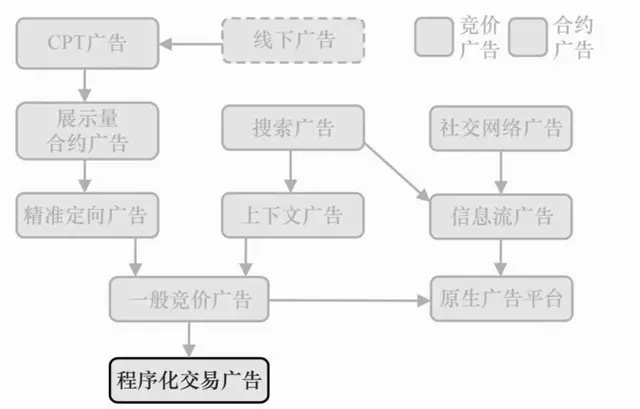
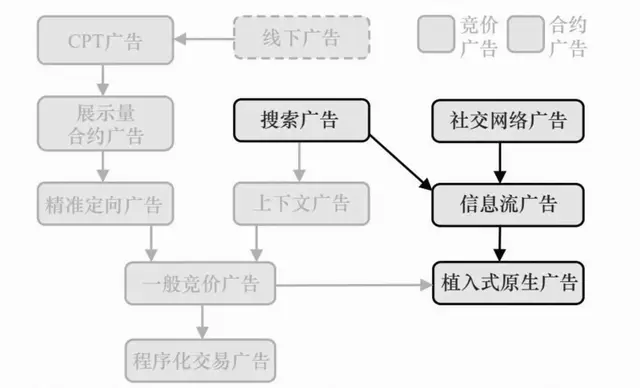
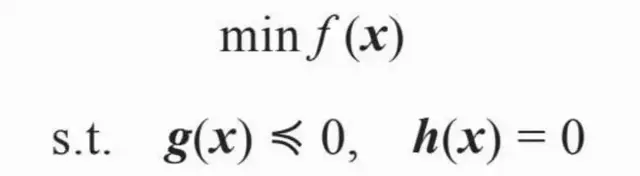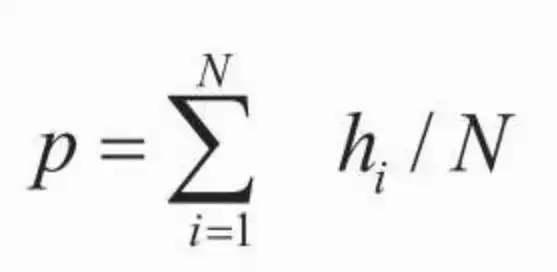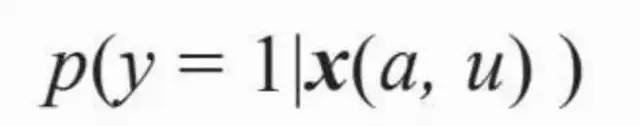计算广告关键技术5—竞价广告核心技术(索引、检索)
2024-10
浏览量:290
本文字数:4014
读完约 14 分钟
竞价交易是整个在线广告市场最关键的一次产品进化,它带来了广告技术的迅速发展。
在竞价广告中,大量中小广告主的检索规模使得对计算的效率要求很高,如何根据广告的业务要求设计更高效的索引和检索技术,是竞价广告系统一项通用的关键技术。
查询扩展可以看成是一个关键词推荐问题,但也需要考虑一些与广告领域相关的特点。
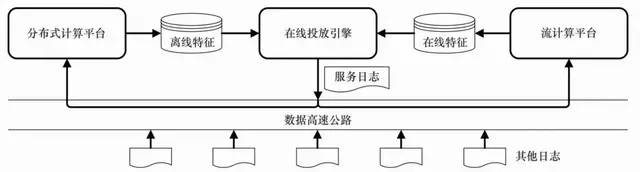
广告网络中的反作弊、计价等模块,需要将系统日志快速加工处理并反馈给线上决策系统。另外,对用户行为和点击的快速反馈对广告效果的提高帮助很大。这些准实时数据处理需求催生了流式计算平台。流计算技术与Hadoop等离线分布式计算技术相配合,可以更有效地完成计算广告中的数据处理任务。
竞价广告中另外一个重要的技术问题——点击率预估,由于在计算广告中的地位比较重要,也是利用数据和算法的核心环节之一
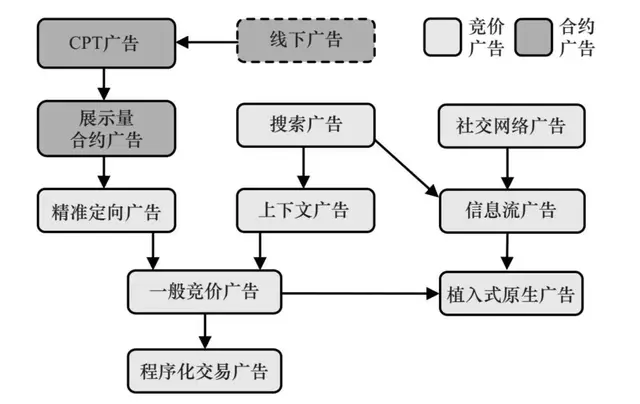
一、竞价广告计价算法
竞价广告中根据eCPM对广告进行排序,按照点击和转化两个发生在不同阶段的行为,eCPM可以分解成点击率和点击价值的乘积,eCPM的估计主要就是点击率预测和点击价值估计两个任务。
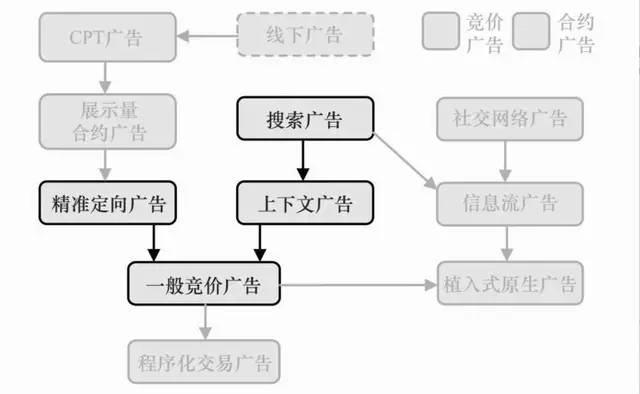
二、搜索广告系统
对每次展示的各个候选,根据查询估计其点击率µ,并乘以广告主出的点击单价得到eCPM,再按此排序即可。而在eCPM的估计过程中,根据上下文即用户输入的查询来决策。
