Hive中Sort By、Distribute By语法使用方法
2024-10
浏览量:240
本文字数:1261
读完约 5 分钟
Order By(全局排序)
Sort By(每个reduce内部排序)
Distribute By(指定分区规则)
Cluster By(分区字段和排序字段相同时使用)
Order By(全局排序)
Order By 用于结果集的排序。也可以称之为全局排序。对于 MR 任务来说,如果我们使用了 Order By 排序,意味着MR 任务只会有一个 Reducer 参与排序。
在 Hive 中执行脚本时,我们可以通过 set mapreduce.job.reduces = 10 来设置 reduce 的个数为 10。但只要使用了 Order By 排序,即使设置了 10 个reduce ,也是不会生效的。Order By 就是一个全局排序,只能用一个 Reduce 进行全局排序。
注意:
在公司中,order by 是不建议使用的,效率太低了!!!在数据特别少时可以使用。生产环境中数据过多,放一个reducer中排序,一般一个reducer是根本跑不成功的,会报错。下文我们会对 order by 进行优化,即引入sort by、distribute by 等。
Hive 中可以针对 order by 设置使用模式,严格模式(即hive.mapred.mode = strict)下,只要使用了 order by,在运行时就会直接报错的,order by子句必须后跟一个 limit 子句。如果将hive.mapred.mode设置为非限制,则不需要限制子句。原因是为了强加所有结果的总顺序,必须有一个redcue对最终输出进行排序。如果输出中的行数太大,则单个还原器可能需要很长时间才能完成。
Hive 中不允许使用order by,需要添加相应配置。后面会有配置。
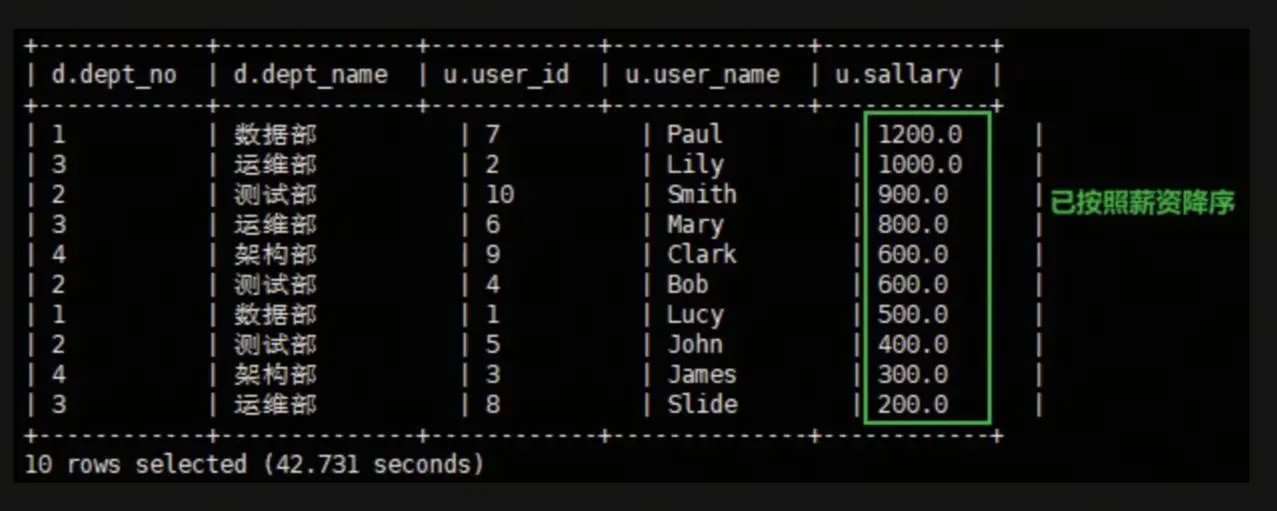
select d.dept_no, d.dept_name, u.user_id, u.user_name, u.sallary from dept_info d join user_info u on d.dept_no = u.dept_no order by u.sallary desc;
Sort By(每个reduce内部排序)
Sort By:对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排序,此时可以使用 sort by。Sort by 在每个 Reducer 内部进行排序,即使每个 reduce 内部是有序的,但是对于全局结果集 来说也还是乱序的。
Hive 任务需要使用几个 reduce ,完全取决于任务。Hive 默认 reduce 配置 mapreduce.job.reduces=-1,可以手动配置。设置2个reduce运行,set mapreduce.job.reduces=2,根据部门编号 dept_no ,采用默认分区规则,示例如下:
设置2个reduce执行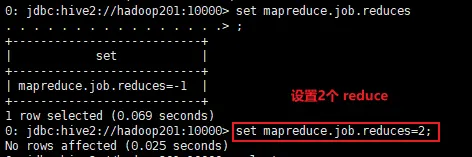
select user_id, user_name, dept_no, sallary from user_info sort by dept_no desc;
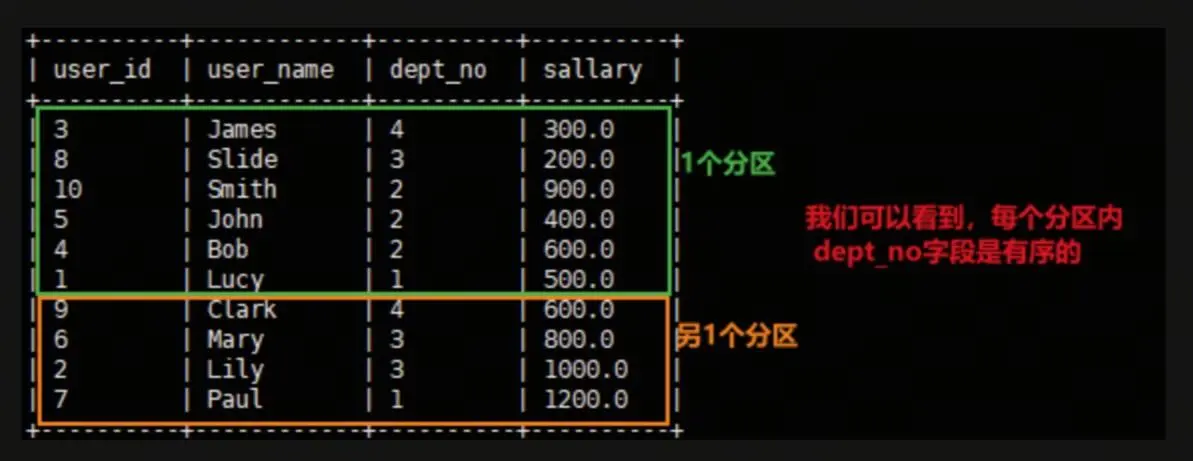
通过 select xxx from xxx sort by deptno desc; 将结果全部打印出来,通过上图,可以猜测前6条数据在1个分区,后4条数据在另1个分区。我们也可以通过 insert 导出查询结果的方式,查看每个分区具体的内容。