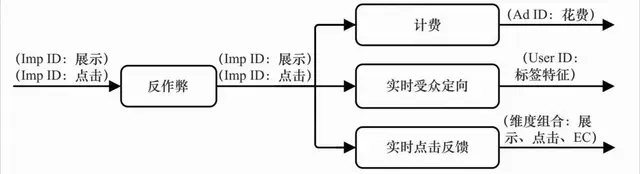
(1)在线反作弊。实时判断流量来源中是否有作弊流量,并且将这部分流量从后续的计价和统计中去除掉,是广告业务非常重要的部分。此模块是所有后续在线数据处理必须经过的前置模块。
(2)计费。这部分同样是计算广告关键的业务功能之一。对于那些经过扣费预算耗尽的广告,系统必须马上通知广告索引系统将其下线。当然,扣费也必须在扣除了作弊流量的基础上进行。
(3)在线行为反馈,包括实时受众定向和实时点击反馈等部分。这部分是将短时内发生的用户行为和广告日志及时地加工成实时用户标签,以及实时的点击率模型特征。对于在线广告系统,这部分对于效果提升的意义重大:在很多情形下,把系统信息反馈调整做得更快比把模型预测做得更准确,效果更显著。
(4)实时索引。这部分的主要功能是实时接受广告投放数据,建立倒排索引。广告的索引由于涉及预算调整等商业环节,因此必须在投放管理者调整以后非常快速地在线上广告索引中生效。
四、计算广告系统主要技术
从算法优化的角度看,主要有下面的一些问题,解决这些问题需要广泛用到机器学习、数据挖掘等一些相关学科的技术。
(1)特征提取,即对a,u,c打标签以方便后续建模和市场售卖的问题,是计算广告中非常核心的受众定向问题
(2)如果不考虑全局最优,则计算广告系统主要靠eCPM估计,特别是点击率预测来完成每一次展示时的局部优化
(3)如果考虑到量的约束和投放时即时决策的要求,则产生了在线分配的问题
(4)为了在多方博弈的市场中达到动态平衡时的收益最大化,则需要对市场的机制设计(mechanism design)做深入研究,进而确定合理的定价策略
(5)为了更全面地采样整个(a,u,c)的空间以便更准确地估计点击率,需要用到强化学习(reinforcement learning)中的探索与利用(Explore and Exploit,E&E)方法
(6)在实时竞价快速发展的今天,个性化推荐(personalized recommendation)技术也被广泛使用在效果类DSP的个性化重定向当中
系统架构方面涉及的技术问题有以下几个。
(1)由于广告主的预算、定向条件等信息在设置后需要快速在线上生效,我们需要用实时索引技术服务于广告候选的检索。
(2)需要用NoSQL数据库为投放时提供用户、上下文标签和其他特征。
(3)广泛使用Hadoop这样的Map Reduce分布式计算平台进行大规模数据挖掘和建模,也用到流计算平台实现短时用户行为和点击反馈。
(4)在广告交易市场中实现高并发、快速响应的实时竞价接口,这是一项广告中用到的独特技术。
五、用开源工具搭建计算广告系统
1、Web服务器Nginx
Nginx是一款开源服务器软件,兼有HTTP服务器和反向代理服务器的功能。其主要特点在于高性能、高并发和低内存消耗,并且具有负载均衡、缓存、访问控制、带宽控制以及高效整合各种应用的能力,这些特性使得Nginx非常适合计算广告这种并发很高的互联网服务。
Nginx还提供了fastCGI这一与各种编程语言之间的通信接口,开发者可以很方便地将服务器的功能逻辑用fastCGI插件的形式实现,而无须关注响应http请求的细节。在广告系统中,用Nginx作为前端Web服务器,而将广告投放机的功能用C/C++语言实现成fastCGI插件,是一个开发成本较低,性能又很不错的方案。实际上,这一方案已经实现了一个基本的广告投放机,从事最简单的广告投放业务,而其他模块和功能则可以根据需求逐步开发。