搜索广告算法上最关键的技术是点击率预测,搜索广告还有一个技术上的重点,那就是查询词的扩展,即如何对简短的上下文信息做有效的拓展,由于搜索广告的变现水平高,这样的精细加工是值得而且有效的。
1、查询扩展
搜索广告中查询的重要性极高,粒度又非常细,如何根据广告主需求对关键词进行合理的拓展对于需求方和供给方来说都有很大意义:需求方需要通过扩展关键词获得更多流量;供给方则需要借此来变现更多流量和提高竞价的激烈程度。
基于推荐的方法
如果把用户一个会话(session)内的查询视为目的相同的一组活动,可以在{session,query}矩阵上通过推荐技术来产生相关的关键词。这种方法利用的是搜索的日志数据,而基本上个性化推荐领域的各种思路和方法都可以适用。
基于主题模型的方法
除了利用搜索的日志数据,也可以利用一般的文档数据进行查询扩展。这类方法实质上就是利用文档主题模型,对某个查询拓展出与主题相似的其他查询。
基于历史效果的方法
对搜索广告而言,还有一类查询扩展方法很重要,那就是利用广告本身的历史eCPM数据来挖掘变现效果较好的相关查询。由于在广告主选择竞价的关键词时,一般来说都会选择多组,如果从历史数据中发现,某些关键词对某些特定广告主的eCPM较高,那么应该将这些效果较好的查询组记录下来,以后当另一个广告主也选择了其中的某个关键词时,可以根据这些历史记录,自动地扩展出其他效果较好的查询。
2、广告放置
广告放置指的是搜索引擎广告中确定北区和东区广告条数的问题。考虑到用户体验,需要对北区广告的数量进行限制,因此,这是一个典型的带约束优化的问题。其中的约束是系统在一段时间内整体的北区广告条数,而优化的目标则是搜索广告系统的整体营收。在进行广告放置之前的排序过程中,比较的都是单条广告的eCPM,不过此处的优化需要处理一组广告,并且需要考虑位置因素。
搜索广告虽然不宜进行深入的个性化,但在广告放置问题上存在着很大的个性化空间。不同用户对于广告接受和容忍的程度有着很大的不同,实际上,即使在北美市场这样的用户受教育水平较高的市场上,也至少有三四成的用户不能完全分辨搜索结果和广告。因此,对不同的用户动态调整北区的条目数,可以使得在北区平均广告数目相同的约束下,整体系统的营收有显著的提高。
