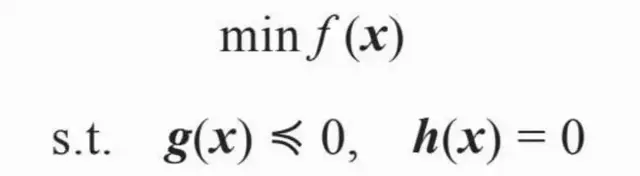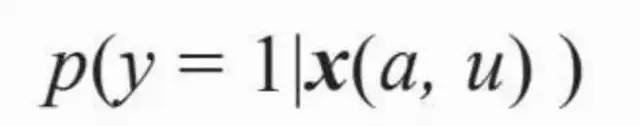计算广告关键技术6—点击率预测模型
2024-10
浏览量:261
本文字数:4988
读完约 17 分钟
广告点击率预测的目的是对检索后的广告候选进行排序。但是,我们不能简单套用搜索里的排序问题:点击率预测不能像搜索那样只要求结果排序的正确性,因为点击率需要乘以点击单价才能得到最后的排序。另外,在DSP这种产品中,需要尽可能准确地预测eCPM,用于出价。因此,作为各种广告系统中通用的一项技术,点击率预测更适合建模成回归(regression)问题而不是排序(ranking)问题。
经典的点击率预估模型以前以逻辑回归为主,逻辑回归的求解以前以批处理更新方式为主,主要是在MPI或Hadoop上采用LBFGS、置信域等优化算法求解。这一方式的优点是,因为其对历史样本做全局优化,所以对于长尾流量较多的场景(如展示广告)往往预估得比较精细。但这种方式的缺点也较为明显,模型不能够快速更新,在实时性较高的场景难以快速捕捉信号变化。于是,在此类场景中,往往采用在线的方式(如FTRL等)去更新模型,对头部数据和新数据的学习会更快。
一、点击率预测
1、点击率基本模型
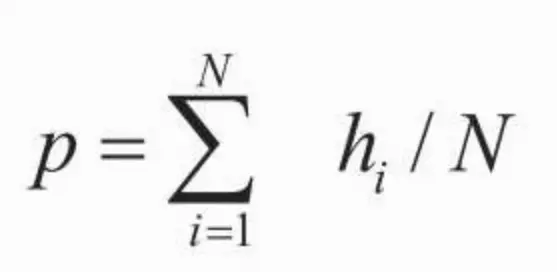
其中hi是表示第i次展示被点击的次数,一般情形下为0或者1。但是,如果某种(u,c)组合的情形下,广告a没有被展示过或点击量很稀疏,就无法通过历史数据来统计点击率了。容易想到的解决方案,是将要展示的广告a和一个展示过的广告a'类似,则可以预估a的点击率与a'接近。如果将(a,u,c)投影到特征空间做比较,则演化为即将介绍的点击率模型。
我们把点击事件h看成一个二元取值的随机变量,那么其取值为真(h=1)的概率就是点击率。因此,点击事件的分布可以写成以点击率µ为参数的二项式分布。
而点击率预测模型的作用,是在(a,u,c)组合与点击的概率µ之间建立函数关系,这可以表示成对µ(a,u,c)=p(h=1|a,u,c)的概率建模问题,我们很自然可以想到的基础模型是逻辑回归
2、LR模型优化算法
L-BFGS
在目标函数可导的一般优化问题中,拟牛顿法是一族最常用的方法,因此也可以直接应用于LR问题的求解。
置信域法
除了L-BFGS,置信域法也被证明对求解LR问题很有效,而且往往可以更快地收敛。不过,在点击率预测的问题中,同样因为模型的维数可能很高,直接用来解置信域的子问题仍然是不现实的。