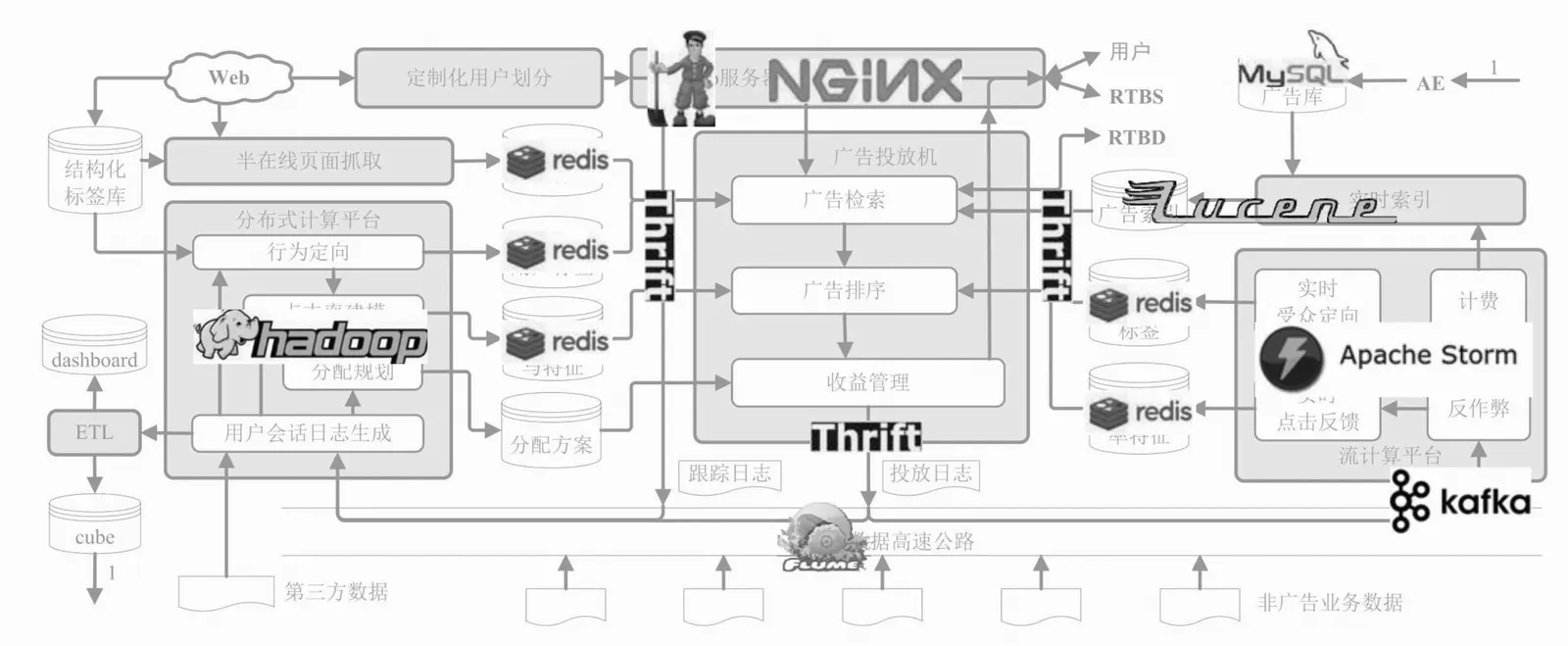
2、分布式配置和集群管理工具ZooKeeper
由于广告系统的流量很大,单台广告投放机往往不能满足需要。而在使用多台投放机的时候,会遇到很多诸如配置文件更新、集群上下线管理等分布式环境下的同步问题。ZooKeeper是解决这些问题非常有用的开源工具。
ZooKeeper是为分布式应用建立更高层次的同步(synchronization)、配置管理(configurationmaintenance)、群组(group)以及命名服务(naming)的通用工具。
在编程上,ZooKeeper的设计很简单,所使用的数据模型非常类似于文件系统的目录树结构,简单来说,有点类似于Windows中注册表的结构,有名称、树节点、键/值等,可以看成一个树形结构的数据库,可以分布在不同的机器上做名称管理。由于ZooKeeper并不是用来传递计算数据,而是用来传递节点的运行状态的,所以运行负载很低。
对广告投放机进行集群管理是ZooKeeper在广告系统中的典型应用之一:由于某台服务器宕机或者新机器上线,Nginx的负载均衡方案需要及时做出调整。显然,人工地维护响应时间较长,不可避免地会带来一些流量上的损失。利用ZooKeeper的Ephemeral类型节点,可以很方便地实现此功能。
由于在广泛使用的Hadoop、HBase、Storm、Flume等开源产品中都需要用到ZooKeeper进行分布式同步。如果把上述开源产品看成各种小动物,ZooKeeper(动物园管理员)这一命名可以说非常形象。
3、全文检索引擎Lucene
大多数广告业务在初始运营阶段,并不见得需要一个真正的倒排检索引擎。Lucene并不是一个完整的搜索引擎,但是针对计算广告系统的需要,它可以方便地实现全文索引(indexing)和检索(retrieval)功能。Lucene能够为文本类型的数据建立索引,其主要功能是替文档中的每个关键词建立索引。
Lucene还提供一组解读、过滤、分析文档,编排和使用索引的API。
在需要比较强的索引扩展性的情形下,还可以考虑使用Elasticsearch,它是一个基于Lucene构建的开源、分布式、RESTful搜索引擎。
4、跨语言通信接口Thrift
为了方便在不同语言的模块之间实现调用接口,避免应用开发者过多地将精力放在底层通信上,开源社区涌现了若干跨语言通信接口工具。我们以Thrift为例来介绍一下。
Thrift被描述为“scalable cross-language servicesimplementation”(可扩展跨语言服务实现),它有自己的跨机器的通信框架;此外,它还提供了一套代码生成工具,可以生成多种编程语言的通信过程代码。
Thrift有一种描述对象和服务的界面定义语言(Interface Definition Language,IDL),它提供了一种网络协议,使用这些对象和服务定义的进程之间基于这种网络协议彼此进行通信。Thrift根据IDL的描述,可以生成绝大多数流行语言(如C++、Java、Python、PHP、Ruby、Erlang、Perl、Haskell、C#、Cocoa、JavaScript等)的代码框架。因此,服务器端实现语言不会影响到客户端,这给复杂的计算广告技术平台不同系统之间的通信提供了很大的便利。