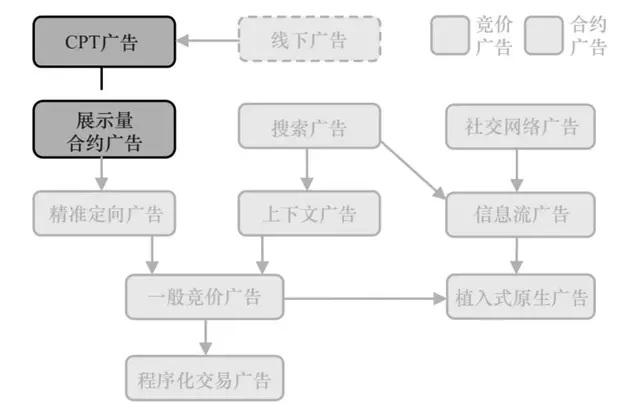
三、广告网络
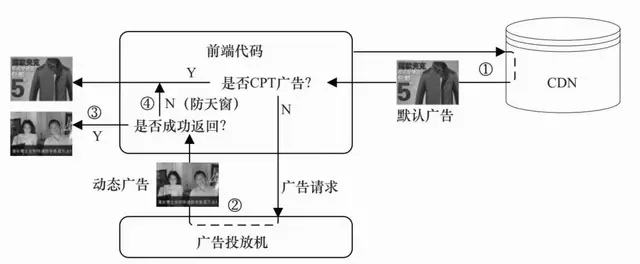
广告投放的决策流程为:服务器接收前端用户访问触发的广告请求,首先根据上下文信息和用户身份标识从页面标签库和用户标签库中查出相应的上下文标签和用户标签;然后用这些标签以及其他一些广告请求条件从广告索引中找到符合要求的广告候选集合;最后,利用CTR预估模型计算所有的广告候选的eCPM,再根据eCPM排序选出赢得竞价的广告,并返回给前端完成投放。
从离线计算的流程来看,广告网络需要根据广告投放的历史展示和点击数据,对点击率预测进行建模。当然,实际的广告网络也往往需要同时提供受众定向的功能,因此这部分离线计算也需要进行。
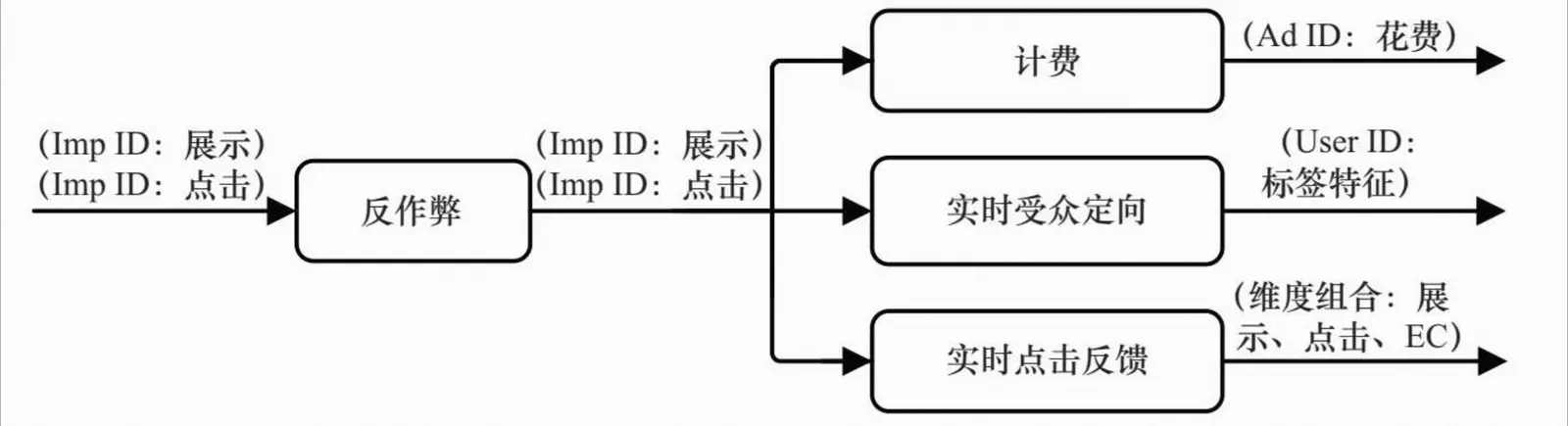
由于广告网络广泛采用CPC计费,准实时的计费和点击反作弊功能是必不可少的;另外,将用户行为尽快反馈到广告决策中对于点击率预估和受众定向的效果提升也非常关键。这些需求共同催生了流计算技术,这一技术被广泛应用于短时受众定向和短时用户行为反馈。
短时行为反馈与流计算
虽然用户行为定向不适用于搜索广告,但是用户在一个会话内的一系列查询如果能够快速处理,还是会对准确理解用户意图大有帮助。除了这样的短时用户行为反馈,在广告业务中还有一些需要快速对在线日志进行处理的场景,这些场景主要有以下几个。
(1)实时反作弊。反作弊是所有广告系统都需要的模块。在ADN、DSP这类依赖于站外流量的广告产品中,爬虫流量、突发的作弊流量都会对广告主预算产生巨大的影响。因此,在所有需要实时数据处理的模块之前,需要一个实时反作弊的模块,对系统产生的日志进行过滤。
(2)实时计费。广告产品需要一个实时计费的模块,以便将那些预算消耗完的广告及时下线,避免系统损失。
(3)短时用户标签。Hadoop上计算用户标签t(u)往往需要比较长的更新周期,如每天。而及时利用用户分钟级别的行为数据加工用户短时兴趣的标签,被证明对广告效果帮助很大。这种短时用户标签也需要一种数据准实时处理的工具。