Spark上的模型优化
由于map将训练数据从磁盘读入时产生大量I/O,所以在Hadoop平台上进行一次迭代的代价非常高。单轮迭代时间无法优化,想降低模型训练的时间只能减少模型训练的迭代数,这就产生了以上所说的工业界常用的模型训练思路。
(1)降低模型训练次数,通过特征侧的方法来捕捉信号的快速变化。
(2)增量求解,降低模型收敛所需的迭代轮数。
(3)精心设计最优化算法如ADMM,降低模型收敛所需的迭代轮数等。
3、点击率模型的校正
点击率预测问题有一个数据上的挑战,就是正例和负例样本严重不均衡,特别是在展示广告点击率只有千分之几的情况下。在很多建模方法中,这样严重的不均衡会带来模型估计上的问题。所幸消除这一点击率估计的偏差并不十分困难,实际上对此偏差的系统性分析可以上升到广义线性模型的层次来研究。
4、点击率模型的特征
从受众定向得到的所有t(a,u,c)以及这些特征的运算,可以组合出大量的特征供模型选择,这是大多数机器学习问题共同的方法。
点击率预测问题的主要挑战在于,如何使模型能捕捉高度动态的市场信号,以达到更准确预测的目的。这一挑战可以用在线的模型学习算法,或者用快速更新的动态特征来解决,从方法论上说,这两种思路是对偶的
特征的非线性化
LR模型本质上是一个线性模型,因为无法直接对信号与特征的非线性关联进行建模,所以只有在特征工程里进行考虑。将特征离散化或者进行非线性变换,基本已成为点击率建模中的标准步骤。
组合特征与静态特征
由于组合特征的存在,可选的特征总量巨大,对应的模型维度也非常高。直接生成所有可能的单维度特征和组合特征,选取出现频次在一定阈值以上的,将其作为LR模型的特征集合。这样的特征称为静态特征,这是广告点击率模型特征生成的基本方法。显然,静态特征都是取值为0或1的特征。
动态特征
当某个组合特征被触发时,我们不再用1,而是采用这个组合历史上一段时期的点击率作为其特征取值。这样一来,即使是同一个t(a,u,c),在不同的时间点,其所对应的特征取值也是不同的,这样的特征就是动态特征。
使用动态特征的另一个好处是可以大大减少模型的参数数目:对于{geo(c)=北京&&category(a)=电商}和{geo(c)=北京&&category(a)=日化}这两个特征组合的具体实例而言,如果采用静态特征方案,需要对这两个实例分配不同的特征号;而采用动态特征方案时,由于它们等号前的部分都相同,因此可以在模型中共享同一个特征参数,而通过不同实例的不同特征取值来分辨它们。