5、数据高速公路Flume
Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统,它支持在日志系统中定制各类数据发送方,用于分布式地收集和汇总日志数据。Flume提供了从控制台(console)、RPC(Thrift-RPC)、文本(text)、Tail(UNIX tail)、日志系统(syslog,支持TCP和UDP两种模式)、命令执行(exec)等数据源上收集数据的能力;同时,Flume还提供了对数据进行简单处理并输出到各种数据接收方的能力。如果广告投放机采用系统日志方式记录投放、点击等日志,可以很方便地通过配置Flume将日志传送到Hadoop上。
6、分布式数据处理平台Hadoop
Hadoop的核心架构主要包括Hadoop分布式文件系统(Hadoop distributed file system,HDFS、HadoopMapReduce和HBase,其中HDFS是Google文件系统(Google file system,GFS)的开源实现,MapReduce是Google MapReduce的开源实现,而HBase则是GoogleBigTable的开源实现。
HDFS是一种易于横向扩展的分布式文件系统,提供大规模数据文件存储服务,支持PB级数据规模。它可以运行在上万台的通用商业服务器集群上,提供副本容错机制,为海量用户提供性能优秀的存取服务。计算广告系统里的海量日志文件等就是通过Flume之类的数据高速公路传送,最终存储在HDFS上,为各种离线计算任务提供服务。
Hadoop MapReduce是一种分布式计算框架,顾名思义,它由map和reduce两个部分组成。map是将一个作业分解成多个任务,而reduce是将分解后多任务处理的结果汇总起来。在程序设计中,一项工作往往可以被拆分成为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执行;另一种是任务之间有相互依赖,先后顺序不能够颠倒,这种任务是无法并行处理的。MapReduce适用于第一种类型,庞大的集群可以看作是硬件资源池,将任务并行拆分,然后交由每一个空闲硬件资源去处理,能够极大地提高计算效率,同时这种资源无关性对于计算集群的横向扩展提供了最好的设计保证。为了降低MapReduce编程的复杂性,人们还开发了Hive、Pig等开源工具产品,使用类似于SQL的脚本语言来发起各种数据计算任务。
7、特征在线缓存Redis
无论是离线计算的受众定向标签还是点击率模型参数或特征,由于规模比较大,一般来说都无法直接存放在在线广告投放机的内存中,而是要用独立的缓存服务。
在线用到的特征缓存有两个显著的特点,首先是往往只需要存储简单的键/值对,其次是大多数情形下需要支持高并发的随机读和不太频繁的批量写。在这样的需求下,Redis是比较合适的开源工具之一。
Redis也是一种NoSQL数据库,它主要提供的是高性能的键值存储(key/value store),采用的是内存数据集的方式。