(4)短时动态特征。CTR预测中的动态特征也可以根据分钟级的数据补充调整。
四、广告检索
大量中小广告主参与的竞价广告市场中,复杂的定向条件对检索技术提出了新的要求。倒排索引是搜索引擎的关键技术,而广告的检索上也采用这样的框架。
(1)广告的定向条件组合,可以看成是一个由与或关系连接的布尔表达式,这样的文档显然与搜索引擎面对的BoW文档不太一样,这里存在着有针对性的检索性能优化空间。
(2)在上下文关键词或用户标签比较丰富时,广告检索中的查询可能相当长,甚至会由上百个关键词组成,这种情况下的检索也与搜索引擎中主要由1~4个关键词组成的查询有很大区别。
1、布尔表达式的检索
广告检索与普通搜索引擎检索的第一个不同是布尔表达式的检索问题。在受众定向的售卖方式下,一条广告文档不能再被看成是BoW,而是应该被看成一些定向条件组合成的布尔表达式
2、相关性检索
搜索广告完全可以采用一般的检索技术,但是展示广告需要有新的方案。解决相关性检索的基本思路是,在检索阶段就引入某种评价函数,并以此函数的评价结果来决定返回哪些候选。评价函数的设计有两个要求:一是合理性,即与最终排序时使用的评价函数近似;二是高效性,即需要在检索阶段实现快速评价算法,否则就与在排序阶段对每个候选分别计算没有差别了。
3、基于DNN的语义建模
当一个概念由于用词和风格不同,在文档和查询中不是用同一关键词来表达时,基于关键词匹配的向量空间模型的泛化能力不足。后来流行起来的主题模型(如LDA)有一定的泛化性能,但无监督LDA不能够有针对性地解决具体问题。随着词嵌入方法在NLP领域的广泛应用,端到端地从原始文本中监督学习任务相关的语义表达,使语义的表达能力和准确程度都大幅提升,这也成为广告检索技术发展的前沿方法。
DSSM模型
在广告、搜索、推荐这些领域,经常用点击率作为弱监督标签来衡量给定用户(u)或上下文(c)与候选(a)的语义相关性。只不过在不同场景下c的含义略有不同:搜索场景下c是关键词,上下文广告场景下c以内容为主,而推荐场景则更多考虑u。
YouTube个性化推荐模型