位置偏差与CoEC
使用动态特征在实际操作中还会碰到一些困难,特别是当广告主数量不充分的时候。假设某广告网络有两个广告位,一个是某网站首页首屏,另一个是某网站内容页最下端。很显然,如果用点击率作为直接的反馈,前几天更多地投在第一个广告位的广告会表现出更好的效果,而这主要是由于位置带来的偏差。
除了广告位位置,还会有其他一些非定向因素对点击率有比较大的影响,主要有广告位尺寸、广告位类型(如门户首页、频道首页、内容页、客户端)、创意类型(如图片、Flash、富媒体)、操作系统、浏览器、日期和时间等。所有这些因素,都与广告决策没有关系,但是对点击率的影响要远远超过定向技术带来的影响。因此,在这些因素上占据优势的广告,其点击率会被严重高估,如果直接用点击率作为反馈,也会造成强者愈强的马太效应。
在考虑多个因素共同作用或广告环境比较复杂的情况下,可以采用从数据中近似地学习出期望点击的方法。该方法概念上很简单,只用那些偏差因素作为特征,训练一个点击率模型,这个模型称为偏差模型(biasmodel)
采用动态特征和偏差模型的工程方案,点击率预测模型训练的 流程分3步完成:首先,用较长一段时间的训练数据,只提取偏差特征并训练偏差模型;然后,利用得到的偏差模型计算所需维度组合上的CoEC作为动态特征;最后,用所有非偏差的动态特征训练整体点击率模型,其中用偏差模型的输出作为点击率的先验。
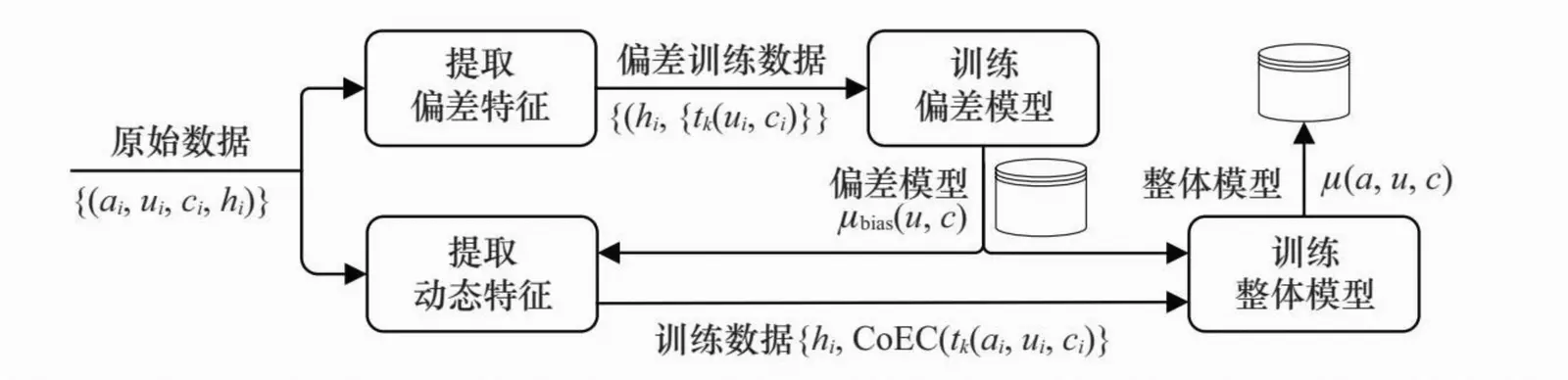
常见的偏差特征
(1)广告位位置。位置的影响在搜索广告和展示广告环境下有一定的区别。而对于展示广告,特别是在广告网络环境下的展示广告,位置的可能性非常多,因此不可能将每种不同的位置都作为独立的变量来考虑。比较合理的方法是找出重要影响因素,如广告位中心相对于页面左上角的坐标,用这样的连续变量作为特征来训练偏差模型。
(2)广告位尺寸。尺寸的情形与上面说的位置因素很类似:在创意尺寸选择比较少的情况下,可以作为离散变量来处理;而在尺寸选择很多的情况下,也可以用长宽等连续变量来代替。
(3)广告投放延迟。广告完成决策逻辑并将最终结果返回给用户的整体时间长短,对点击率有着非常大的影响。
(4)日期和时间。工作日还是周末,对不同类型的广告(如游戏)点击率有着明确的影响,这主要是由于在不同时间用户任务的集中程度不同,对广告的关注也有所区别。
(5)浏览器。浏览器本身并不对广告效果有明确的影响,不过由于各个浏览器上AD Blocker的覆盖程度有较大区别,因此在实际建模中其影响也相当大。