Redis的键值可以包括字符串(string)、哈希(hash)、列表(list)、集合(set)和有序集合(sorted set)等数据类型,因此也被称作是一款数据结构服务器(data structureserver)。Redis会周期性地把更新地数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了主从同步,具有非常快速的非阻塞首次同步、网络断开自动重连等功能。同时,Redis还具有其他一些特性,其中包括简单的check-and-set机制、pub/sub和配置设置等,使得它能够表现得更像缓存(cache)。Redis还提供了丰富的客户端,支持现阶段流行的大多数编程语言,使用起来比较方便。
8、流计算平台Storm
Hadoop能够处理的数据规模相当可观,但是处理的响应速度却很难保证。广告中需要用到流计算的问题包括在线反作弊、计费、实时受众定向和实时点击反馈等。
流计算的任务逻辑与MapReduce过程有些类似,熟悉Hadoop编程的读者也可以比较容易地在Storm上开发应用。不过要注意,流计算的任务调度原则和HDFS上的MapReduce是不同的:前者是调度数据,让数据在不同的计算节点间流动起来,而后者是尽可能调度计算以减少数据I/O。因此,流计算从本质上来讲并不是一个可以真正处理海量数据的框架,它的特长仍然在数据处理的响应速度上。
Storm保证每个消息都会得到处理,而且处理速度很快,每秒可以处理数以百万计的消息,并且可以使用任意编程语言来做开发。另外,Storm还可以直接部署在新一代的Hadoop计算调度引擎YARN上,这样可以非常方便地共享一个Hadoop集群的存储功能和计算资源。
9、高效的迭代计算框架Spark
Spark平台解决一些需要迭代计算的问题。用Hadoop进行大规模数据处理,在map和reduce两个阶段之间需要用硬盘进行数据交换,因此在需要面对多次迭代才能完成的任务时效率相当低。
由于这样的迭代计算任务在计算广告中很常见,如文本主题模型、点击率预估等,我们非常需要一种更适合于迭代计算的框架。
作为一种新型分布式计算框架,Spark的最大特点在于内存计算。Spark的计算模型可以更加精简地描述等价的MapReduce模型,另外由于Spark的数据共享基于内存,因而相对于基于硬盘的Hadoop MapReduce批处理计算,其性能有数量级的提升。此外,Spark可以在一套软件系统上支持多种计算任务,除了传统的Hadoop MapReduce所对应的批处理计算之外,还支持各种机器学习算法为代表的迭代型计算、流式实时计算、社交网络中常用的图计算、SQL关系查询、交互式即席查询等。这样,使用Spark就可以避免同时维护多套针对不同计算需求的系统,还可以避免不同系统之间的数据转储,大大减低了开发和运维成本。
虽然Spark可以在很多中等规模的迭代计算问题上有着非常优异的性能,但是由于大量数据的基础存储仍然要依赖于Hadoop,在两个集群之间调度数据成为高效处理数据的障碍。不过,与Storm一样,现在Spark也已经可以直接部署在YARN之上,以“Spark on YARN”的方式与Hadoop方便地共享集群的存储功能和计算资源。