在个性化推荐场景下,对查询用户u文档d既可以进行语义向量化,也可以采用词嵌入的思路,利用深度神经网络来解决。
YouTube的文章和DSSM的区别主要在网络结构的输入层,DSSM由于是解决信息检索领域中的文本语义相关性问题,特征的输入层主要由c和a文本做切词等处理构成,而受众定向广告中输入层是用户的历史行为,较为复杂
4、最近邻语义检索
最近邻检索的工程效率是一个核心问题:由于每个文档和查询都能够计算出一个距离得分,如果对所有文档完全遍历该得分,以语义向量200维、候选文档100万篇规模的数据集为例,检索过程可能要耗时数十毫秒,而这在高并发的在线广告场景下是不可接受的。因此,为了降低性能消耗,需要对候选文档数进行剪枝,同时又能保证较高的召回率,这类加速最近邻检索算法称为近似最近邻(Approximate Nearest Neighbor,ANN)查找。ANN算法有很多变种,以下3类较为典型,即哈希算法、向量量化算法及基于图的算法。
哈希算法
LSH的基本思想:原始数据空间中较近的样本点比较远的样本点在哈希后更容易碰撞,落在同一个桶中。因此,可以将在一个超大集合内查找相邻元素的问题,转化为在一个很小的桶内进行近邻查找的问题。
向量量化算法
向量量化(Vector Quantization,VQ)是一种对向量x做整体量化,将其映射为K个离散向量中的一个,从而压缩数据的算法。向量量化可以充分利用各分量间的统计依赖性,在维度高时要显著优于标量量化。在ANN场景中,即是通过压缩的方式来分治数据后加速查询。
基于图的算法
在ANN检索的场景中,基于复杂网络中的小世界网络这一图状结构相对于HKM有如下优势。
(1)检索时可以从任意节点开始访问,因此可以做高并发的并行检索。
(2)小世界网络可以通过相对较少的长程连接使大多数节点之间的联通路径有较短的长度。这意味着,能更快地找到与查询距离更近的相似数据。
NSW采用启发式的方法构建小世界网络,其核心思想非常简单。
(1)构建索引时,通过逐步插入节点去构造小世界网络,在构造网络的初始阶段建立的连接即成为最后相对较少的长程连接。
(2)查询索引时,从多个节点并发检索,直到检索出的top节点收敛,则结束检索。