点击反馈的平滑
用CTR或CoEC这样的点击反馈作为动态特征,大量的长尾组合特征对于准确地预测点击率有很大帮助。但是要利用好这些长尾组合特征,还需要解决一个问题,就是在统计不足的维度组合上如何稳健地统计CTR或CoEC。
5、点击率模型评测
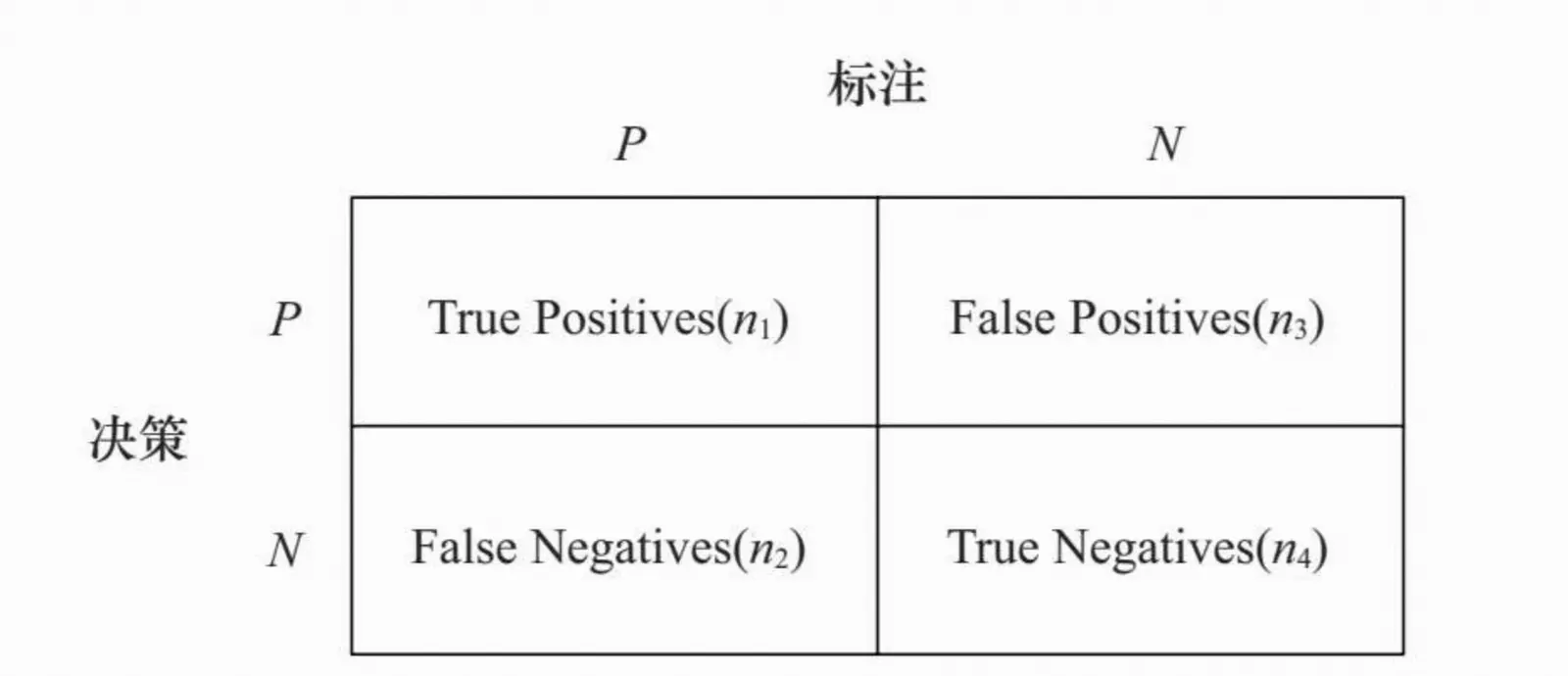
点击率模型预测的是点击事件出现的概率,因此可以采用准确率/召回率(Precision/Recall,PR)曲线或接收机操作特性(Receive Operating Characteristic,ROC)曲线来评测。
(1)点击行为被预测为点击行为,其数目计为n1。
(2)点击行为被预测为非点击行为,其数目计为n2。
(3)非点击行为被预测为点击行为,其数目计为n3。
(4)非点击行为被预测为非点击行为,其数目计为n4。
对广告而言,我们应该更加关注PR曲线的头部,因为尾部是Recall比较高,也就是很多广告候选都被考虑时的情形,而实际的投放环境中,我们只选择排名最好的一个或几个候选。另外一点需要注意的是,PR曲线下面的面积是没有明确的物理意义的,因此不能作为有价值的指标来衡量。
6、智能频次控制
在品牌广告和效果广告两种情况下,智能频次控制的做法也有所不同:在效果广告中,可以将EC的计数或者频次的计数作为点击率预测模型的特征直接加入训练,靠点击率模型的作用降低出现频次过高的创意的竞争力;在品牌广告中,可以通过EC计数上的直接控制来达到一定用户接触程度的目的,由广告主来直接设定。
竞价广告精细的效果要求让我们认清了频次的本质:它与其他影响点击率的特征是平等的,并且应该放在统一的、数据驱动的计算框架下加以利用。而究竟对某个创意应该将频次控制在多少,也不应该是根据经验设定,而是应该放在竞价的环境中自行决定。
二、其他点击率模型
1、因子分解机
由于LR这种基线模型本质上是一种线性模型,需要人工设计和加入组合特征来描述特征之间的共现关系。不过,这样一来特征的数目就会急剧上升,从而带来参数数目的上升,这给求解和防止过拟合都带来了不小的挑战。如何才能既充分描述特征之间的共现关系,又避免维度灾难的发生呢?因子分解机(Factorization Machine,FM)这种模型就是实践中有效的方法之一。
2、GBDT
GBDT的全称为Gradient Boosted Decision Trees,是一种以决策树为基本学习器的Boosting算法,它是1999由JeromeFriedman提出的。将GBDT应用于点击率建模最早见于Yahoo!基于MapReduce和MPI的分布式GBDT方案,另外也有Facebook以GBDT的输出作为LR模型的输入的方案。相对于LR模型,GBDT能更好地处理连续值特征,可以自动进行特征选择,最终产出的树模型的可解释性也较好。近年来,xgboost又对GBDT的理论和工程效率做了一定改进,在Kaggle上,针对中小规模数据集的监督学习问题几乎成了必备。不过,GBDT的缺点也较为明显:建树过程不能并行化,建树过程中枚举特征分割点的过程也不太适合高维稀疏特征,需要将特征降维成稠密的数值特征(如COEC等)。
3、深度学习点击率模型
因为利用深度学习方法来解决点击率建模问题能够在复杂的特征组合中自动挖掘其间的非线性关系,所以它也是今天广受瞩目的方法。
三、探索与利用
1、强化学习与E&E
在实际的广告场景下,决策行为更像是一个多状态的行为序列。在多个决策行为不独立且需要优化决策序列的整体收益的场景下,贪婪地每次选择短期收益最大的决策往往并不是最优解。在强化学习领域,会把问题建模成一个智能体(agent)和环境(environment)多轮交互的模型。
强化学习大致分为两种模型:一种是基于策略的模型,直接搜索能够最大化未来奖励的策略;另一种是基于价值的模型,直接对值函数Q建模,然后遍历出预估Q值最高的动作。伴随着强化学习和深度学习的融合,在围棋对弈、无人驾驶等领域都取得了不错的表现。
强化学习主要的挑战,正是如何在探索(exploration)与利用(exploitation)之间获得最优的平衡。在广告中,需要牺牲一部分流量上eCPM最优的策略,采用相对随机的策略来采样那些效果未知的特征空间,这就是探索过程;再根据探索和正常决策的总体流量更有效地预测点击率,这就是利用过程。
2、UCB方法
MAB问题经典的思路是置信上界(Upper ConfidenceBound,UCB)方法。此方法的原理是,在每次投放时,不但简单地选择经验上最优的广告,而且考虑到经验估计的不确定性,进而选择估计值有可能达到的上界最大的那个广告。
3、考虑上下文的bandit
对于需要探索的空间过大的问题,工程上比较常用的思路是将此空间参数化,在一个维数较低的连续空间中进行探索。这样的E&E问题,可以称为考虑上下文的bandit(contextualbandit)问题。注意这里说的“上下文”,不同于上下文定向中提到的上下文,是指根据(a,u,c)组合参数化后的上下文空间 位置。